Vous aimerez peut-être aussi
- RESOLUCIONDocument39 pagesRESOLUCIONCarlos Galvan CorttesPas encore d'évaluation
- Corros Ion en EstructurasDocument64 pagesCorros Ion en EstructurasCarlos Galvan CorttesPas encore d'évaluation
- BECAS CONAcyTDocument11 pagesBECAS CONAcyTMario Arturo HernándezPas encore d'évaluation
- Criterio para InterconexiónDocument26 pagesCriterio para InterconexiónIsmael GarciaPas encore d'évaluation
- 01 - Manual Del Curso - PDF - V 1-3 PDFDocument57 pages01 - Manual Del Curso - PDF - V 1-3 PDFCarlos Galvan CorttesPas encore d'évaluation
- Contrato de Contraprestación Gen DistDocument6 pagesContrato de Contraprestación Gen DistJulio DominguezPas encore d'évaluation
- Dimensionamiento PFVDocument1 pageDimensionamiento PFVCarlos Galvan CorttesPas encore d'évaluation
- 05 - Estudio Tecnico-Economico de Un Caso RealDocument13 pages05 - Estudio Tecnico-Economico de Un Caso RealCarlos Galvan CorttesPas encore d'évaluation
- Principios de CorrosionDocument8 pagesPrincipios de CorrosionCarlos Galvan CorttesPas encore d'évaluation
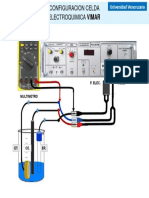
- Configuracion Vimar CORROSIONDocument1 pageConfiguracion Vimar CORROSIONCarlos Galvan CorttesPas encore d'évaluation
- Fundamentos de Proteccion Catodica PDFDocument89 pagesFundamentos de Proteccion Catodica PDFCarlos Galvan CorttesPas encore d'évaluation
- 2013 Corrosion DavidCabreradelaCruzDocument157 pages2013 Corrosion DavidCabreradelaCruzHenny CasanovaPas encore d'évaluation
- TermohidraulicaDocument125 pagesTermohidraulicaCarlos Galvan Corttes100% (1)
- TesisFinal DarioColoradoGarrido CIICApDocument103 pagesTesisFinal DarioColoradoGarrido CIICApErasmo MarquezPas encore d'évaluation
- 05 - Estudio Tecnico-Economico de Un Caso RealDocument13 pages05 - Estudio Tecnico-Economico de Un Caso RealCarlos Galvan CorttesPas encore d'évaluation
- Norma ASTM D1141 Practica Estandar para La Preparacion de Sustituto de Agua de MarDocument7 pagesNorma ASTM D1141 Practica Estandar para La Preparacion de Sustituto de Agua de MarCarlos Galvan CorttesPas encore d'évaluation
- Criterio para InterconexiónDocument26 pagesCriterio para InterconexiónIsmael GarciaPas encore d'évaluation
- OP III Tecnicas Experimentales TEMDocument10 pagesOP III Tecnicas Experimentales TEMCarlos Galvan CorttesPas encore d'évaluation
- Instrucciones de PonenciasDocument1 pageInstrucciones de PonenciasCarlos Galvan CorttesPas encore d'évaluation
- Calendario Tareas-2017Document6 pagesCalendario Tareas-2017Carlos Galvan CorttesPas encore d'évaluation
- Determinacion de NerntsDocument4 pagesDeterminacion de NerntsCarlos Galvan CorttesPas encore d'évaluation
- B6-Problemas Resueltos Tema 2 AlumnosDocument2 pagesB6-Problemas Resueltos Tema 2 AlumnosCarlos Galvan CorttesPas encore d'évaluation
- Metalurgia de CorrosionDocument10 pagesMetalurgia de CorrosionCarlos Galvan CorttesPas encore d'évaluation
- Matematicas AvanzadasDocument3 pagesMatematicas AvanzadasCarlos Galvan CorttesPas encore d'évaluation
- Ejercicios Resueltos Analisis Lineal Series de FourierDocument6 pagesEjercicios Resueltos Analisis Lineal Series de Fourierakibae100% (2)
- Correspond Enc I ADocument2 pagesCorrespond Enc I ACarlos Galvan CorttesPas encore d'évaluation
- Descriccion PGDocument1 pageDescriccion PGCarlos Galvan CorttesPas encore d'évaluation
- Capitulo 1Document3 pagesCapitulo 1Carlos Galvan CorttesPas encore d'évaluation
- Tecnicas ElectroquimicasDocument14 pagesTecnicas ElectroquimicasCarlos Galvan CorttesPas encore d'évaluation
- Fin de II Quimestre Fisica 1ro BguDocument2 pagesFin de II Quimestre Fisica 1ro BguFRANKLIN SAGÑAYPas encore d'évaluation
- Sistemas Hibridos CO2 - AmoniacoDocument89 pagesSistemas Hibridos CO2 - AmoniacoWalter J Naspirán Castañeda100% (1)
- Semana 02Document16 pagesSemana 02Em LePas encore d'évaluation
- Recubrimientos AnticorrosivosDocument75 pagesRecubrimientos AnticorrosivosKarina PrietoPas encore d'évaluation
- 51n Matemáticas VDocument35 pages51n Matemáticas Vjuanchoo calzadaPas encore d'évaluation
- Lista de Precios Ferbras S.A. (Division PVC) HERRAJES - 02 de Abril de 2018Document16 pagesLista de Precios Ferbras S.A. (Division PVC) HERRAJES - 02 de Abril de 2018Pedro Arroyo BelloPas encore d'évaluation
- Juliaca Monografia FinalDocument24 pagesJuliaca Monografia FinalLuis Martínez100% (1)
- Lectura. Principios Básicos de La Ciencia y Desarrollo Histórico de La BiologíaDocument11 pagesLectura. Principios Básicos de La Ciencia y Desarrollo Histórico de La BiologíaRicardo UrrutiaPas encore d'évaluation
- Reuso Del Espacio Patrimonial y Sociedad CivilDocument33 pagesReuso Del Espacio Patrimonial y Sociedad CivilJorge Ortiz ColomPas encore d'évaluation
- 4.3 Balanceo Dinámico en Uno y Dos Planos Por El Método de Coeficientes de InfluenciaDocument22 pages4.3 Balanceo Dinámico en Uno y Dos Planos Por El Método de Coeficientes de InfluenciaEnrique FanesPas encore d'évaluation
- Barredora BrochureDocument6 pagesBarredora BrochureJULIO EFRAIN DIAZ CABRERAPas encore d'évaluation
- Una Aprox. Fenomenologica Al PaisajeDocument8 pagesUna Aprox. Fenomenologica Al PaisajeJulio Navarro GarmaPas encore d'évaluation
- VIH SidaDocument5 pagesVIH SidaAbi Dennise Nahuelpán LienlafPas encore d'évaluation
- 1967 de 1995Document8 pages1967 de 1995api-258519048Pas encore d'évaluation
- Etapas de La Revolucion IndustrialDocument5 pagesEtapas de La Revolucion IndustrialDaniel Ricardo Garcia BaizPas encore d'évaluation
- Documento Sin Título-1Document5 pagesDocumento Sin Título-1Julio Michael Condori ColquePas encore d'évaluation
- Curso Diseño y Fabricación de MUEBLES EN MELAMINADocument25 pagesCurso Diseño y Fabricación de MUEBLES EN MELAMINAArq Arq Arq100% (3)
- TripticoDocument2 pagesTripticoCristian Brisko VolvoPas encore d'évaluation
- 6 Drixonian WarriorDocument333 pages6 Drixonian Warriorjessica bustamantePas encore d'évaluation
- Revista Estudios Publicos 116Document378 pagesRevista Estudios Publicos 116OmarPas encore d'évaluation
- F-CYE-047 Registro de Instalación de Bandejas - Rev2Document3 pagesF-CYE-047 Registro de Instalación de Bandejas - Rev2Carlo Lara100% (1)
- PreguntasDocument3 pagesPreguntasMatilde Del C. EcheversPas encore d'évaluation
- Fondo de Producción Limpia y Aspectos de Una AuditoriaDocument24 pagesFondo de Producción Limpia y Aspectos de Una AuditoriaIgor Alejandro BustosPas encore d'évaluation
- Metrado D DesagueDocument140 pagesMetrado D Desaguehxsey cryPas encore d'évaluation
- Recepción y Almacenamiento de Materia PrimaDocument11 pagesRecepción y Almacenamiento de Materia PrimaalcidesPas encore d'évaluation
- Investigacion Operativa I - Practica #1 - ADMDocument1 pageInvestigacion Operativa I - Practica #1 - ADMisraelPas encore d'évaluation
- Fármacos Del Sistema Nervioso Central-1Document5 pagesFármacos Del Sistema Nervioso Central-1Jhon Alex CardenasPas encore d'évaluation
- Las Torturas Más Crueles de La InquisiciónDocument6 pagesLas Torturas Más Crueles de La InquisiciónARquitectura UMGPas encore d'évaluation
- Estudio Topografico OkDocument7 pagesEstudio Topografico OkAngel Raymundo HuertoPas encore d'évaluation
- Trabalenguas para 4° Grado de Educacion PrimariaDocument20 pagesTrabalenguas para 4° Grado de Educacion PrimariaProfrFerPas encore d'évaluation