Vous aimerez peut-être aussi
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5795)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1091)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- CP R80.10 NexGenSecurityGateway Guide PDFDocument198 pagesCP R80.10 NexGenSecurityGateway Guide PDFAdmirem MudzagadaPas encore d'évaluation
- Larsen and Toubro RVNL Bid Document Rock Bolts PDFDocument240 pagesLarsen and Toubro RVNL Bid Document Rock Bolts PDFSubhash Kedia100% (1)
- Basic NetworkingDocument21 pagesBasic NetworkingMina Ilagan RazonPas encore d'évaluation
- NSX Battle Card - FinalDocument2 pagesNSX Battle Card - FinalElias Bezulle100% (1)
- 1 5 1Document5 pages1 5 1daemsalPas encore d'évaluation
- TCSP10403R0Document30 pagesTCSP10403R0BADRI VENKATESHPas encore d'évaluation
- SRI FireFighting Equipments 2012 PDFDocument46 pagesSRI FireFighting Equipments 2012 PDFsullamsPas encore d'évaluation
- 642-813 3 VLANs and TrunksDocument38 pages642-813 3 VLANs and TrunksAdmirem MudzagadaPas encore d'évaluation
- Math 1030 Working in The YardDocument4 pagesMath 1030 Working in The Yardapi-313345556Pas encore d'évaluation
- Captive Bred Lion PolicyDocument19 pagesCaptive Bred Lion PolicyAdmirem MudzagadaPas encore d'évaluation
- Checkpoint Firewall Cheat SheetDocument1 pageCheckpoint Firewall Cheat SheetAdmirem MudzagadaPas encore d'évaluation
- OSI Model Reference Chart PDFDocument1 pageOSI Model Reference Chart PDFAdmirem MudzagadaPas encore d'évaluation
- US Cyber Security Mission Directory 2017Document36 pagesUS Cyber Security Mission Directory 2017Admirem MudzagadaPas encore d'évaluation
- CP R80.10 IdentityAwareness AdminGuide PDFDocument140 pagesCP R80.10 IdentityAwareness AdminGuide PDFAdmirem MudzagadaPas encore d'évaluation
- 642-813 6 Spanning TreeDocument22 pages642-813 6 Spanning TreeAdmirem MudzagadaPas encore d'évaluation
- Jeppesen Charts LegendsDocument34 pagesJeppesen Charts LegendsFatih OguzPas encore d'évaluation
- Aerocore PropertiesDocument2 pagesAerocore PropertieskflimPas encore d'évaluation
- Business Plan: Syeda Zurriat & Aimen RabbaniDocument11 pagesBusiness Plan: Syeda Zurriat & Aimen RabbanizaraaPas encore d'évaluation
- EBS SDK Best PracticesDocument57 pagesEBS SDK Best Practicespurnachandra426Pas encore d'évaluation
- Cable Ties CatalogDocument60 pagesCable Ties CatalogRvPas encore d'évaluation
- IBM Flex System p270 Compute Node Planning and Implementation GuideDocument630 pagesIBM Flex System p270 Compute Node Planning and Implementation GuideAnonymous Qvouxg2aPas encore d'évaluation
- Difference Between Dictionary Managed Tablespace (DMT) and Locally Managed Tablespace (LMT)Document2 pagesDifference Between Dictionary Managed Tablespace (DMT) and Locally Managed Tablespace (LMT)Rose MaPas encore d'évaluation
- Gogostemcells StudentpagesDocument2 pagesGogostemcells Studentpagesapi-356824125Pas encore d'évaluation
- CPB 20104 Mass Transfer 2 UniKL MICET Experiment 1: Cooling TowerDocument20 pagesCPB 20104 Mass Transfer 2 UniKL MICET Experiment 1: Cooling TowerSiti Hajar Mohamed100% (6)
- 7708 DAQ Card DatasheetDocument2 pages7708 DAQ Card DatasheetSerbanescu AndreiPas encore d'évaluation
- Mechatronics R16 Oct 2019 PDFDocument4 pagesMechatronics R16 Oct 2019 PDFrajuPas encore d'évaluation
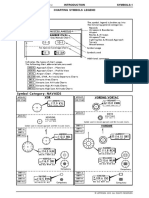
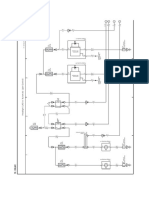
- Overall EWD Vehicle Exterior Rear Fog LightDocument10 pagesOverall EWD Vehicle Exterior Rear Fog Lightgabrielzinho43Pas encore d'évaluation
- HSD Area Security GuardDocument2 pagesHSD Area Security GuardSavita matPas encore d'évaluation
- Instrument Transformer Fuses Types WBP and BRT: Catalogue B12/06/01/EDocument8 pagesInstrument Transformer Fuses Types WBP and BRT: Catalogue B12/06/01/EivanramljakPas encore d'évaluation
- Load Calculation JowharDocument6 pagesLoad Calculation JowharKhalid Abdirashid AbubakarPas encore d'évaluation
- 01+yn1m301719-Afb 1rtaDocument53 pages01+yn1m301719-Afb 1rtaNurul Islam FarukPas encore d'évaluation
- PTWDocument3 pagesPTWAngel Silva VicentePas encore d'évaluation
- HeiDocument1 pageHeiJose Nelson Moreno BPas encore d'évaluation
- Web UI Norox Neu PDFDocument8 pagesWeb UI Norox Neu PDFGovardhan RaviPas encore d'évaluation
- Datalogic Gryphon GM4100 User GuideDocument52 pagesDatalogic Gryphon GM4100 User Guidebgrabbe92540% (1)
- VCD-D ManualDocument13 pagesVCD-D ManualnimmuhkPas encore d'évaluation
- MP-20x Datasheet 1Document2 pagesMP-20x Datasheet 1Francisco MoragaPas encore d'évaluation
- EXCEL To Tally LeggerImport-ok - 2Document7 pagesEXCEL To Tally LeggerImport-ok - 2Mukesh MakadiaPas encore d'évaluation