Vous aimerez peut-être aussi
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Sparcengine™Ultra™Axi: Oem Technical Reference Manual July 1 9 9 8Document181 pagesSparcengine™Ultra™Axi: Oem Technical Reference Manual July 1 9 9 8Jaxon Mosfet100% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- Blue Screen of Death - Survival GuideDocument14 pagesBlue Screen of Death - Survival GuideCharles WeberPas encore d'évaluation
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- EZ - RZ - MZ Series Option Compatibility 28jun2010Document25 pagesEZ - RZ - MZ Series Option Compatibility 28jun2010Nma ColonelnmaPas encore d'évaluation
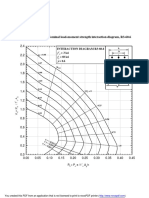
- Interaction Aci ImprimirDocument96 pagesInteraction Aci ImprimirBhavin ShahPas encore d'évaluation
- RAB Desain Komunikasi VisualDocument16 pagesRAB Desain Komunikasi VisualAkhmad MuhazabPas encore d'évaluation
- Implementing Linear Algebraalgorithms For Dense MatricesDocument22 pagesImplementing Linear Algebraalgorithms For Dense MatricesFilipe AmaroPas encore d'évaluation
- Improving The Accuracy of Computed Singular ValuesDocument8 pagesImproving The Accuracy of Computed Singular ValuesFilipe AmaroPas encore d'évaluation
- Improving The Accuracy of Computed Eigenvalues and EigenvectorsDocument23 pagesImproving The Accuracy of Computed Eigenvalues and EigenvectorsFilipe AmaroPas encore d'évaluation
- LG 47LW6500 LT12C Led LCDDocument104 pagesLG 47LW6500 LT12C Led LCDFilipe AmaroPas encore d'évaluation
- Tle-Ict Computer Systems Servicing: Quarter 1 - Module 3Document10 pagesTle-Ict Computer Systems Servicing: Quarter 1 - Module 3Jeo MillanoPas encore d'évaluation
- M522 (MS-15221) Part NumberDocument22 pagesM522 (MS-15221) Part Numberwirelesssoul100% (1)
- Manual-Dynamite EnglishDocument40 pagesManual-Dynamite EnglishSERVICE CENTER PABX 085289388205Pas encore d'évaluation
- Ece Tech QuestionsDocument4 pagesEce Tech QuestionsGaurav KathuriaPas encore d'évaluation
- Acer Aspire 1600 (Wistron Toucan2) PDFDocument47 pagesAcer Aspire 1600 (Wistron Toucan2) PDFMustafa AkanPas encore d'évaluation
- Data Transfer Software Instruction - 1.5Document26 pagesData Transfer Software Instruction - 1.5orlando sepulvedaPas encore d'évaluation
- 8-Bit Micro-Controller: Otp RomDocument54 pages8-Bit Micro-Controller: Otp RomCornel Dan RadPas encore d'évaluation
- Laptops and Desktop-MAY PRICE 2011Document8 pagesLaptops and Desktop-MAY PRICE 2011Innocent StrangerPas encore d'évaluation
- Acer 7750 - 7750G Compal LA-6911P r0.3Document60 pagesAcer 7750 - 7750G Compal LA-6911P r0.3franlc1Pas encore d'évaluation
- Embedded System of Shibu K VDocument10 pagesEmbedded System of Shibu K Vshahebgoudahalladamani0% (1)
- Basic Computer Operation: Advance Information and Communication TechnologyDocument45 pagesBasic Computer Operation: Advance Information and Communication TechnologyChadweck FidelinoPas encore d'évaluation
- COMP 231 Microprocessor and Assembly LanguageDocument55 pagesCOMP 231 Microprocessor and Assembly LanguageAanchalAdhikariPas encore d'évaluation
- Switchview 1000 Switch: Installer/User GuideDocument20 pagesSwitchview 1000 Switch: Installer/User GuideFirstfettPas encore d'évaluation
- Cpe402 q1ddDocument5 pagesCpe402 q1ddDaine GoPas encore d'évaluation
- Chapter 04 Computer Architecture and DDocument95 pagesChapter 04 Computer Architecture and DPooja VashisthPas encore d'évaluation
- Everything You Want in One Device: Mono PPMDocument4 pagesEverything You Want in One Device: Mono PPMব্যাচ কোর্ডিনেটরPas encore d'évaluation
- 1Document16 pages1knightkitPas encore d'évaluation
- NEORV32 UserGuide-nightlyDocument48 pagesNEORV32 UserGuide-nightlymutd2017Pas encore d'évaluation
- 8085 Microprocessor Programs: Microprocessor & Microcontroller Lab ManualDocument16 pages8085 Microprocessor Programs: Microprocessor & Microcontroller Lab ManualLIFE of PSPas encore d'évaluation
- CBSE Schools in RohiniDocument13 pagesCBSE Schools in Rohinisadhubaba100Pas encore d'évaluation
- Tma1 - Eex3336 2019 PDFDocument2 pagesTma1 - Eex3336 2019 PDFDK White LionPas encore d'évaluation
- Celebrating: Rudra Pratap SumanDocument26 pagesCelebrating: Rudra Pratap SumanAnkur SinghPas encore d'évaluation
- AIO ThinkCentre Edge 72z - 92zDocument10 pagesAIO ThinkCentre Edge 72z - 92zJagabandhu PradhanPas encore d'évaluation
- 173 CSE313 FinalDocument2 pages173 CSE313 FinalSabbir HossainPas encore d'évaluation
- Computer Generations First Generation: Vacuum Tubes (1940-1956)Document2 pagesComputer Generations First Generation: Vacuum Tubes (1940-1956)trevorPas encore d'évaluation