Vous aimerez peut-être aussi
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- What is a t-testDocument31 pagesWhat is a t-testEe HAng Yong0% (1)
- Neuropsychology and Neuropsychiatry of Neurodegenerative DisordersDocument192 pagesNeuropsychology and Neuropsychiatry of Neurodegenerative DisordersIcaroPas encore d'évaluation
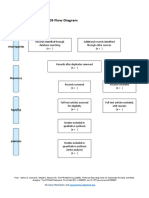
- PRISMA 2009 Flow Diagram GuideDocument1 pagePRISMA 2009 Flow Diagram GuideKou YashiroPas encore d'évaluation
- The Evolution of The Brain, The Human Nature of Cortical Circuits, and Intellectual Creativity Javier DeFelipe1,2,3Document17 pagesThe Evolution of The Brain, The Human Nature of Cortical Circuits, and Intellectual Creativity Javier DeFelipe1,2,3Bliss Tamar LoladzePas encore d'évaluation
- Comparison of Two TDCS Protocols On Pain and EEG Alpha 2 Oscillations in Women With FibromyalgiaDocument7 pagesComparison of Two TDCS Protocols On Pain and EEG Alpha 2 Oscillations in Women With FibromyalgiaIcaroPas encore d'évaluation
- Luria's Three-Step Test: What Is It and What Does It Tell Us?Document5 pagesLuria's Three-Step Test: What Is It and What Does It Tell Us?IcaroPas encore d'évaluation
- Statistical Procedures For Determining The Extent of Cognitive Change Following ConcussionDocument7 pagesStatistical Procedures For Determining The Extent of Cognitive Change Following Concussionpsyquis2Pas encore d'évaluation
- Kos Toulas 2017Document11 pagesKos Toulas 2017IcaroPas encore d'évaluation
- 10 1016@j Clinph 2018 03 020Document9 pages10 1016@j Clinph 2018 03 020IcaroPas encore d'évaluation
- 1980 5764 DN 11 01 00006Document9 pages1980 5764 DN 11 01 00006IcaroPas encore d'évaluation
- Comparison of Two TDCS Protocols On Pain and EEG Alpha 2 Oscillations in Women With FibromyalgiaDocument7 pagesComparison of Two TDCS Protocols On Pain and EEG Alpha 2 Oscillations in Women With FibromyalgiaIcaroPas encore d'évaluation
- Vancouver Condensed Guide 2015Document8 pagesVancouver Condensed Guide 2015Sameer SharmaPas encore d'évaluation
- Trajectories of Decline in Cognition and Daily FunctioningDocument10 pagesTrajectories of Decline in Cognition and Daily FunctioningIcaroPas encore d'évaluation
- Test-Instructions - Category Fluency TestDocument14 pagesTest-Instructions - Category Fluency TestIcaroPas encore d'évaluation
- Brain and Cognitive Reserve Translation Via NetworkDocument48 pagesBrain and Cognitive Reserve Translation Via NetworkIcaro100% (1)
- Criteria Lewy 2017 Neurology McKeith BlancDocument15 pagesCriteria Lewy 2017 Neurology McKeith BlancIcaroPas encore d'évaluation
- Dee 0006 0020Document8 pagesDee 0006 0020IcaroPas encore d'évaluation
- Living With Chronic Illness ScaleDocument6 pagesLiving With Chronic Illness ScaleIcaroPas encore d'évaluation
- Bozeat2000 PDFDocument9 pagesBozeat2000 PDFIcaroPas encore d'évaluation
- How Effective Is The Trail Making TestDocument5 pagesHow Effective Is The Trail Making TestIcaroPas encore d'évaluation
- LSDDocument2 pagesLSDI-Sun Deep Mohan TeaPas encore d'évaluation
- Example How To Write A ProposalDocument9 pagesExample How To Write A ProposalSpoorthi PoojariPas encore d'évaluation
- Sleep and Executive Functions in Older Adults - A Systematic ReviewDocument14 pagesSleep and Executive Functions in Older Adults - A Systematic ReviewIcaroPas encore d'évaluation
- Indications For NeuropsychologicalDocument5 pagesIndications For NeuropsychologicalIcaroPas encore d'évaluation
- Using Latent Class Analysis To Model Prescription Medications in The Measurement of Falling Among A Community Elderly PopulationDocument7 pagesUsing Latent Class Analysis To Model Prescription Medications in The Measurement of Falling Among A Community Elderly PopulationIcaroPas encore d'évaluation
- Cancellation Task in Very Low Educated PeopleDocument9 pagesCancellation Task in Very Low Educated PeopleIcaroPas encore d'évaluation
- New Scoring Methodology Improves The Adas CogDocument17 pagesNew Scoring Methodology Improves The Adas CogIcaroPas encore d'évaluation
- Sleep and Human AgingDocument18 pagesSleep and Human AgingIcaroPas encore d'évaluation
- The Clock Drawing TestDocument13 pagesThe Clock Drawing TestIcaroPas encore d'évaluation
- Effects of Age, APOE ε4, Cognitive Reserve and Hippocampal Volume on Cognitive InterventionDocument8 pagesEffects of Age, APOE ε4, Cognitive Reserve and Hippocampal Volume on Cognitive InterventionIcaroPas encore d'évaluation
- Stat Doc Pract 6,7,8Document17 pagesStat Doc Pract 6,7,8Ajay KajaniyaPas encore d'évaluation
- Introduction to JASP: A Free and User-Friendly Statistics PackageDocument13 pagesIntroduction to JASP: A Free and User-Friendly Statistics PackageGianni BasilePas encore d'évaluation
- Ncaa ML CompetitionDocument24 pagesNcaa ML Competitionapi-462457883Pas encore d'évaluation
- How To Perform T-Test in PandasDocument5 pagesHow To Perform T-Test in PandasGaruma AbdisaPas encore d'évaluation
- Analyze Metagenomic Profiles with STAMP v2.0 User GuideDocument26 pagesAnalyze Metagenomic Profiles with STAMP v2.0 User GuideRubens DuartePas encore d'évaluation
- Nagel Ben Project ReportDocument24 pagesNagel Ben Project Reportapi-576829952Pas encore d'évaluation
- Module 4B Two Sample T-Test For Independent GroupsDocument29 pagesModule 4B Two Sample T-Test For Independent GroupsqueenbeeastPas encore d'évaluation
- Post Hoc Power Analysis Is It An Informative and Meaningful AnalysisDocument4 pagesPost Hoc Power Analysis Is It An Informative and Meaningful Analysis古寒州Pas encore d'évaluation
- Construction and Building Materials: N. Buratti, C. MazzottiDocument10 pagesConstruction and Building Materials: N. Buratti, C. MazzottidrpPas encore d'évaluation
- Introduction to R for Data AnalysisDocument37 pagesIntroduction to R for Data AnalysisDIVYANSH GAUR (RA2011027010090)Pas encore d'évaluation
- Zimmerman 2004Document9 pagesZimmerman 2004lacisagPas encore d'évaluation
- Converting Daily Rainfall Data To Sub DaDocument11 pagesConverting Daily Rainfall Data To Sub DaAli AhmadPas encore d'évaluation