Vous aimerez peut-être aussi
- BB ImagesDocument4 pagesBB ImagesnishaPas encore d'évaluation
- Practical No06 (2-3)Document5 pagesPractical No06 (2-3)nishaPas encore d'évaluation
- Practical No.10Document6 pagesPractical No.10nishaPas encore d'évaluation
- Asp PDFDocument103 pagesAsp PDFAmol AdhangalePas encore d'évaluation
- Practical No.04 (Mam)Document5 pagesPractical No.04 (Mam)nishaPas encore d'évaluation
- Use analysis tools to calculate distances and select featuresDocument5 pagesUse analysis tools to calculate distances and select featuresnishaPas encore d'évaluation
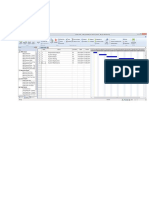
- Gantt ChartDocument1 pageGantt ChartnishaPas encore d'évaluation
- OOP ProgramsDocument23 pagesOOP Programsnisha0% (1)
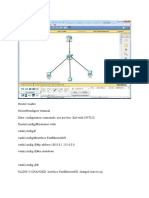
- Ospf Pract (IT)Document2 pagesOspf Pract (IT)nishaPas encore d'évaluation
- I.T PracsDocument76 pagesI.T PracsnishaPas encore d'évaluation
- Telnet Pract (IT)Document4 pagesTelnet Pract (IT)nishaPas encore d'évaluation
- Online Medical Shop ManagementDocument65 pagesOnline Medical Shop ManagementnishaPas encore d'évaluation
- Telnet Pract (IT)Document4 pagesTelnet Pract (IT)nishaPas encore d'évaluation
- Use analysis tools to calculate distances and select featuresDocument5 pagesUse analysis tools to calculate distances and select featuresnishaPas encore d'évaluation
- Practical No. 1: System Requirement Study (SRS) For A ProjectDocument44 pagesPractical No. 1: System Requirement Study (SRS) For A ProjectnishaPas encore d'évaluation
- Practical 1Document213 pagesPractical 1Shreeya ShirkePas encore d'évaluation
- Practical No.2Document20 pagesPractical No.2nishaPas encore d'évaluation
- ICLES' Motilal Jhunjhunwala College of Arts, Commerce & ScienceDocument4 pagesICLES' Motilal Jhunjhunwala College of Arts, Commerce & SciencenishaPas encore d'évaluation
- Practical No.10Document6 pagesPractical No.10nishaPas encore d'évaluation
- ICLES' Motilal Jhunjhunwala College of Arts, Commerce & ScienceDocument4 pagesICLES' Motilal Jhunjhunwala College of Arts, Commerce & SciencenishaPas encore d'évaluation
- Practical No.07Document9 pagesPractical No.07nishaPas encore d'évaluation
- Practical No.07Document9 pagesPractical No.07nishaPas encore d'évaluation
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (119)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Louis I KahnDocument27 pagesLouis I KahnKiran BasuPas encore d'évaluation
- Stars 1.06Document22 pagesStars 1.06ratiitPas encore d'évaluation
- FedVTE Training CatalogDocument13 pagesFedVTE Training CatalogCalebWellsPas encore d'évaluation
- Example. A Reinforced Concrete Spandrel Beam Has Overall Dimensions of 250 X 460 and Is JoinedDocument4 pagesExample. A Reinforced Concrete Spandrel Beam Has Overall Dimensions of 250 X 460 and Is JoinedJames NeoPas encore d'évaluation
- Koolair Technical Selection GuideDocument145 pagesKoolair Technical Selection GuideManojPas encore d'évaluation
- 354 33 Powerpoint-Slides CH9Document44 pages354 33 Powerpoint-Slides CH9Saravanan JayabalanPas encore d'évaluation
- Dywidag Threadbar Properties - Dywidag Threadbar - Reinforcing Steel Hardware DimensionsDocument1 pageDywidag Threadbar Properties - Dywidag Threadbar - Reinforcing Steel Hardware DimensionsMangisi Haryanto ParapatPas encore d'évaluation
- Trans-Architecture, de Tim GoughDocument16 pagesTrans-Architecture, de Tim GoughClevio RabeloPas encore d'évaluation
- The Humanizing of ArchitectureDocument4 pagesThe Humanizing of ArchitectureRafaelaAgapitoPas encore d'évaluation
- Telit WE866C3 Datasheet-1Document2 pagesTelit WE866C3 Datasheet-1SailajaUngatiPas encore d'évaluation
- Left Elevation: Upper Roof DeckDocument1 pageLeft Elevation: Upper Roof DeckWilmer EudPas encore d'évaluation
- 72PR01 Pipe RakDocument15 pages72PR01 Pipe RakSalam FaithPas encore d'évaluation
- Mangalore Zonal RegulationsDocument56 pagesMangalore Zonal RegulationsChethan100% (1)
- Woodworks Design Example - Four-Story Wood-Frame Structure Over Podium SlabDocument52 pagesWoodworks Design Example - Four-Story Wood-Frame Structure Over Podium Slabcancery0707Pas encore d'évaluation
- Advance Cloud Computing STTPDocument2 pagesAdvance Cloud Computing STTPBhushan JadhavPas encore d'évaluation
- Practical-1: CPU (Central Processing Unit)Document33 pagesPractical-1: CPU (Central Processing Unit)programmerPas encore d'évaluation
- Zigbee Technology: "Wireless Control That Simply Works.": Submitted byDocument24 pagesZigbee Technology: "Wireless Control That Simply Works.": Submitted byAnonymous nNyOz70OHpPas encore d'évaluation
- ISA 100 11a Wireless Standards For Industrial Automation 2009 PDFDocument817 pagesISA 100 11a Wireless Standards For Industrial Automation 2009 PDFPhilippe DemontrondPas encore d'évaluation
- Soft Landscape WorksDocument63 pagesSoft Landscape Worksbadhusha100% (3)
- Report1 - Study of Structural System in Architecture - Post Lintel - 5,10,15,20,24,29Document81 pagesReport1 - Study of Structural System in Architecture - Post Lintel - 5,10,15,20,24,29নূরুন্নাহার চাঁদনী100% (1)
- Pilhofer CuratorDocument14 pagesPilhofer CuratorcastiánPas encore d'évaluation
- Globe Product List with Prices and Validity PeriodsDocument2 pagesGlobe Product List with Prices and Validity PeriodsGM Alisangco JarabejoPas encore d'évaluation
- Project Title:: Checklist For PlasteringDocument2 pagesProject Title:: Checklist For Plasteringalfie100% (6)
- Ds ChecklistDocument2 pagesDs ChecklistG-SamPas encore d'évaluation
- Chapter 4 Heat Exchangers With High-Finned Trufin TubesDocument0 pageChapter 4 Heat Exchangers With High-Finned Trufin TubesManuel ArroyoPas encore d'évaluation
- Sharing Tower Vincente Guallart by Ulrich J. BeckerDocument22 pagesSharing Tower Vincente Guallart by Ulrich J. BeckerMigue GutierrezPas encore d'évaluation
- BRKSEC-2021 Firewall ArchitectureDocument74 pagesBRKSEC-2021 Firewall ArchitectureJesus RosalesPas encore d'évaluation
- LG LSR120H Service ManualDocument60 pagesLG LSR120H Service ManualFrank VartuliPas encore d'évaluation
- Ascensor AutoDocument4 pagesAscensor AutoPopescu Mircea IulianPas encore d'évaluation