Vous aimerez peut-être aussi
- ABHA Coil ProportionsDocument5 pagesABHA Coil ProportionsOctav OctavianPas encore d'évaluation
- Diesel Engines For Vehicles D2066 D2676Document6 pagesDiesel Engines For Vehicles D2066 D2676Branislava Savic63% (16)
- MEMORANDUM OF AGREEMENT DraftsDocument3 pagesMEMORANDUM OF AGREEMENT DraftsRichard Colunga80% (5)
- The Original Lists of Persons of Quality Emigrants Religious Exiles Political Rebels Serving Men Sold For A Term of Years Apprentices Children Stolen Maidens Pressed and OthersDocument609 pagesThe Original Lists of Persons of Quality Emigrants Religious Exiles Political Rebels Serving Men Sold For A Term of Years Apprentices Children Stolen Maidens Pressed and OthersShakir Daddy-Phatstacks Cannon100% (1)
- The DIRKS Methodology: A User GuideDocument285 pagesThe DIRKS Methodology: A User GuideJesus Frontera100% (2)
- Case ColorscopeDocument7 pagesCase ColorscopeRatin MathurPas encore d'évaluation
- Entrepreneurship - PPTX Version 1 - Copy (Autosaved) (Autosaved) (Autosaved) (Autosaved)Document211 pagesEntrepreneurship - PPTX Version 1 - Copy (Autosaved) (Autosaved) (Autosaved) (Autosaved)Leona Alicpala67% (3)
- Vanguard 44 - Anti Tank Helicopters PDFDocument48 pagesVanguard 44 - Anti Tank Helicopters PDFsoljenitsin250% (2)
- Post Renaissance Architecture in EuropeDocument10 pagesPost Renaissance Architecture in Europekali_007Pas encore d'évaluation
- TechBridge TCP ServiceNow Business Case - Group 6Document9 pagesTechBridge TCP ServiceNow Business Case - Group 6Takiyah Shealy100% (1)
- Army Aviation Digest - Apr 1971Document68 pagesArmy Aviation Digest - Apr 1971Aviation/Space History LibraryPas encore d'évaluation
- Fce Use of English 1 Teacher S Book PDFDocument2 pagesFce Use of English 1 Teacher S Book PDFOrestis GkaloPas encore d'évaluation
- V40i03 PDFDocument25 pagesV40i03 PDFHelio RamosPas encore d'évaluation
- Python Language 291 580Document290 pagesPython Language 291 580Hernan Tomas Silvestre HuancaPas encore d'évaluation
- Date and Time Series Objects: FRE6871 & FRE7241, Fall 2020Document49 pagesDate and Time Series Objects: FRE6871 & FRE7241, Fall 2020Jerzy PawlowskiPas encore d'évaluation
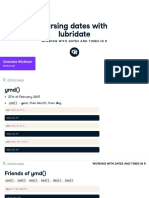
- Parsing Dates With Lubridate: Charlo e WickhamDocument23 pagesParsing Dates With Lubridate: Charlo e Wickhamavgle eminaPas encore d'évaluation
- Cognos RS - Functions - 16Document3 pagesCognos RS - Functions - 16Harry KonnectPas encore d'évaluation
- 6 Datetime - Basic Date and Time Types - Python 3.6Document33 pages6 Datetime - Basic Date and Time Types - Python 3.6nmulyonoPas encore d'évaluation
- Python Date and Time14Document8 pagesPython Date and Time14rashPas encore d'évaluation
- 10 Datetime - Basic Date and Time Types - Python 3.6Document29 pages10 Datetime - Basic Date and Time Types - Python 3.6nmulyonoPas encore d'évaluation
- Chalabi 2Document58 pagesChalabi 2SuperquantPas encore d'évaluation
- Oracle Date Functions: Useful Query ItemsDocument4 pagesOracle Date Functions: Useful Query ItemsHarry KonnectPas encore d'évaluation
- Module 9 Integrative Programming 2Document6 pagesModule 9 Integrative Programming 2Randy TabaogPas encore d'évaluation
- Task 03Document2 pagesTask 03princessoke141Pas encore d'évaluation
- Python Date TimeDocument5 pagesPython Date TimePhạm Ngọc TríPas encore d'évaluation
- Time Class: Java - Lang.object Java - Util.dateDocument2 pagesTime Class: Java - Lang.object Java - Util.dateShweta MhetrePas encore d'évaluation
- Task 03Document2 pagesTask 03Ndnrtkr tkrPas encore d'évaluation
- Package Chron': R Topics DocumentedDocument16 pagesPackage Chron': R Topics Documentedawake000Pas encore d'évaluation
- EpochDocument6 pagesEpochRenato UbarnesPas encore d'évaluation
- Reference Guide Datetime ManipulationDocument6 pagesReference Guide Datetime Manipulationhanzallahhassam73Pas encore d'évaluation
- Date Functions - FsDocument30 pagesDate Functions - FsJustPas encore d'évaluation
- FPR p04Document29 pagesFPR p04Nikola LisaninPas encore d'évaluation
- Unit-3 TimeDateDocument7 pagesUnit-3 TimeDateVatsal BhalaniPas encore d'évaluation
- Tutorial Crocodile TechnologyDocument4 pagesTutorial Crocodile TechnologyMakustiPas encore d'évaluation
- Reference Guide - Datetime ManipulationDocument6 pagesReference Guide - Datetime Manipulationkhederissa385Pas encore d'évaluation
- Dates and TimesDocument28 pagesDates and TimesGuilherme SoaresPas encore d'évaluation
- R DateAndTimeDocument15 pagesR DateAndTimeK Anantha KrishnanPas encore d'évaluation
- PyQt5 Date and Time - QDate, QTime, QDateTime PDFDocument8 pagesPyQt5 Date and Time - QDate, QTime, QDateTime PDFMarcel ChisPas encore d'évaluation
- SQL Commands 06 Dates 2018 PDFDocument2 pagesSQL Commands 06 Dates 2018 PDFRaisham DahyaPas encore d'évaluation
- Python Date TimeDocument5 pagesPython Date Timemlungisigcabashe44Pas encore d'évaluation
- Don't Send Email Solutions!!!: YEAR (Date), MONTH (Date), DAY (Date)Document2 pagesDon't Send Email Solutions!!!: YEAR (Date), MONTH (Date), DAY (Date)Kevon BvunzaPas encore d'évaluation
- L28 ModulesPackages ExamplesDocument44 pagesL28 ModulesPackages ExamplesAditya SharmaPas encore d'évaluation
- Date Properties: The Following Table Lists The Standard Properties of The Date ObjectDocument3 pagesDate Properties: The Following Table Lists The Standard Properties of The Date ObjectCounter Strike098Pas encore d'évaluation
- Microsoft SQL Server and Sybase Adaptive Server Oracle DescriptionDocument8 pagesMicrosoft SQL Server and Sybase Adaptive Server Oracle DescriptionKarthik RoshanPas encore d'évaluation
- R - Time Intervals - DifferencesDocument3 pagesR - Time Intervals - DifferencesloshudePas encore d'évaluation
- Cognos RS - Functions - 13Document9 pagesCognos RS - Functions - 13Harry KonnectPas encore d'évaluation
- Working With Dates and Times Cheat SheetDocument1 pageWorking With Dates and Times Cheat SheetShrivathsatv ShriPas encore d'évaluation
- Chapter 1Document25 pagesChapter 1AntoPas encore d'évaluation
- Date Object MethodsDocument2 pagesDate Object MethodsmarvinkpxPas encore d'évaluation
- Lecture 15 - JS IIDocument16 pagesLecture 15 - JS IIMariam ChuhdryPas encore d'évaluation
- C++ Classes For Empirical Nancial Data: Bernt Arne Ødegaard April 2007Document32 pagesC++ Classes For Empirical Nancial Data: Bernt Arne Ødegaard April 2007Giuseppe LuongoPas encore d'évaluation
- LubridateDocument25 pagesLubridateavgle eminaPas encore d'évaluation
- Date and Time: What Is Ticks/Timestamping in Python?Document5 pagesDate and Time: What Is Ticks/Timestamping in Python?rahul agarwalPas encore d'évaluation
- Python 3 - Date & TimeDocument8 pagesPython 3 - Date & Timepeace makerPas encore d'évaluation
- Fallsem2022-23 Cse3002 Eth Vl2022230103886 Reference Material II 27-07-2022 Java Script DateobjectsDocument40 pagesFallsem2022-23 Cse3002 Eth Vl2022230103886 Reference Material II 27-07-2022 Java Script DateobjectsArchit KhajuriaPas encore d'évaluation
- L1, L2, L3, L4, AspDocument53 pagesL1, L2, L3, L4, Aspmurtida33Pas encore d'évaluation
- Curso Java Completo: Capítulo: Tópicos Especiais em JavaDocument5 pagesCurso Java Completo: Capítulo: Tópicos Especiais em JavaMatheus RodriguesPas encore d'évaluation
- Programming in Java: Topic: Date Time APIDocument34 pagesProgramming in Java: Topic: Date Time APIAgamPas encore d'évaluation
- Date TimeDocument6 pagesDate TimeMAYUR SAKULEPas encore d'évaluation
- University of Engineering and Technology, TaxilaDocument5 pagesUniversity of Engineering and Technology, Taxilasana abbasPas encore d'évaluation
- PHP Date - Time FunctionsDocument5 pagesPHP Date - Time FunctionsThant ThantPas encore d'évaluation
- Date: 22th July Objective: To Convert An Array of Integers Into Vector ClassDocument13 pagesDate: 22th July Objective: To Convert An Array of Integers Into Vector ClassPramod ShahiPas encore d'évaluation
- Python Datetime: Video: Python Datetime - Work With Dates and TimesDocument16 pagesPython Datetime: Video: Python Datetime - Work With Dates and TimesNoor shahPas encore d'évaluation
- C++ Classes For Empirical Financial Data: Bernt Arne Ødegaard April 2007Document33 pagesC++ Classes For Empirical Financial Data: Bernt Arne Ødegaard April 2007KarlPas encore d'évaluation
- Python Datetime TZ Documentation: Release 0.2Document13 pagesPython Datetime TZ Documentation: Release 0.2Nourchene BensmayaPas encore d'évaluation
- Cognos RS - Functions - 20Document4 pagesCognos RS - Functions - 20Harry KonnectPas encore d'évaluation
- Class Date: All Implemented Interfaces: Direct Known SubclassesDocument17 pagesClass Date: All Implemented Interfaces: Direct Known SubclassesHadi AamirPas encore d'évaluation
- JavaScript Date Methods and PropertiesDocument5 pagesJavaScript Date Methods and PropertiesSambeet SahooPas encore d'évaluation
- Report-Part B - Analog Clock For AllDocument7 pagesReport-Part B - Analog Clock For AllNiraj BavaPas encore d'évaluation
- Python 3.8.1 - Datetime - Basic Date and Time TypesDocument44 pagesPython 3.8.1 - Datetime - Basic Date and Time TypesCarlos VidalPas encore d'évaluation
- 6 BCA BBA Linux CommandsDocument58 pages6 BCA BBA Linux CommandsDhan CPas encore d'évaluation
- VRARAIDocument12 pagesVRARAIraquel mallannnaoPas encore d'évaluation
- SL Generator Ultrasunete RincoDocument2 pagesSL Generator Ultrasunete RincoDariaPas encore d'évaluation
- MegaMacho Drums BT READ MEDocument14 pagesMegaMacho Drums BT READ MEMirkoSashaGoggoPas encore d'évaluation
- Stratum CorneumDocument4 pagesStratum CorneumMuh Firdaus Ar-RappanyPas encore d'évaluation
- Linux ProgramDocument131 pagesLinux ProgramsivashaPas encore d'évaluation
- 5045.CHUYÊN ĐỀDocument8 pages5045.CHUYÊN ĐỀThanh HuyềnPas encore d'évaluation
- Cln4u Task Prisons RubricsDocument2 pagesCln4u Task Prisons RubricsJordiBdMPas encore d'évaluation
- Libya AIP Part1Document145 pagesLibya AIP Part1Hitham Ghwiel100% (1)
- Worked Solution Paper5 A LevelDocument8 pagesWorked Solution Paper5 A LevelBhoosan AncharazPas encore d'évaluation
- Legrand Price List-01 ST April-2014Document144 pagesLegrand Price List-01 ST April-2014Umesh SutharPas encore d'évaluation
- Sage TutorialDocument115 pagesSage TutorialChhakuli GiriPas encore d'évaluation
- 6int 2008 Dec ADocument6 pages6int 2008 Dec ACharles_Leong_3417Pas encore d'évaluation
- Creating A Research Space (C.A.R.S.) ModelDocument5 pagesCreating A Research Space (C.A.R.S.) ModelNazwa MustikaPas encore d'évaluation
- Chemical & Ionic Equilibrium Question PaperDocument7 pagesChemical & Ionic Equilibrium Question PapermisostudyPas encore d'évaluation
- Solutions DPP 2Document3 pagesSolutions DPP 2Tech. VideciousPas encore d'évaluation
- Abas Drug Study Nicu PDFDocument4 pagesAbas Drug Study Nicu PDFAlexander Miguel M. AbasPas encore d'évaluation
- Dependent ClauseDocument28 pagesDependent ClauseAndi Febryan RamadhaniPas encore d'évaluation
- Payment of Wages 1936Document4 pagesPayment of Wages 1936Anand ReddyPas encore d'évaluation