Vous aimerez peut-être aussi
- Index On The Search Key, and Heap Files With An Unclusted Hash Index. Briefly Discuss TheDocument5 pagesIndex On The Search Key, and Heap Files With An Unclusted Hash Index. Briefly Discuss TheFaizan Bashir SidhuPas encore d'évaluation
- Lab 2 - Basic Programming in Java-BESE-10Document9 pagesLab 2 - Basic Programming in Java-BESE-10Waseem AbbasPas encore d'évaluation
- CS 2421 Lab 2Document4 pagesCS 2421 Lab 2Mani KamaliPas encore d'évaluation
- How To Solving The Error Message AU133 During The Settlement in ControllingDocument2 pagesHow To Solving The Error Message AU133 During The Settlement in Controllingotaviomendes1100% (1)
- Mongodb DBA HomeworkDocument4 pagesMongodb DBA Homeworkafetuieog100% (1)
- CSE 5311: Design and Analysis of Algorithms Programming Project TopicsDocument3 pagesCSE 5311: Design and Analysis of Algorithms Programming Project TopicsFgvPas encore d'évaluation
- HW LMDocument36 pagesHW LMSabrina LiPas encore d'évaluation
- BD7 Assignment S22Document4 pagesBD7 Assignment S22Course ZilaPas encore d'évaluation
- Assignment 5: Raw Memory: Bits and BytesDocument6 pagesAssignment 5: Raw Memory: Bits and BytesnikPas encore d'évaluation
- What Is Page Thrashing?Document4 pagesWhat Is Page Thrashing?Karthik KartzPas encore d'évaluation
- Programming in Visual Studio 2017 C# - Combined PDFDocument1 392 pagesProgramming in Visual Studio 2017 C# - Combined PDFSergeyups SergeyPas encore d'évaluation
- Conclusion and Future WorkDocument2 pagesConclusion and Future WorkpreethiPas encore d'évaluation
- CSC461-Objected Oriented ProgrammingDocument52 pagesCSC461-Objected Oriented ProgrammingFranklyn Frank100% (1)
- C Programming Style: Paul KrzyzanowskiDocument7 pagesC Programming Style: Paul KrzyzanowskiJonathan Leonel GasparriniPas encore d'évaluation
- POSIX Threads Explained by Daniel RobbinsDocument9 pagesPOSIX Threads Explained by Daniel RobbinsJulio Rodrigo Castillo HuertaPas encore d'évaluation
- Assignment 4 - Comp8547Document2 pagesAssignment 4 - Comp8547Jay SaavnPas encore d'évaluation
- 24 Patterns For Clean Code - Techniques For Faster, Safer Code With Minimal Debugging (2016 Robert Beisert) (C Programming)Document71 pages24 Patterns For Clean Code - Techniques For Faster, Safer Code With Minimal Debugging (2016 Robert Beisert) (C Programming)DanniPas encore d'évaluation
- How To Improve Your Skills As A Programmer: StepsDocument7 pagesHow To Improve Your Skills As A Programmer: StepsHarsh KhajuriaPas encore d'évaluation
- Homework 3.1 m101jsDocument8 pagesHomework 3.1 m101jsafeukeaqn100% (1)
- Mongodb DBA Homework AnswersDocument5 pagesMongodb DBA Homework Answersh41zdb84100% (1)
- Practical Assignment - :: Distributed Data Processing With Apache SparkDocument3 pagesPractical Assignment - :: Distributed Data Processing With Apache SparkTeshome MulugetaPas encore d'évaluation
- Keyword ClusteringDocument15 pagesKeyword ClusteringJACOB RACHUONYOPas encore d'évaluation
- Milestone 3 Final ReportDocument8 pagesMilestone 3 Final Reportbond2007Pas encore d'évaluation
- BasicDataStructures StudyGuideDocument51 pagesBasicDataStructures StudyGuideRichard McdanielPas encore d'évaluation
- EssbaseDocument8 pagesEssbaseamer328Pas encore d'évaluation
- Homework 3.1 Mongodb AnswerDocument6 pagesHomework 3.1 Mongodb Answerafetzhsse100% (1)
- Hadoop QuestionsDocument41 pagesHadoop QuestionsAmit BhartiyaPas encore d'évaluation
- Hyperion Essbase Interview QuestionsDocument7 pagesHyperion Essbase Interview QuestionsBeena ShahPas encore d'évaluation
- Mongodb Homework 5.3 AnswerDocument8 pagesMongodb Homework 5.3 Answerafmcdeafl100% (1)
- JISC ReportDocument9 pagesJISC Reportgms899Pas encore d'évaluation
- Scikit-Learn Cookbook Sample ChapterDocument52 pagesScikit-Learn Cookbook Sample ChapterPackt PublishingPas encore d'évaluation
- SCS16LDocument3 pagesSCS16Lsanjay mehraPas encore d'évaluation
- DB Design TipsDocument21 pagesDB Design TipsafernandestavaresPas encore d'évaluation
- Software Engineering by SachinrajDocument8 pagesSoftware Engineering by Sachinrajsachinraj2100% (3)
- Thesis 2.2 TutorialDocument7 pagesThesis 2.2 Tutorialjenniferrobinsonjackson100% (2)
- CS 6290: High-Performance Computer Architecture Project 0: For Questions That Are AskingDocument10 pagesCS 6290: High-Performance Computer Architecture Project 0: For Questions That Are AskingRaviteja JayantiPas encore d'évaluation
- ML Interview QuestionsDocument146 pagesML Interview QuestionsIndraneelGhoshPas encore d'évaluation
- Mongodb Homework 3.1 PythonDocument6 pagesMongodb Homework 3.1 Pythonafmtkadub100% (1)
- C, C++ Programming Tips: Vishal Patil Summer 2003Document21 pagesC, C++ Programming Tips: Vishal Patil Summer 2003mohanty_anantakumar6332Pas encore d'évaluation
- You Cannot Solve Performance Problems by Writing RequirementsDocument3 pagesYou Cannot Solve Performance Problems by Writing Requirementsmouchrif.hadiPas encore d'évaluation
- CS 11 - Machine Problem 2 PDFDocument3 pagesCS 11 - Machine Problem 2 PDFeduardo edradaPas encore d'évaluation
- Thesis Title Web ApplicationDocument6 pagesThesis Title Web Applicationmandyhebertlafayette100% (2)
- George Ross Computer Programming Examples For Chemical EngineersDocument304 pagesGeorge Ross Computer Programming Examples For Chemical Engineersvarun kumarPas encore d'évaluation
- Mongodb Homework 4.2 AnswerDocument4 pagesMongodb Homework 4.2 Answerh3tdfrzv100% (1)
- Report in MLDocument9 pagesReport in MLPriti GuptaPas encore d'évaluation
- Building RAG-based LLM Applications For Production (Part 1) : Blog DetailDocument39 pagesBuilding RAG-based LLM Applications For Production (Part 1) : Blog DetailzishankamalPas encore d'évaluation
- A Pattern Language For Reverse Engineering: Serge Demeyer, Stéphane Ducasse, Oscar NierstraszDocument20 pagesA Pattern Language For Reverse Engineering: Serge Demeyer, Stéphane Ducasse, Oscar NierstraszmysticsoulPas encore d'évaluation
- Literate Programming Using Noweb: Terry Therneau October 11, 2019Document6 pagesLiterate Programming Using Noweb: Terry Therneau October 11, 2019PADMA SATHEESANPas encore d'évaluation
- Proj 1Document10 pagesProj 1devidassonar285Pas encore d'évaluation
- Building Scalable Apps With Redis and Node - Js Sample ChapterDocument44 pagesBuilding Scalable Apps With Redis and Node - Js Sample ChapterPackt PublishingPas encore d'évaluation
- Assignment 1 - Tree Based Search: OPTION A - SummaryDocument7 pagesAssignment 1 - Tree Based Search: OPTION A - SummaryNguyễn HậuPas encore d'évaluation
- Vba ProgrammeDocument1 pageVba ProgrammeballapandaPas encore d'évaluation
- CSCE 120: Learning To Code: Introduction To Data Hacktivity 2.2Document4 pagesCSCE 120: Learning To Code: Introduction To Data Hacktivity 2.2s_gamal15Pas encore d'évaluation
- C# Multithreaded and Parallel Programming Sample ChapterDocument36 pagesC# Multithreaded and Parallel Programming Sample ChapterPackt PublishingPas encore d'évaluation
- NachosDocument16 pagesNachosmkumarshahiPas encore d'évaluation
- Mongodb DBA Homework 4.3 AnswerDocument6 pagesMongodb DBA Homework 4.3 Answerafmtoolap100% (1)
- Directory System ThesisDocument8 pagesDirectory System ThesisPaperWritersCollegeCanada100% (2)
- Practical Oracle SQL: Mastering the Full Power of Oracle DatabaseD'EverandPractical Oracle SQL: Mastering the Full Power of Oracle DatabasePas encore d'évaluation
- SAS Interview Questions You'll Most Likely Be AskedD'EverandSAS Interview Questions You'll Most Likely Be AskedPas encore d'évaluation
- SAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesD'EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesPas encore d'évaluation
- MATLAB IntegrationDocument7 pagesMATLAB IntegrationJay Srivastava100% (1)
- Angular 2Document34 pagesAngular 2Ali HassanPas encore d'évaluation
- QDUS Session 28Document26 pagesQDUS Session 28eniPas encore d'évaluation
- Intel Cheat SheetDocument8 pagesIntel Cheat SheetwmcscroogePas encore d'évaluation
- SUMMATIVE TEST in ICF 9Document3 pagesSUMMATIVE TEST in ICF 9Chrelyn MarimonPas encore d'évaluation
- VI Reference CardDocument1 pageVI Reference CardFaisal Sikander KhanPas encore d'évaluation
- Y Frame A Modular and Declarative Framew PDFDocument26 pagesY Frame A Modular and Declarative Framew PDFcristian ungureanuPas encore d'évaluation
- SAP S - 4HANA On Premise 1709 Upgrade GuideDocument52 pagesSAP S - 4HANA On Premise 1709 Upgrade Guidey421997Pas encore d'évaluation
- OBIEE 11g Query LoggingDocument3 pagesOBIEE 11g Query Loggingcboss911Pas encore d'évaluation
- Niit C ProgrmmingDocument166 pagesNiit C ProgrmmingShivraj Kumar ChhetriPas encore d'évaluation
- Javascript Exercises For Lab PracticeDocument4 pagesJavascript Exercises For Lab Practiceritesh.shah433Pas encore d'évaluation
- JohnWilliams-Resume2013 (1) RuthDocument2 pagesJohnWilliams-Resume2013 (1) Ruthandres alvarezPas encore d'évaluation
- All ProgramsDocument40 pagesAll ProgramsSheikh HasanPas encore d'évaluation
- Huawei HCIA-Big Data V3.0 Certification ExamDocument4 pagesHuawei HCIA-Big Data V3.0 Certification ExamMaged ElgndyPas encore d'évaluation
- Write A Program To Implement Quick Sort Algorithm.: (For Programming Based Labs)Document4 pagesWrite A Program To Implement Quick Sort Algorithm.: (For Programming Based Labs)405 foundPas encore d'évaluation
- Risk Analysis and Management - MCQsDocument6 pagesRisk Analysis and Management - MCQsMudrikaPas encore d'évaluation
- Student Database System For Higher Education: Literature ReviewDocument4 pagesStudent Database System For Higher Education: Literature Reviewimran khanPas encore d'évaluation
- Minor Project (MCA-169) - MCA2022-24 - FormatDocument14 pagesMinor Project (MCA-169) - MCA2022-24 - FormatVandana GariaPas encore d'évaluation
- MCSA 70-764: Administering An SQL Database InfrastructureDocument8 pagesMCSA 70-764: Administering An SQL Database InfrastructureMuthu Raman ChinnaduraiPas encore d'évaluation
- Niladri Ray CVDocument3 pagesNiladri Ray CVNeelPas encore d'évaluation
- Self-Quiz 1 Control Structures (If, Do, While, and For) Attempt ReviewDocument8 pagesSelf-Quiz 1 Control Structures (If, Do, While, and For) Attempt ReviewKhaled kabboushPas encore d'évaluation
- Systems and Methods For Generating Software and Hardware BuildsDocument4 pagesSystems and Methods For Generating Software and Hardware BuildsljwPas encore d'évaluation
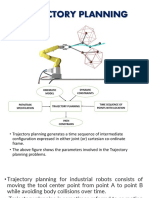
- Robotics Unit-4Document83 pagesRobotics Unit-4S19IT1215 HarshithaPas encore d'évaluation
- Tech SeminarDocument13 pagesTech SeminarAnil Reddy Pochampally100% (1)
- What Is Postgresql?Document12 pagesWhat Is Postgresql?Amal PrasadPas encore d'évaluation
- ErrorDocument2 pagesErrorFERRY HEPRIZON 2018Pas encore d'évaluation
- Final List C PraticalsDocument7 pagesFinal List C PraticalsDeepika BansalPas encore d'évaluation
- BTE in Payment Run' and Dunning'Document22 pagesBTE in Payment Run' and Dunning'Arasumani Arumugam100% (1)
- Cobc Help ScreenDocument3 pagesCobc Help ScreenIrene RagonaPas encore d'évaluation