Vous aimerez peut-être aussi
- Documentation 1.1. GeneralDocument145 pagesDocumentation 1.1. Generalcoralonso0% (1)
- Insert Your Titles and Guide Name: International Research Journal of Engineering and Technology (IRJET)Document8 pagesInsert Your Titles and Guide Name: International Research Journal of Engineering and Technology (IRJET)Harikrishnan ShunmugamPas encore d'évaluation
- Toward Developing Benchmark Dataset PDFDocument18 pagesToward Developing Benchmark Dataset PDFRahmatul HusnaPas encore d'évaluation
- Search Encrypted DataDocument13 pagesSearch Encrypted Datashital shermalePas encore d'évaluation
- Ef Cient Provenance Management Via Clustering and Hybrid Storage in Big Data EnvironmentsDocument12 pagesEf Cient Provenance Management Via Clustering and Hybrid Storage in Big Data EnvironmentsVidhya RajPas encore d'évaluation
- Zigbee Based Wireless Data AcquisitionDocument15 pagesZigbee Based Wireless Data AcquisitionanjanbsPas encore d'évaluation
- Expert Systems With Applications: Arzu Gorgulu Kakisim, Ibrahim SogukpinarDocument10 pagesExpert Systems With Applications: Arzu Gorgulu Kakisim, Ibrahim SogukpinarLUZ MARINA TURPO AGUILARPas encore d'évaluation
- Information Enhancemenet For DMDocument2 pagesInformation Enhancemenet For DMKalyani DantuluriPas encore d'évaluation
- Ch3.1 DS Jeopardy ReviewDocument10 pagesCh3.1 DS Jeopardy Reviewrichiezhang06Pas encore d'évaluation
- Data Quality at A Glance PDFDocument10 pagesData Quality at A Glance PDFLucas GomesPas encore d'évaluation
- Data Quality at A Glance.: Datenbank-Spektrum January 2005Document10 pagesData Quality at A Glance.: Datenbank-Spektrum January 2005Lucas GomesPas encore d'évaluation
- Data Profiling Vision Felix NaumannDocument11 pagesData Profiling Vision Felix NaumannRoberto Alfonso SiagianPas encore d'évaluation
- Privacy-Preserving and Regular Language Search Over Encrypted Cloud DataDocument11 pagesPrivacy-Preserving and Regular Language Search Over Encrypted Cloud DataRenuka CPas encore d'évaluation
- An Empirical Study of Differentially-Private Analytics For High-Speed Network DataDocument3 pagesAn Empirical Study of Differentially-Private Analytics For High-Speed Network DataOana NiculaescuPas encore d'évaluation
- Mining Knowledge From Text Using Information ExtractionDocument8 pagesMining Knowledge From Text Using Information ExtractionAries HaPas encore d'évaluation
- Information Retrieval: A Relational Model of Data for Large Shared Data BanksDocument11 pagesInformation Retrieval: A Relational Model of Data for Large Shared Data Bankscoolgaurav13Pas encore d'évaluation
- Security: Trustworthy Scientific ComputingDocument4 pagesSecurity: Trustworthy Scientific Computingjoshua abrahamPas encore d'évaluation
- Detecting Protected Health Information With An Incremental Learning Ensemble A Case Study On New Zealand Clinical TextDocument10 pagesDetecting Protected Health Information With An Incremental Learning Ensemble A Case Study On New Zealand Clinical TextDewan Tarikul MannanPas encore d'évaluation
- Unit 1 5 Data InfoDocument2 pagesUnit 1 5 Data InfoMs.Iswarya CSE DepartmentPas encore d'évaluation
- 65 Ijcse 02825 PDFDocument6 pages65 Ijcse 02825 PDFnmmishra77Pas encore d'évaluation
- SSW: A Small-World-Based Overlay For Peer-to-Peer SearchDocument15 pagesSSW: A Small-World-Based Overlay For Peer-to-Peer Searchsyed_zakriyaPas encore d'évaluation
- LANLI: A Natural Language Interfacing Tool For Relational Database Query GenerationDocument14 pagesLANLI: A Natural Language Interfacing Tool For Relational Database Query Generationeditor_ijarcssePas encore d'évaluation
- A Hierarchical Fused Fuzzy Deep Neural Network For Data ClassificationDocument8 pagesA Hierarchical Fused Fuzzy Deep Neural Network For Data ClassificationYosua SiregarPas encore d'évaluation
- The Informatics Core of The Alzheimer's Disease Neuroimaging InitiativeDocument10 pagesThe Informatics Core of The Alzheimer's Disease Neuroimaging InitiativebrunoabramoffPas encore d'évaluation
- Data Mining With Linked Data: Past, Present, and Future: Rohit Beniwal, Vikas Gupta, Manish Rawat, and Rishabh AggarwalDocument5 pagesData Mining With Linked Data: Past, Present, and Future: Rohit Beniwal, Vikas Gupta, Manish Rawat, and Rishabh Aggarwalsahiljangra97Pas encore d'évaluation
- Edinburgh Research Explorer: Data Context Informed Data WranglingDocument9 pagesEdinburgh Research Explorer: Data Context Informed Data WranglingmicorreodeclipPas encore d'évaluation
- Kanta Kapoor: Metadata: A Pathway To Electronic ResourcesDocument5 pagesKanta Kapoor: Metadata: A Pathway To Electronic ResourcesSougata ChattopadhyayPas encore d'évaluation
- A Starter Pack To Exploratory Data Analysis With Python, Pandas, Seaborn, and Scikit-LearnDocument40 pagesA Starter Pack To Exploratory Data Analysis With Python, Pandas, Seaborn, and Scikit-LearnudaPas encore d'évaluation
- 1 s2.0 S0020025523008204 MainDocument22 pages1 s2.0 S0020025523008204 MainImrana YaqoubPas encore d'évaluation
- Data Link Discovery Frameworks For Biomedical Linked Data - A Comprehensive StudyDocument8 pagesData Link Discovery Frameworks For Biomedical Linked Data - A Comprehensive StudyhousseindhPas encore d'évaluation
- Semi Structured Data Information Retrieval Using Ontologies: Vladim Ir Smatan Ik, Karol Matia SkoDocument3 pagesSemi Structured Data Information Retrieval Using Ontologies: Vladim Ir Smatan Ik, Karol Matia SkomatheushbernardimPas encore d'évaluation
- Data Mining An Overview From A Database PerspectiveDocument18 pagesData Mining An Overview From A Database PerspectiveThanish RaoPas encore d'évaluation
- Mis Lesson 6 10Document4 pagesMis Lesson 6 10Marcfhil SundiangPas encore d'évaluation
- Truth FinderDocument2 pagesTruth FinderrijujosephPas encore d'évaluation
- Biomedicine Meets Semantic Web: Juan Bernabé MorenoDocument6 pagesBiomedicine Meets Semantic Web: Juan Bernabé MorenoJuan Bernabé MorenoPas encore d'évaluation
- p615 YangDocument14 pagesp615 Yang张浮云Pas encore d'évaluation
- Multi-Dimensional Feature Fusion and Stacking Ensemble MechanismDocument14 pagesMulti-Dimensional Feature Fusion and Stacking Ensemble MechanismyousufPas encore d'évaluation
- Visual Data MiningDocument2 pagesVisual Data MiningjhonarextPas encore d'évaluation
- mth157 Week1 Reading1Document72 pagesmth157 Week1 Reading1branmuffin482Pas encore d'évaluation
- Class Project Paper - Formatted - Marvel Universe SNA - FinalDocument8 pagesClass Project Paper - Formatted - Marvel Universe SNA - FinaldakmattPas encore d'évaluation
- Job Information Crawling, Visualization and Clustering of Job Search WebsitesDocument5 pagesJob Information Crawling, Visualization and Clustering of Job Search Websitesboopathi kumarPas encore d'évaluation
- Week 1 Introduction To DatabaseDocument30 pagesWeek 1 Introduction To DatabasePhương MinhPas encore d'évaluation
- Relational Model of Data Provides Independence for Large Shared Data BanksDocument11 pagesRelational Model of Data Provides Independence for Large Shared Data BanksGustavoLadinoPas encore d'évaluation
- Strong Lee Wang CA CM May 97Document9 pagesStrong Lee Wang CA CM May 97Aarom22Pas encore d'évaluation
- A Survey of Network-Based Intrusion Detection Data SetsDocument17 pagesA Survey of Network-Based Intrusion Detection Data SetsKeerthana SudarshanPas encore d'évaluation
- Genetic Algorithms For Multi-Criterion Classification and Clustering in Data MiningDocument12 pagesGenetic Algorithms For Multi-Criterion Classification and Clustering in Data Miningjkl316Pas encore d'évaluation
- Chrological Big Data Curation: A Study On The Enhanced Information Retrieval SystemDocument9 pagesChrological Big Data Curation: A Study On The Enhanced Information Retrieval SystemKalthoum ZaoualiPas encore d'évaluation
- Data Quality: The Other Face of Big Data: Barna Saha Divesh SrivastavaDocument4 pagesData Quality: The Other Face of Big Data: Barna Saha Divesh Srivastavausman dilawarPas encore d'évaluation
- Hybrid Decision Tree-Based Machine Learning Models For Short-Term Water Quality Prediction.Document14 pagesHybrid Decision Tree-Based Machine Learning Models For Short-Term Water Quality Prediction.Андрій ШебекоPas encore d'évaluation
- A Parallel Random Forest Algorithm For Big Data in A Spark Cloud Computing EnvironmentDocument15 pagesA Parallel Random Forest Algorithm For Big Data in A Spark Cloud Computing EnvironmentkikizouzouPas encore d'évaluation
- Arnold: Declarative Crowd-Machine Data IntegrationDocument8 pagesArnold: Declarative Crowd-Machine Data IntegrationSADOKPas encore d'évaluation
- Metadata Management Model For Relational Database Publication On Grid: An Ontology Based FrameworkDocument9 pagesMetadata Management Model For Relational Database Publication On Grid: An Ontology Based FrameworkKrisna AdiyartaPas encore d'évaluation
- My 40 TH PaperDocument13 pagesMy 40 TH PaperDaniel EzihePas encore d'évaluation
- BigData Terminology Hadoop MapReduce Yarn Spark File FormatsDocument42 pagesBigData Terminology Hadoop MapReduce Yarn Spark File FormatsyassmineelbessiPas encore d'évaluation
- Grid - Information - Services - For - Distribute - Failure Management Strategies in Grid PDFDocument14 pagesGrid - Information - Services - For - Distribute - Failure Management Strategies in Grid PDFSalum JumaPas encore d'évaluation
- Identity-Based Data Outsourcing With Comprehensive Auditing in CloudsDocument13 pagesIdentity-Based Data Outsourcing With Comprehensive Auditing in CloudsRaja Rathinam SPas encore d'évaluation
- Real-World Image Datasets For Federated LearningDocument8 pagesReal-World Image Datasets For Federated LearningFeng YuPas encore d'évaluation
- A Survey On Sampling and Profiling Over Big Data (Technical Report)Document17 pagesA Survey On Sampling and Profiling Over Big Data (Technical Report)Jaâfar BendrissPas encore d'évaluation
- Metadata Initiatives and Emerging Technologies To Improve Resource DiscoveryDocument10 pagesMetadata Initiatives and Emerging Technologies To Improve Resource DiscoverySougata ChattopadhyayPas encore d'évaluation
- Bayesian Networks in R: with Applications in Systems BiologyD'EverandBayesian Networks in R: with Applications in Systems BiologyPas encore d'évaluation
- Annual Review in Automatic Programming: International Tracts in Computer Science and Technology and Their Application, Volume 7D'EverandAnnual Review in Automatic Programming: International Tracts in Computer Science and Technology and Their Application, Volume 7Mark I. HalpernPas encore d'évaluation
- Yuxi3040 Terrazzo Tile Making Machne Quotation List PDFDocument4 pagesYuxi3040 Terrazzo Tile Making Machne Quotation List PDFNhek Vibol100% (1)
- HangDocument1 pageHangNhek VibolPas encore d'évaluation
- Table 1Document1 pageTable 1Nhek VibolPas encore d'évaluation
- SQL - With Practice Exercises, Learn SQL Fast (PDFDrive) PDFDocument167 pagesSQL - With Practice Exercises, Learn SQL Fast (PDFDrive) PDFNagisoy100% (1)
- YouTube Marketing Learn How To Become A Video MarketerDocument109 pagesYouTube Marketing Learn How To Become A Video MarketerNhek Vibol0% (2)
- HTML Forms PDFDocument8 pagesHTML Forms PDFAarthi EPas encore d'évaluation
- Smith, Benjamin C++ Simple and Effective Tips and Tricks To Learn PDFDocument139 pagesSmith, Benjamin C++ Simple and Effective Tips and Tricks To Learn PDFкв-1сPas encore d'évaluation
- YouTube Marketing Learn How To Become A Video MarketerDocument109 pagesYouTube Marketing Learn How To Become A Video MarketerNhek Vibol0% (2)
- YouTube Marketing Learn How To Become A Video MarketerDocument109 pagesYouTube Marketing Learn How To Become A Video MarketerNhek Vibol0% (2)
- TableDocument1 pageTableNhek VibolPas encore d'évaluation
- Ex 2Document2 pagesEx 2Nhek VibolPas encore d'évaluation
- Invoice 1Document1 pageInvoice 1Nhek VibolPas encore d'évaluation
- Regression Analysis and Forecasting ModelsDocument28 pagesRegression Analysis and Forecasting ModelsGiorgos PapakPas encore d'évaluation
- HTML Forms: Pat Morin COMP 2405Document20 pagesHTML Forms: Pat Morin COMP 2405Manoj KathriPas encore d'évaluation
- HTML, CSS & JavaScript Web Publishing Course OutlineDocument28 pagesHTML, CSS & JavaScript Web Publishing Course OutlineNhek VibolPas encore d'évaluation
- Introduction To Javascript Course Outline: Page 1 of 3Document3 pagesIntroduction To Javascript Course Outline: Page 1 of 3EmmanuelPas encore d'évaluation
- Javascript and Jquery - Course Syllabus: Module 0: Introduction To JavascriptDocument6 pagesJavascript and Jquery - Course Syllabus: Module 0: Introduction To JavascriptNhek VibolPas encore d'évaluation
- 500 Smoothies & Juices - The Only Smoothie & Juice Compendium You'll Ever Need (PDFDrive)Document286 pages500 Smoothies & Juices - The Only Smoothie & Juice Compendium You'll Ever Need (PDFDrive)Nhek VibolPas encore d'évaluation
- JavaScript Syllabus - Learn JavaScript ModulesDocument2 pagesJavaScript Syllabus - Learn JavaScript ModulesVinay KumarPas encore d'évaluation
- JavaScript & jQuery Course SyllabusDocument4 pagesJavaScript & jQuery Course SyllabusNhek VibolPas encore d'évaluation
- Information Technology Am 19Document22 pagesInformation Technology Am 19Hoven AlusenPas encore d'évaluation
- Introduction To Javascript Course Outline: Page 1 of 3Document3 pagesIntroduction To Javascript Course Outline: Page 1 of 3EmmanuelPas encore d'évaluation
- Law On AuditionDocument16 pagesLaw On AuditionNhek VibolPas encore d'évaluation
- Cs Learning Outcomes PDFDocument2 pagesCs Learning Outcomes PDFNhek VibolPas encore d'évaluation
- EU - Curriculum Development Guidelines - 2204 - enDocument46 pagesEU - Curriculum Development Guidelines - 2204 - enpmirrPas encore d'évaluation
- 2C BDocument8 pages2C BNhek VibolPas encore d'évaluation
- HTML & Css Syllabus PDFDocument7 pagesHTML & Css Syllabus PDFnihalPas encore d'évaluation
- A. Complete The Sentences With "To Be"Document3 pagesA. Complete The Sentences With "To Be"Nhek VibolPas encore d'évaluation
- OJCST Vol9 N3 P 212-225Document14 pagesOJCST Vol9 N3 P 212-225Nhek VibolPas encore d'évaluation
- Forecasting Construction Demand: A Comparison of Box-Jenkins and Support Vector Machine ModelDocument10 pagesForecasting Construction Demand: A Comparison of Box-Jenkins and Support Vector Machine ModelNhek VibolPas encore d'évaluation
- IR Chap3Document45 pagesIR Chap3biniam teshomePas encore d'évaluation
- Google Scholar Indexed JournalsDocument3 pagesGoogle Scholar Indexed JournalsGeePas encore d'évaluation
- Data Mining-Unit IVDocument15 pagesData Mining-Unit IVDrishti GuptaPas encore d'évaluation
- Syllabus: Veermata Jijabai Technological InstituteDocument41 pagesSyllabus: Veermata Jijabai Technological Institutedhanu10896Pas encore d'évaluation
- Understanding The Deep Web in 10 MinutesDocument11 pagesUnderstanding The Deep Web in 10 MinutesRamanan KumaranPas encore d'évaluation
- Unit 1 IrtDocument21 pagesUnit 1 IrtpriyadharshinianbuvaananPas encore d'évaluation
- Memex Project - DARPA (2014) DARPA-BAA-14-21Document42 pagesMemex Project - DARPA (2014) DARPA-BAA-14-21LJ's infoDOCKETPas encore d'évaluation
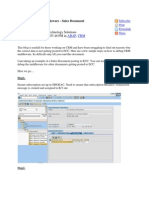
- Debug CRM Middleware Sales Document IssuesDocument41 pagesDebug CRM Middleware Sales Document IssuesSarika Gupta100% (1)
- 13-1 Office AutomationDocument2 pages13-1 Office AutomationJuma Marco CharlesPas encore d'évaluation
- Unit 4Document47 pagesUnit 4عبدالرحيم اودينPas encore d'évaluation
- Web Image Re-Ranking Using Query-Specific Semantic SignaturesDocument14 pagesWeb Image Re-Ranking Using Query-Specific Semantic Signaturesphilo minaPas encore d'évaluation
- Information Retrieval Features of Online Search ServicesDocument6 pagesInformation Retrieval Features of Online Search ServicesHellenNdegwaPas encore d'évaluation
- Website DesignDocument128 pagesWebsite DesignAbhinandan Sharma100% (2)
- IR UNIT I - NotesDocument23 pagesIR UNIT I - NotesAngelPas encore d'évaluation
- KeyBank Lockbox File LayoutsDocument13 pagesKeyBank Lockbox File LayoutsPradeep Kumar ShuklaPas encore d'évaluation
- 2 FootPrinting - LabManualDocument11 pages2 FootPrinting - LabManualuma maheswarPas encore d'évaluation
- Address Different URL (Uniform Locâtor) ,: Pârts ThisDocument32 pagesAddress Different URL (Uniform Locâtor) ,: Pârts ThisnarimenePas encore d'évaluation
- University of Gondar: Document Image RetrievalDocument9 pagesUniversity of Gondar: Document Image RetrievalLens NewPas encore d'évaluation
- Lecture 5-Dictionaries and Tolerant RetrievalDocument48 pagesLecture 5-Dictionaries and Tolerant RetrievalYash GuptaPas encore d'évaluation
- IADOT Records Management System Indexing Standard 1997Document111 pagesIADOT Records Management System Indexing Standard 1997joseph jaalaPas encore d'évaluation
- Lesson 12Document8 pagesLesson 12GoddessOfBeauty AphroditePas encore d'évaluation
- Search ENgineDocument28 pagesSearch ENginePraveen YadavPas encore d'évaluation
- 32TZA800 Navigation BookDocument120 pages32TZA800 Navigation BookGeoff HargreavesPas encore d'évaluation
- The Internet Data Collection With The Go PDFDocument21 pagesThe Internet Data Collection With The Go PDFDa DiPas encore d'évaluation
- SEO Audit Raw FileDocument34 pagesSEO Audit Raw Filesohail3669998Pas encore d'évaluation
- Primo System Administration GuideDocument150 pagesPrimo System Administration Guidemariolgui68Pas encore d'évaluation
- E Last AlertDocument53 pagesE Last Alerts.zeraoui1595Pas encore d'évaluation
- LisDocument27 pagesLisrambabu12341Pas encore d'évaluation
- Business Model of GoogleDocument57 pagesBusiness Model of GoogleAbhishek Pandav100% (4)