Vous aimerez peut-être aussi
- Discrete Structure - Theory of Logics (Ful PDF) - Watermark - Watermark - Removed - 2Document126 pagesDiscrete Structure - Theory of Logics (Ful PDF) - Watermark - Watermark - Removed - 2aryanraj22760Pas encore d'évaluation
- Unit 7: Types of Sets and Special Sets: ContentDocument9 pagesUnit 7: Types of Sets and Special Sets: ContentNigussie WenPas encore d'évaluation
- BC0052-Theory of Computer ScienceDocument227 pagesBC0052-Theory of Computer SciencedatatronPas encore d'évaluation
- Module 1 Discrete Math - SetDocument15 pagesModule 1 Discrete Math - SetShiori EulinPas encore d'évaluation
- BCA-122 Mathematics & Statistics PDFDocument242 pagesBCA-122 Mathematics & Statistics PDFDinesh Gaikwad100% (7)
- Chapter 2 SetDocument51 pagesChapter 2 SetSchizophrenic RakibPas encore d'évaluation
- Chapter 5 - SetsDocument5 pagesChapter 5 - Setshassoon221 / حسوون٢٢١Pas encore d'évaluation
- Lecture1 Set TheoryDocument4 pagesLecture1 Set Theorycsa1980Pas encore d'évaluation
- Module 2 Lesson 2Document35 pagesModule 2 Lesson 2Cristyl Anne Dafielmoto CeballosPas encore d'évaluation
- About SetDocument28 pagesAbout SetNiño Lemuel Lazatin ConcinaPas encore d'évaluation
- Math in Our World - Module 3.1Document10 pagesMath in Our World - Module 3.1Gee Lysa Pascua Vilbar100% (1)
- SetsDocument56 pagesSetsIrtizahussain100% (1)
- Discourse NotesDocument56 pagesDiscourse NotesGladmanPas encore d'évaluation
- SetsDocument5 pagesSetsRajendranbehappyPas encore d'évaluation
- Unit 3 DMSDocument14 pagesUnit 3 DMSshubhamPas encore d'évaluation
- ADA CSE - IT (3rd Year) Engg. Lecture Notes, Ebook PDF Download PART1Document82 pagesADA CSE - IT (3rd Year) Engg. Lecture Notes, Ebook PDF Download PART1Raja SekharPas encore d'évaluation
- Introduction To Theory of Computation Module Description: Sl. No. Topic Time Required Lecture #Document27 pagesIntroduction To Theory of Computation Module Description: Sl. No. Topic Time Required Lecture #rmidhunajyothiPas encore d'évaluation
- Discrete Mathematical Structures 15CS3 6: Set TheoryDocument34 pagesDiscrete Mathematical Structures 15CS3 6: Set TheoryShruti LadagePas encore d'évaluation
- Module in Ge 4-Mathematics in The Modern World: The Language of SetDocument9 pagesModule in Ge 4-Mathematics in The Modern World: The Language of SetJeko Betguen PalangiPas encore d'évaluation
- Chapter 1(s)Document105 pagesChapter 1(s)chanky-wp22Pas encore d'évaluation
- Set TheoryDocument11 pagesSet Theoryrahul4mstiPas encore d'évaluation
- Chqpter 2: Basic Structures: Sets, Functions, Sequences, Sums, and MatricesDocument12 pagesChqpter 2: Basic Structures: Sets, Functions, Sequences, Sums, and MatricesAhmed AlmussaPas encore d'évaluation
- Ignou Math Mte 06Document206 pagesIgnou Math Mte 06Bhaskar Bharati100% (3)
- 2.2 Four Basic Concepts-1-19Document19 pages2.2 Four Basic Concepts-1-19Venus Abigail Gutierrez100% (2)
- 7 Set TheoryDocument10 pages7 Set TheoryNestor Minguito Jr.Pas encore d'évaluation
- Relations and FunctionsDocument12 pagesRelations and FunctionsMUZAMMIL IBRAHMI 20BCE11083Pas encore d'évaluation
- BE - IT - AIDS - II - Module1 - W 2 - Fuzzy Logic and Its ApplicationDocument51 pagesBE - IT - AIDS - II - Module1 - W 2 - Fuzzy Logic and Its ApplicationShivamPas encore d'évaluation
- MCS-013 Block 1Document46 pagesMCS-013 Block 1Abhishek VeerkarPas encore d'évaluation
- English MathDocument19 pagesEnglish MathFadilah YasinPas encore d'évaluation
- Module - Real AnalysisDocument233 pagesModule - Real AnalysisShaira Sanchez Bucio0% (1)
- 1.1 Set Theory PDFDocument5 pages1.1 Set Theory PDFAndhiarra Kylla AtonPas encore d'évaluation
- Lesson 2 - The Four Basic Concepts of MathematicsDocument8 pagesLesson 2 - The Four Basic Concepts of MathematicsSTORM STARPas encore d'évaluation
- Chapter 1(s)Document107 pagesChapter 1(s)WEI QUAN LEEPas encore d'évaluation
- Chap 1Document17 pagesChap 1Batma ThurgaPas encore d'évaluation
- A Set Is A Well Defined Collection of ObjectDocument25 pagesA Set Is A Well Defined Collection of ObjectDisha GoyalPas encore d'évaluation
- Lec 13 - Algebraic StructuresDocument13 pagesLec 13 - Algebraic Structures9921103067Pas encore d'évaluation
- Cse-III-discrete Mathematical Structures (10cs34) - NotesDocument115 pagesCse-III-discrete Mathematical Structures (10cs34) - NotesMallikarjun AradhyaPas encore d'évaluation
- Assign 1 Sppu OopDocument3 pagesAssign 1 Sppu OopRoshanPas encore d'évaluation
- Discrete Maths XDocument269 pagesDiscrete Maths XssssoumiksenPas encore d'évaluation
- Lesson 2.2Document113 pagesLesson 2.2Maricris GatdulaPas encore d'évaluation
- Ex 2 1Document9 pagesEx 2 1poli402pkPas encore d'évaluation
- Cartesian ProductDocument6 pagesCartesian ProductNilo ValeraPas encore d'évaluation
- Module 2 - Sets & RelationsDocument75 pagesModule 2 - Sets & RelationsArvind ChouhanPas encore d'évaluation
- Set TheoryDocument76 pagesSet Theorymundando networksPas encore d'évaluation
- Set Operations: Subjects To Be LearnedDocument6 pagesSet Operations: Subjects To Be LearnedTrisha BarriosPas encore d'évaluation
- 03 - SetsDocument19 pages03 - SetsHdbxh VvdudhPas encore d'évaluation
- Sets - Its Operations (Ch2)Document52 pagesSets - Its Operations (Ch2)EMAN MURTAZA TURKPas encore d'évaluation
- CS402/AL102 - Automata and Language Theory: Daisy Jean A. CastilloDocument52 pagesCS402/AL102 - Automata and Language Theory: Daisy Jean A. CastilloDaisy Jean CastilloPas encore d'évaluation
- Lecture 1 Notes-SetsDocument9 pagesLecture 1 Notes-SetsWebby ZimbaPas encore d'évaluation
- Basic Structures: Sets, Functions, Sequences and SumsDocument62 pagesBasic Structures: Sets, Functions, Sequences and SumsNikPas encore d'évaluation
- 2 Introduction To Set TheoryDocument8 pages2 Introduction To Set TheoryPlay ZonePas encore d'évaluation
- Sets and ProbabilityDocument13 pagesSets and ProbabilityVenu GeorgePas encore d'évaluation
- MMW - Lesson03 - Intro To Set TheoryDocument7 pagesMMW - Lesson03 - Intro To Set TheoryDexter CaroPas encore d'évaluation
- Sets, Relation and FunctionDocument16 pagesSets, Relation and FunctionAshwani Kumar SinghPas encore d'évaluation
- Descri Te Report 1Document32 pagesDescri Te Report 1ChingChing ErmPas encore d'évaluation
- Set TheoryDocument18 pagesSet Theoryaakash vaishnavPas encore d'évaluation
- IT2106 - MFC1 - Chapter 01Document28 pagesIT2106 - MFC1 - Chapter 01boraga6195Pas encore d'évaluation
- Bbam 170 Topic 1Document16 pagesBbam 170 Topic 1lmPas encore d'évaluation
- Nitin Talmale: Presented byDocument29 pagesNitin Talmale: Presented bymsanees005Pas encore d'évaluation
- Socket ProgrammingDocument19 pagesSocket Programmingmsanees005Pas encore d'évaluation
- Seriespdf - PHP Id 88Document1 pageSeriespdf - PHP Id 88msanees005Pas encore d'évaluation
- Upcoming Indian TV 2011 (World - 97-2003)Document2 pagesUpcoming Indian TV 2011 (World - 97-2003)msanees005Pas encore d'évaluation
- Closure Properties Table PDFDocument1 pageClosure Properties Table PDFaakashPas encore d'évaluation
- AI FinalExamDocument5 pagesAI FinalExamAhmed AdelPas encore d'évaluation
- Awk - A Tutorial and Introduction - by Bruce BarnettDocument233 pagesAwk - A Tutorial and Introduction - by Bruce BarnettpeeyushthebestPas encore d'évaluation
- Python HistoryDocument20 pagesPython HistoryPriyanshu ShahPas encore d'évaluation
- Syntax Directed Translation (Compatibility Mode) PDFDocument27 pagesSyntax Directed Translation (Compatibility Mode) PDFManmeet Kaur0% (1)
- Compiler Lab FinalDocument66 pagesCompiler Lab FinalbrindhaPas encore d'évaluation
- M13 An Intro To Abstract MathDocument166 pagesM13 An Intro To Abstract MathMengrui JiangPas encore d'évaluation
- Problem Solving With LoopsDocument22 pagesProblem Solving With LoopsmichaelPas encore d'évaluation
- MCQDocument7 pagesMCQPooja SainiPas encore d'évaluation
- SS 0slab 15csl67Document63 pagesSS 0slab 15csl67TalibPas encore d'évaluation
- Compiler Design Chapter-4Document77 pagesCompiler Design Chapter-4Vuggam Venkatesh100% (2)
- Python Regular Expressions Cheat Sheet PDFDocument1 pagePython Regular Expressions Cheat Sheet PDFsharathdhamodaranPas encore d'évaluation
- Java String Reference PDFDocument3 pagesJava String Reference PDFManjulaPas encore d'évaluation
- Artificial Intelligence and Knowledge RepresentationDocument20 pagesArtificial Intelligence and Knowledge Representationlipika008Pas encore d'évaluation
- MMW.04 (Logic)Document61 pagesMMW.04 (Logic)felize padllaPas encore d'évaluation
- Welcome To CMSC 250 Discrete StructuresDocument13 pagesWelcome To CMSC 250 Discrete StructuresKyle HerockPas encore d'évaluation
- Chapter 7 Logical Agents 2Document98 pagesChapter 7 Logical Agents 2Mahendra BilagiPas encore d'évaluation
- The Conceptual Square Underwrites The Alethic Square'S ValidityDocument27 pagesThe Conceptual Square Underwrites The Alethic Square'S ValiditySantiago BuladacoPas encore d'évaluation
- Programming ParadigmDocument26 pagesProgramming Paradigmjmelcris_chavez100% (1)
- AstDocument82 pagesAstmrangelPas encore d'évaluation
- Statement Forms and Material EquivalenceDocument15 pagesStatement Forms and Material EquivalenceRossana RosePas encore d'évaluation
- On Derivation Languages Corresponding To Context-Free GrammarsDocument7 pagesOn Derivation Languages Corresponding To Context-Free Grammarsvanaj123Pas encore d'évaluation
- Regular Pumping ExamplesDocument31 pagesRegular Pumping ExamplesTimothy FindlingPas encore d'évaluation
- Holmberg Grahn Magnusson 2014Document22 pagesHolmberg Grahn Magnusson 2014sinusina9813Pas encore d'évaluation
- Handout BITS-C464 Machine Learning - 2013Document3 pagesHandout BITS-C464 Machine Learning - 2013Ankit AgarwalPas encore d'évaluation
- CT 801 / CSE802 - Compiler ConstructionDocument12 pagesCT 801 / CSE802 - Compiler ConstructionSumit PaulPas encore d'évaluation
- Proof, Logic, and Conjecture - The Mathematician's Toolbox PDFDocument481 pagesProof, Logic, and Conjecture - The Mathematician's Toolbox PDFearseeker100% (1)
- Experiment 10:: AIM: WAP To Implement Shift Reduce ParserDocument5 pagesExperiment 10:: AIM: WAP To Implement Shift Reduce Parserakshat sharmaPas encore d'évaluation
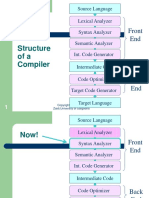
- Structure Ofa Compiler: Front EndDocument95 pagesStructure Ofa Compiler: Front EndHassan AliPas encore d'évaluation
- Lab 1 Introduction To PROLOGDocument4 pagesLab 1 Introduction To PROLOGchakravarthyashokPas encore d'évaluation