Vous aimerez peut-être aussi
- Delving Deep Into Rectifiers: Surpassing Human-Level Performance On Imagenet ClassificationDocument11 pagesDelving Deep Into Rectifiers: Surpassing Human-Level Performance On Imagenet ClassificationsmisatPas encore d'évaluation
- SocherBauerManningNg ACL2013 PDFDocument11 pagesSocherBauerManningNg ACL2013 PDFSr. RZPas encore d'évaluation
- Distributed DL1602.06709v1Document10 pagesDistributed DL1602.06709v1sharkiePas encore d'évaluation
- Fast Algorithms for CNNs Reduce ComputationDocument9 pagesFast Algorithms for CNNs Reduce ComputationsharkiePas encore d'évaluation
- Adam PDFDocument15 pagesAdam PDFWander ScheideggerPas encore d'évaluation
- AnalysisOfDeepLearning1605 07678v2Document7 pagesAnalysisOfDeepLearning1605 07678v2sharkiePas encore d'évaluation
- End-To-End People Detection in Crowded ScenesDocument9 pagesEnd-To-End People Detection in Crowded ScenessharkiePas encore d'évaluation
- Fast Algorithms for CNNs Reduce ComputationDocument9 pagesFast Algorithms for CNNs Reduce ComputationsharkiePas encore d'évaluation
- SqueezeNet1602 07360Document9 pagesSqueezeNet1602 07360sharkiePas encore d'évaluation
- Masi Pose-Aware Face Recognition CVPR 2016 PaperDocument9 pagesMasi Pose-Aware Face Recognition CVPR 2016 PapersharkiePas encore d'évaluation
- Deep Tracking Seeing Beyond Seeing Using Recurrent Neural Networks 2016AAAI - Ondruska PDFDocument7 pagesDeep Tracking Seeing Beyond Seeing Using Recurrent Neural Networks 2016AAAI - Ondruska PDFsharkiePas encore d'évaluation
- Generalized Haar Filter Based Deep Networks For Real-Time Object Detecti...Document19 pagesGeneralized Haar Filter Based Deep Networks For Real-Time Object Detecti...sharkiePas encore d'évaluation
- Accurate Scale Estimation For Robust Visual TrackingDocument11 pagesAccurate Scale Estimation For Robust Visual TrackingsharkiePas encore d'évaluation
- An Overview of Gradient Descent Optimization Algorithms PDFDocument12 pagesAn Overview of Gradient Descent Optimization Algorithms PDFsharkiePas encore d'évaluation
- Reducing Branch Divergence in GPU ProgramsDocument8 pagesReducing Branch Divergence in GPU ProgramssharkiePas encore d'évaluation
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (119)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Exact Solutions of Lotka Volterra EquationsDocument5 pagesExact Solutions of Lotka Volterra Equationsjjj_ddd_pierrePas encore d'évaluation
- PID StatisticDocument9 pagesPID StatisticyoonginismPas encore d'évaluation
- SOCCER TacticsDocument13 pagesSOCCER Tacticsjohnstone kennedyPas encore d'évaluation
- Applied MathsDocument2 pagesApplied MathsSereneMahPas encore d'évaluation
- M4 Cluster 5 Lec8Document7 pagesM4 Cluster 5 Lec8Neelam PavanPas encore d'évaluation
- Week 1 Introduction To The Limits of A FunctionsDocument27 pagesWeek 1 Introduction To The Limits of A FunctionsDenize KhatePas encore d'évaluation
- Chap 02 Real Analysis: Sequences and SeriesDocument26 pagesChap 02 Real Analysis: Sequences and Seriesatiq4pk86% (7)
- Lesson 31 Linear Differential Equation of Higher Order: Module 3: Ordinary Differential EquationsDocument6 pagesLesson 31 Linear Differential Equation of Higher Order: Module 3: Ordinary Differential EquationsJoseph NjugunaPas encore d'évaluation
- Probability distributions and sampling formulasDocument8 pagesProbability distributions and sampling formulasAlan TruongPas encore d'évaluation
- Class 12 Students Present Math Project on DifferentiationDocument14 pagesClass 12 Students Present Math Project on DifferentiationSayan Mandal69% (16)
- Mathematics Learning AreaDocument188 pagesMathematics Learning AreaHIMMZERLANDPas encore d'évaluation
- Machine Learning Andrew NG Week 5 Quiz 1Document3 pagesMachine Learning Andrew NG Week 5 Quiz 1Hương ĐặngPas encore d'évaluation
- Hypothesis Test - Difference in MeansDocument4 pagesHypothesis Test - Difference in Meansr01852009paPas encore d'évaluation
- Report Card CURIEDocument37 pagesReport Card CURIEHelen Grace Camo MajarasPas encore d'évaluation
- (Applied Optimization 87) Yurii Nesterov (Auth.) - Introductory Lectures On Convex Optimization - A Basic Course-Springer US (2004)Document253 pages(Applied Optimization 87) Yurii Nesterov (Auth.) - Introductory Lectures On Convex Optimization - A Basic Course-Springer US (2004)Bharani DharanPas encore d'évaluation
- Weekly Home Learning Plan - Second Quarter: Grade SubjectDocument6 pagesWeekly Home Learning Plan - Second Quarter: Grade SubjectKara BanzonPas encore d'évaluation
- Question Bank MOD and Indefinite IntegrationDocument15 pagesQuestion Bank MOD and Indefinite IntegrationRAKTIM ROUTHPas encore d'évaluation
- Independent University, Bangladesh SEMESTER: AUTUMN-2020/MGT 340Document3 pagesIndependent University, Bangladesh SEMESTER: AUTUMN-2020/MGT 340Shuvo DattaPas encore d'évaluation
- Forecasting Demand For ServicesDocument14 pagesForecasting Demand For ServicesAru SrivastavaPas encore d'évaluation
- Vector - Matrix CalculusDocument10 pagesVector - Matrix Calculusstd_iutPas encore d'évaluation
- Series InfinitasDocument10 pagesSeries InfinitasBerenice JaimePas encore d'évaluation
- The Strategic Analysis of Business Ecosystems: New Conception and Practical Application of A Research ApproachDocument9 pagesThe Strategic Analysis of Business Ecosystems: New Conception and Practical Application of A Research ApproachSasha KingPas encore d'évaluation
- TEST DESIGN AND DEVELOPMENTDocument8 pagesTEST DESIGN AND DEVELOPMENTMaría Alejandra MartínezPas encore d'évaluation
- Domain, Range, Intercepts. Zeroes and Asymptote of An Exponential FunctionDocument6 pagesDomain, Range, Intercepts. Zeroes and Asymptote of An Exponential FunctionMyla Mae BalalaPas encore d'évaluation
- Specimen Papers 2021 - English PDFDocument122 pagesSpecimen Papers 2021 - English PDFsohamPas encore d'évaluation
- ProbabilityII HW9 SolutionsDocument4 pagesProbabilityII HW9 SolutionsAurivasPas encore d'évaluation
- Signal and System Lecture 18Document18 pagesSignal and System Lecture 18ali_rehman87Pas encore d'évaluation
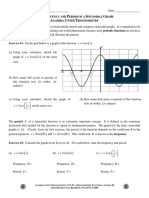
- ALG2 U7L8 The Frequency and Period of A Sinusoidal Graph PDFDocument4 pagesALG2 U7L8 The Frequency and Period of A Sinusoidal Graph PDFAnabbPas encore d'évaluation
- An ANSYS APDL Code For Topology Optimization of Structures With Multi-Constraints Using The BESO Method With Dynamic Evolution Rate (DER-BESO)Document26 pagesAn ANSYS APDL Code For Topology Optimization of Structures With Multi-Constraints Using The BESO Method With Dynamic Evolution Rate (DER-BESO)Jay SrivastavaPas encore d'évaluation
- Qualifying Test - Master Programme in MathematicsDocument7 pagesQualifying Test - Master Programme in MathematicsSyedAhsanKamalPas encore d'évaluation