Vous aimerez peut-être aussi
- Notes HQDocument96 pagesNotes HQPiyush AgrahariPas encore d'évaluation
- NLP SlidesDocument201 pagesNLP Slidesadarsh2dayPas encore d'évaluation
- Equality Constrained Optimization: Daniel P. RobinsonDocument33 pagesEquality Constrained Optimization: Daniel P. RobinsonJosue CofeePas encore d'évaluation
- Modeling, Simulation and Optimisation For Chemical EngineeringDocument22 pagesModeling, Simulation and Optimisation For Chemical EngineeringHậu Lê TrungPas encore d'évaluation
- CS-6777 Liu AbsDocument103 pagesCS-6777 Liu AbsILLA PAVAN KUMAR (PA2013003013042)Pas encore d'évaluation
- Nonlinear OptimizationDocument6 pagesNonlinear OptimizationKibria PrangonPas encore d'évaluation
- 06 Subgradients ScribedDocument5 pages06 Subgradients ScribedFaragPas encore d'évaluation
- Unconstrained Optimization Differentiable Case: October 9, 2008Document19 pagesUnconstrained Optimization Differentiable Case: October 9, 2008Samuel Alfonzo Gil BarcoPas encore d'évaluation
- Lecture 9 - SVMDocument42 pagesLecture 9 - SVMHusein YusufPas encore d'évaluation
- Konveksna OptimizacijaDocument179 pagesKonveksna OptimizacijaVladimir StojanovićPas encore d'évaluation
- B For I 1,, M: N J J JDocument19 pagesB For I 1,, M: N J J Jضيٍَِِ الكُمرPas encore d'évaluation
- Lec4 Gradient Method ReviseDocument33 pagesLec4 Gradient Method ReviseJose Lorenzo TrujilloPas encore d'évaluation
- Classical OptimizationDocument36 pagesClassical OptimizationnitishhgamingPas encore d'évaluation
- CSE 597 Spring 2019 Exercise 1 Due Sunday 11:59 PM, February 3thDocument6 pagesCSE 597 Spring 2019 Exercise 1 Due Sunday 11:59 PM, February 3thflorisandePas encore d'évaluation
- Optimization QFin Lecture NotesDocument33 pagesOptimization QFin Lecture NotesCarlos CadenaPas encore d'évaluation
- Lec 04 - Week 04 Operations ResearchDocument56 pagesLec 04 - Week 04 Operations Researchbnzayd2005Pas encore d'évaluation
- OQM Lecture Note - Part 1 Introduction To Mathematical OptimisationDocument10 pagesOQM Lecture Note - Part 1 Introduction To Mathematical OptimisationdanPas encore d'évaluation
- (k+1) K (K) (K) (K) : Recall That A Direction Is A Vector of Unit LengthDocument5 pages(k+1) K (K) (K) (K) : Recall That A Direction Is A Vector of Unit LengthHilal Akmal AdiputraPas encore d'évaluation
- BV Cvxslides PDFDocument301 pagesBV Cvxslides PDFTeerapat JenrungrotPas encore d'évaluation
- Optimization 111Document29 pagesOptimization 111mohammed aliPas encore d'évaluation
- Tutorial: Gaussian Process Models For Machine LearningDocument35 pagesTutorial: Gaussian Process Models For Machine LearningSaundaraya GuptaPas encore d'évaluation
- MATP6620 Integer and Combinatorial OptimizationDocument4 pagesMATP6620 Integer and Combinatorial OptimizationArya ChowdhuryPas encore d'évaluation
- Slides To 2015Document590 pagesSlides To 2015Anndrei AndiPas encore d'évaluation
- Introduction To Optimization: Anjela Govan North Carolina State University SAMSI NDHS Undergraduate Workshop 2006Document29 pagesIntroduction To Optimization: Anjela Govan North Carolina State University SAMSI NDHS Undergraduate Workshop 2006Teferi LemmaPas encore d'évaluation
- Coordinate Descent: Ryan Tibshirani Convex Optimization 10-725/36-725Document29 pagesCoordinate Descent: Ryan Tibshirani Convex Optimization 10-725/36-725Yang LongPas encore d'évaluation
- Convexity II: Optimization Basics: Ryan Tibshirani Convex Optimization 10-725Document28 pagesConvexity II: Optimization Basics: Ryan Tibshirani Convex Optimization 10-725saeed14820Pas encore d'évaluation
- 23 Lect DualAlgoDocument51 pages23 Lect DualAlgozhongyu xiaPas encore d'évaluation
- Karush Kuhn Tucker SlidesDocument45 pagesKarush Kuhn Tucker Slidesmatchman6Pas encore d'évaluation
- OBD Parts 1 and 2 PDFDocument106 pagesOBD Parts 1 and 2 PDFAgustín EstramilPas encore d'évaluation
- 05 1 Optimization Methods NDPDocument85 pages05 1 Optimization Methods NDPSebastian LorcaPas encore d'évaluation
- OQM Lecture Note - Part 8 Unconstrained Nonlinear OptimisationDocument23 pagesOQM Lecture Note - Part 8 Unconstrained Nonlinear OptimisationdanPas encore d'évaluation
- Lec 17 Multivariable OTDocument30 pagesLec 17 Multivariable OTMuhammad Bilal JunaidPas encore d'évaluation
- Convex Optimization in Classification Problems: MIT/ORC Spring SeminarDocument39 pagesConvex Optimization in Classification Problems: MIT/ORC Spring SeminarPatrick O'RourkePas encore d'évaluation
- Sparsity and Its MathematicsDocument44 pagesSparsity and Its MathematicsjwdaliPas encore d'évaluation
- Continuous OptimizationDocument51 pagesContinuous Optimizationlaphv494Pas encore d'évaluation
- Chapter 7Document37 pagesChapter 7Hoang Quoc TrungPas encore d'évaluation
- HJB EquationsDocument38 pagesHJB EquationsbobmezzPas encore d'évaluation
- Notes 3Document8 pagesNotes 3Sriram BalasubramanianPas encore d'évaluation
- JO Ao Lopes DiasDocument19 pagesJO Ao Lopes DiasRosita Salas TuanamaPas encore d'évaluation
- Lecture 4: Parametric and Non-Parametric RegressionDocument42 pagesLecture 4: Parametric and Non-Parametric RegressionZineddine ALICHEPas encore d'évaluation
- Chapter 2 DMMDocument57 pagesChapter 2 DMMPratibha GoswamiPas encore d'évaluation
- (Chapter 3) Quadratic FunctionDocument17 pages(Chapter 3) Quadratic Functiondenixng100% (3)
- Homework 3Document2 pagesHomework 3zenden626Pas encore d'évaluation
- Equality Constrained MinimizationDocument19 pagesEquality Constrained MinimizationfindingfelicityPas encore d'évaluation
- GT1 W01 TT02 PDFDocument67 pagesGT1 W01 TT02 PDFTrọng HiếuPas encore d'évaluation
- Chapter 2 OptimizationDocument47 pagesChapter 2 OptimizationDHEEVIKA SURESHPas encore d'évaluation
- Project For Automated Train by RoshanDocument6 pagesProject For Automated Train by RoshanRoshan SinghPas encore d'évaluation
- IEOR E4007 November 24, 2021 G. IyengarDocument9 pagesIEOR E4007 November 24, 2021 G. IyengarKiKi ChenPas encore d'évaluation
- Nonlinear ProgrammingDocument35 pagesNonlinear ProgrammingPreethi GopalanPas encore d'évaluation
- Introduction, Function and Limits With Derivatives: Module OutlineDocument10 pagesIntroduction, Function and Limits With Derivatives: Module OutlineErn NievaPas encore d'évaluation
- 2021 Week 5 Chapter3 ControlDocument7 pages2021 Week 5 Chapter3 ControlAdibPas encore d'évaluation
- Masdar Nalp2 PDFDocument10 pagesMasdar Nalp2 PDFMohammad RofiiPas encore d'évaluation
- Presentation 6 1 MINLPDocument85 pagesPresentation 6 1 MINLPAvinashPas encore d'évaluation
- Acceleration Methods: Aitken's MethodDocument5 pagesAcceleration Methods: Aitken's MethodOubelaid AdelPas encore d'évaluation
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)D'EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Pas encore d'évaluation
- A-level Maths Revision: Cheeky Revision ShortcutsD'EverandA-level Maths Revision: Cheeky Revision ShortcutsÉvaluation : 3.5 sur 5 étoiles3.5/5 (8)
- Phrasal VerbDocument6 pagesPhrasal VerbKaseh DhaahPas encore d'évaluation
- Apostrophes Are Used To - That Something Belongs To Someone or SomethingDocument6 pagesApostrophes Are Used To - That Something Belongs To Someone or SomethingKaseh DhaahPas encore d'évaluation
- EssayDocument2 pagesEssayKaseh DhaahPas encore d'évaluation
- IntroductionDocument3 pagesIntroductionKaseh DhaahPas encore d'évaluation
- Streaming Algorithm Count-Min SketchDocument16 pagesStreaming Algorithm Count-Min SketchSridevi UnnikrishnanPas encore d'évaluation
- Lecture Notes COMP3506Document17 pagesLecture Notes COMP3506JackPas encore d'évaluation
- AIDocument9 pagesAIArijit DasPas encore d'évaluation
- Assignment 1: Solving Bloxorz Using Search: Due Sunday, 1 November, 11pmDocument2 pagesAssignment 1: Solving Bloxorz Using Search: Due Sunday, 1 November, 11pmMehmet BaşaranPas encore d'évaluation
- Some of The Assumption Taken While Working With Linear Programming AreDocument2 pagesSome of The Assumption Taken While Working With Linear Programming AreJyoti Arvind PathakPas encore d'évaluation
- V4i1201557Document16 pagesV4i1201557multe123Pas encore d'évaluation
- BE Formes Et ContoursDocument7 pagesBE Formes Et ContourszuiliPas encore d'évaluation
- DAA and Web Design Lab Section 1 Question 1Document7 pagesDAA and Web Design Lab Section 1 Question 1Vanshika KumarastogiPas encore d'évaluation
- Logic ClockDocument3 pagesLogic ClocksampathaboPas encore d'évaluation
- Analytical Modeling of Parallel Systems: Ananth Grama, Anshul Gupta, George Karypis, and Vipin KumarDocument67 pagesAnalytical Modeling of Parallel Systems: Ananth Grama, Anshul Gupta, George Karypis, and Vipin KumarzoravarPas encore d'évaluation
- Bairstow MethodDocument17 pagesBairstow MethodDiya SinghalPas encore d'évaluation
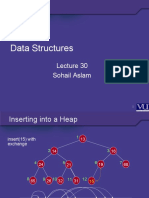
- Data Structures: Sohail AslamDocument21 pagesData Structures: Sohail AslamM NOOR MALIKPas encore d'évaluation
- 《Operating Systems》-Experimental instruction-Experiment 5 FIFO algorithmDocument6 pages《Operating Systems》-Experimental instruction-Experiment 5 FIFO algorithmBRANDY GANYIREPas encore d'évaluation
- Lecture 8 ApplicationsDocument26 pagesLecture 8 Applications은지Pas encore d'évaluation
- PPTDocument9 pagesPPTsindhuvindhya100% (1)
- Bisection Method: Laboratory Activity No. 4Document13 pagesBisection Method: Laboratory Activity No. 4JOSEFCARLMIKHAIL GEMINIANOPas encore d'évaluation
- Week 2: - Solution of LPPDocument21 pagesWeek 2: - Solution of LPPSheraz HassanPas encore d'évaluation
- Enter The Size of The Queue: 8 Menu 1. Enqueue 2. Dequeue 3. Display Queue 4. Exit Enter Choice (1..4)Document5 pagesEnter The Size of The Queue: 8 Menu 1. Enqueue 2. Dequeue 3. Display Queue 4. Exit Enter Choice (1..4)John Michael CincoPas encore d'évaluation
- Check Digit: Multiple Errors, Such As Two Replacement Errors (12 34) Though, Typically, Double Errors WillDocument4 pagesCheck Digit: Multiple Errors, Such As Two Replacement Errors (12 34) Though, Typically, Double Errors WillMuhamad AbdurahimPas encore d'évaluation
- Labmanual: Bcse2321: Data Structures Using C++ Lab ManualDocument60 pagesLabmanual: Bcse2321: Data Structures Using C++ Lab ManualANMOL CHAUHANPas encore d'évaluation
- A New Heuristic of The Decision Tree Induction: Ning Li, Li Zhao, Ai-Xia Chen, Qing-Wu Meng, Guo-Fang ZhangDocument6 pagesA New Heuristic of The Decision Tree Induction: Ning Li, Li Zhao, Ai-Xia Chen, Qing-Wu Meng, Guo-Fang ZhangkiranPas encore d'évaluation
- W11 Balanced BSTDocument56 pagesW11 Balanced BSTbbddbbd2003Pas encore d'évaluation
- Lecture 3 Types of Machine LearningDocument40 pagesLecture 3 Types of Machine LearningSaikat DasPas encore d'évaluation
- Python Lab Programs 1. To Write A Python Program To Find GCD of Two NumbersDocument12 pagesPython Lab Programs 1. To Write A Python Program To Find GCD of Two NumbersAYUSHI DEOTAREPas encore d'évaluation
- Lab 11: Implementation of The BINARY SEARCH TREE Data Structure With The Help of AlgorithmsDocument4 pagesLab 11: Implementation of The BINARY SEARCH TREE Data Structure With The Help of Algorithmshashir mahboobPas encore d'évaluation
- BCSL 045 PDFDocument16 pagesBCSL 045 PDFjasirPas encore d'évaluation
- MCQDocument4 pagesMCQspraveen2007Pas encore d'évaluation
- DAA Interview Questions and AnswersDocument9 pagesDAA Interview Questions and AnswersPranjal KumarPas encore d'évaluation
- AA Tree: Balancing RotationsDocument6 pagesAA Tree: Balancing Rotationsneoage12Pas encore d'évaluation
- ZT Java Collections Cheat SheetDocument1 pageZT Java Collections Cheat SheetmpvinaykumarPas encore d'évaluation