Vous aimerez peut-être aussi
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Bhagwat Gita Chapter 1Document10 pagesBhagwat Gita Chapter 1rohit1999Pas encore d'évaluation
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Properties of Shape Year 2: 1 MarkDocument2 pagesProperties of Shape Year 2: 1 Markrohit1999Pas encore d'évaluation
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Bhagwat Gita Chapter 3Document17 pagesBhagwat Gita Chapter 3rohit1999Pas encore d'évaluation
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- Primary English Student AnthologyDocument100 pagesPrimary English Student Anthologyrohit1999Pas encore d'évaluation
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- Bhagwat Gita Chapter 2Document15 pagesBhagwat Gita Chapter 2rohit19990% (1)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- Spring Block 3 Year 2 Properties of Shape AnswersDocument2 pagesSpring Block 3 Year 2 Properties of Shape Answersrohit1999Pas encore d'évaluation
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- Year 2: Place Value AssessmentDocument2 pagesYear 2: Place Value Assessmentrohit1999Pas encore d'évaluation
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Year 2 Place Value - End of Block AssessmentDocument2 pagesYear 2 Place Value - End of Block Assessmentrohit1999Pas encore d'évaluation
- Spring Block 1 Year 2 Division AnswersDocument2 pagesSpring Block 1 Year 2 Division Answersrohit1999Pas encore d'évaluation
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Year 1 Block 6 TimeDocument14 pagesYear 1 Block 6 Timerohit1999Pas encore d'évaluation
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Task 2 The AscentDocument3 pagesTask 2 The Ascentrohit1999Pas encore d'évaluation
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- List of Organisms Invertebrates VertebratesDocument2 pagesList of Organisms Invertebrates Vertebratesrohit1999Pas encore d'évaluation
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Task 3 Film ReviewDocument3 pagesTask 3 Film Reviewrohit1999Pas encore d'évaluation
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- Task 1 Advertise Your TownDocument3 pagesTask 1 Advertise Your Townrohit1999Pas encore d'évaluation
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- Map House 1 PDFDocument1 pageMap House 1 PDFrohit1999Pas encore d'évaluation
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Mental Maths Quiz 2:3: Name DateDocument2 pagesMental Maths Quiz 2:3: Name Daterohit1999Pas encore d'évaluation
- Prayer EquationDocument30 pagesPrayer Equationrohit1999Pas encore d'évaluation
- Animal Cell Diagram PDFDocument2 pagesAnimal Cell Diagram PDFrohit1999Pas encore d'évaluation
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Forces and Motion Activity: A. B. C. DDocument2 pagesForces and Motion Activity: A. B. C. Drohit1999Pas encore d'évaluation
- Human Eye: Label The Parts of The Diagram BelowDocument2 pagesHuman Eye: Label The Parts of The Diagram Belowrohit1999Pas encore d'évaluation
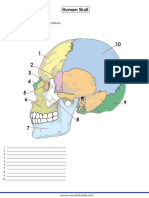
- Human Skull: Label The Parts of The Diagram BelowDocument2 pagesHuman Skull: Label The Parts of The Diagram Belowrohit1999Pas encore d'évaluation
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- SATS Ks2 Mathematics 2001 Mental Arithmetic Answer SheetDocument1 pageSATS Ks2 Mathematics 2001 Mental Arithmetic Answer Sheetrohit1999Pas encore d'évaluation
- Competency Framework: Civil ServiceDocument46 pagesCompetency Framework: Civil Servicerohit1999Pas encore d'évaluation
- Course Outline - BUS 173 - Applied Statistics - NSUDocument5 pagesCourse Outline - BUS 173 - Applied Statistics - NSUmirza.intesar01Pas encore d'évaluation
- Sinharay S. Definition of Statistical InferenceDocument11 pagesSinharay S. Definition of Statistical InferenceSara ZeynalzadePas encore d'évaluation
- Chapter8 NewDocument30 pagesChapter8 NewNick GoldingPas encore d'évaluation
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Otm Probability Dec 23 CapranavDocument9 pagesOtm Probability Dec 23 CapranavAbhijeet SinghPas encore d'évaluation
- Pert-Example PDFDocument2 pagesPert-Example PDFakbar hossainPas encore d'évaluation
- Mean Median Mode RangeDocument2 pagesMean Median Mode Rangejasonyeoh333Pas encore d'évaluation
- Probability Problems and SolutionsDocument3 pagesProbability Problems and SolutionsWoof Dawgmann0% (1)
- Playing With Random Numbers: February 24, 2016Document10 pagesPlaying With Random Numbers: February 24, 2016Tenis VijestiPas encore d'évaluation
- Probability Part 2Document43 pagesProbability Part 2Jomar RabiaPas encore d'évaluation
- Kherstie C. Deocampo Filamer Christian University Indayagan Maayon Capiz Graduate School Mat - S0C. Sci. Student 2 SEMESTER, A.Y. 2020 - 2021Document2 pagesKherstie C. Deocampo Filamer Christian University Indayagan Maayon Capiz Graduate School Mat - S0C. Sci. Student 2 SEMESTER, A.Y. 2020 - 2021Kherstie ViannettePas encore d'évaluation
- Data DescriptionDocument9 pagesData DescriptionChloe RegenciaPas encore d'évaluation
- ch08 - Operations Research SolutionDocument39 pagesch08 - Operations Research SolutionSneha KhuranaPas encore d'évaluation
- High Stock Returns Before Holidays: Existence and Evidence On Possible CausesDocument17 pagesHigh Stock Returns Before Holidays: Existence and Evidence On Possible CausesAngus SadpetPas encore d'évaluation
- 21CS54 QB Test3Document2 pages21CS54 QB Test3harshahg1717Pas encore d'évaluation
- Business Research MethodologyDocument2 pagesBusiness Research MethodologySharad PatilPas encore d'évaluation
- 101 Things A Six Sigma Black Belt Should KnowDocument2 pages101 Things A Six Sigma Black Belt Should KnowFatih Mehmet CetinPas encore d'évaluation
- Common Mistakes in Interpretation of Regression CoefficientsDocument2 pagesCommon Mistakes in Interpretation of Regression Coefficientsranjitd07Pas encore d'évaluation
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Company Name: Quality Management System (QSM) Title: Machine Capability Study (CMK Study) ReportDocument1 pageCompany Name: Quality Management System (QSM) Title: Machine Capability Study (CMK Study) ReportSachin RamdurgPas encore d'évaluation
- CSCI 688 Homework 6: Megan Rose Bryant Department of Mathematics William and Mary November 12, 2014Document12 pagesCSCI 688 Homework 6: Megan Rose Bryant Department of Mathematics William and Mary November 12, 2014Anıl KahvecioğluPas encore d'évaluation
- MAT 211 CourseGuide - Lecture Notes - Summer 2015Document79 pagesMAT 211 CourseGuide - Lecture Notes - Summer 2015Rifat SaiedPas encore d'évaluation
- Robustness Analysis: P. Vanicek E. J. Krakiwsky M. R. CraymerDocument37 pagesRobustness Analysis: P. Vanicek E. J. Krakiwsky M. R. CraymerMul YaniPas encore d'évaluation
- J H: A E M C S F M: Umping Edges N Xamination of Ovements in Opper Pot and Utures ArketsDocument21 pagesJ H: A E M C S F M: Umping Edges N Xamination of Ovements in Opper Pot and Utures ArketsKumaran SanthoshPas encore d'évaluation
- Introduction To EconometricsDocument825 pagesIntroduction To EconometricsFred Enea100% (5)
- Multiple Regression Tutorial 3Document5 pagesMultiple Regression Tutorial 32plus5is7100% (2)
- Full Download Introduction To Wireless and Mobile Systems 4th Edition Agrawal Solutions ManualDocument36 pagesFull Download Introduction To Wireless and Mobile Systems 4th Edition Agrawal Solutions Manualmuhapideokars100% (31)
- Code Segmented Regression SASDocument5 pagesCode Segmented Regression SASSowmya TatavartyPas encore d'évaluation
- 12 Chi Square and Odds RatiosDocument44 pages12 Chi Square and Odds RatiosNurul Huda KowitaPas encore d'évaluation
- Multiple Linear Regression: Diagnostics: Statistics 203: Introduction To Regression and Analysis of VarianceDocument16 pagesMultiple Linear Regression: Diagnostics: Statistics 203: Introduction To Regression and Analysis of VariancecesardakoPas encore d'évaluation
- Path AnalysisDocument13 pagesPath AnalysisRangga B. DesaptaPas encore d'évaluation
- The Ancestor's Tale: A Pilgrimage to the Dawn of EvolutionD'EverandThe Ancestor's Tale: A Pilgrimage to the Dawn of EvolutionÉvaluation : 4 sur 5 étoiles4/5 (812)
- When You Find Out the World Is Against You: And Other Funny Memories About Awful MomentsD'EverandWhen You Find Out the World Is Against You: And Other Funny Memories About Awful MomentsÉvaluation : 3.5 sur 5 étoiles3.5/5 (13)
- Dark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseD'EverandDark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseÉvaluation : 3.5 sur 5 étoiles3.5/5 (69)