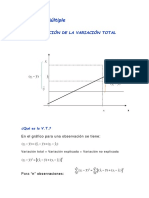
Vous aimerez peut-être aussi
- Diseno de Armaduras de MaderaDocument25 pagesDiseno de Armaduras de MaderaAlbert CarreraPas encore d'évaluation
- Workbook Reto de La MariposaDocument14 pagesWorkbook Reto de La MariposaCarolina Castro V100% (1)
- El CerebroDocument20 pagesEl CerebroRoberto Montaña BeltranPas encore d'évaluation
- Taller 13 resuelto paso a pasoDocument6 pagesTaller 13 resuelto paso a pasoFrancisca RojasPas encore d'évaluation
- Distribuciones de probabilidad discretas y continuasDocument1 pageDistribuciones de probabilidad discretas y continuasAlexis V. Bedolla100% (1)
- 2.5 Determinación Del Tamaño de Una MuestraDocument7 pages2.5 Determinación Del Tamaño de Una MuestraGuillermo Regalado50% (2)
- Formulario Estadística II - 1ra Parcial PDFDocument1 pageFormulario Estadística II - 1ra Parcial PDFJuniorChancoPas encore d'évaluation
- Procedimiento Traslado y Montaja de ModulosDocument9 pagesProcedimiento Traslado y Montaja de ModulosPato VeraPas encore d'évaluation
- Provincia Cordillera Santa Cruz-BoliviaDocument11 pagesProvincia Cordillera Santa Cruz-BoliviaDaniela Escobar Blacutt100% (2)
- Estructura y Mecanismos de Las Enzimas. Cofactores y Coenzimas. Función Biológica y Control de La Actividad.Document6 pagesEstructura y Mecanismos de Las Enzimas. Cofactores y Coenzimas. Función Biológica y Control de La Actividad.Marina100% (1)
- Manual Del Rio V-Star 650 2001Document104 pagesManual Del Rio V-Star 650 2001paco_leon_698618100% (2)
- Fórmulas HipótesisDocument1 pageFórmulas HipótesisSantiago Mendoza0% (2)
- Muestreo EstatificadoDocument6 pagesMuestreo EstatificadoAlbert VazquezPas encore d'évaluation
- 1.5 Medidas de Dispersion AsimetriaDocument35 pages1.5 Medidas de Dispersion AsimetriaIsmael Gonzales RevillaPas encore d'évaluation
- Regresion Anova 1Document6 pagesRegresion Anova 1Dannis Omar Campos ZavaletaPas encore d'évaluation
- Formulario 2 Estadística IIDocument1 pageFormulario 2 Estadística IIGian Carlos MezaPas encore d'évaluation
- REGRESIÓN Y PRUEBAS NO PARAMÉTRICASDocument1 pageREGRESIÓN Y PRUEBAS NO PARAMÉTRICASArnold Frank López MejiaPas encore d'évaluation
- Sesión Medidas de VariabilidadDocument37 pagesSesión Medidas de VariabilidadAlfredo Cossio ValentinPas encore d'évaluation
- Estimación Por Maxima VerosimilitudDocument2 pagesEstimación Por Maxima Verosimilitudalejandra ruizPas encore d'évaluation
- Fórmulas Talleres Estadística IiDocument2 pagesFórmulas Talleres Estadística IikeliPas encore d'évaluation
- Clase 4.1Document14 pagesClase 4.1ACe BlShPas encore d'évaluation
- Pranctica N 1 Ley de HoockeDocument6 pagesPranctica N 1 Ley de HoockeGustavo J. EsquivelPas encore d'évaluation
- Tema 4Document21 pagesTema 4MauricioPas encore d'évaluation
- Formulario de Muestreo Tc3Document13 pagesFormulario de Muestreo Tc3Luis Xavier100% (1)
- Transformada de Fourier de Tiempo DiscretoDocument6 pagesTransformada de Fourier de Tiempo DiscretoDerrick Miguel SernaPas encore d'évaluation
- Diseño y Análisis de ExperimentosDocument36 pagesDiseño y Análisis de ExperimentosLUIS JOAQUIN AYALA GALLARDOPas encore d'évaluation
- Practica 12Document3 pagesPractica 12Tania LeónPas encore d'évaluation
- TAREA - III - UNIDAD - MM202 - Calculo 2Document3 pagesTAREA - III - UNIDAD - MM202 - Calculo 2Emilio PinedaPas encore d'évaluation
- Resumen De Intervalos De Confianza: μ es (x nDocument7 pagesResumen De Intervalos De Confianza: μ es (x nFrancisca Poblete PierattiniPas encore d'évaluation
- Analisis de VarianzaDocument110 pagesAnalisis de VarianzaAntonio ReyesPas encore d'évaluation
- Diferencia de mediasDocument15 pagesDiferencia de mediasLuis FdPas encore d'évaluation
- Medidas de DispersionDocument35 pagesMedidas de DispersionNarcisoPas encore d'évaluation
- I Distrib Varianza MuestralDocument3 pagesI Distrib Varianza Muestraldiegomonti247Pas encore d'évaluation
- Sesión 09 - Medidas de Variabilidad - Varianza y Desviación EstandarDocument33 pagesSesión 09 - Medidas de Variabilidad - Varianza y Desviación EstandarMarco López ChilcaPas encore d'évaluation
- Intervalos de Confianza PDFDocument58 pagesIntervalos de Confianza PDFDavid AyalaPas encore d'évaluation
- Forumalrio Muestreo Estratificado 2023Document6 pagesForumalrio Muestreo Estratificado 2023Eleana ZamoraPas encore d'évaluation
- Formulario 1 Estadística IIDocument1 pageFormulario 1 Estadística IIGian Carlos MezaPas encore d'évaluation
- Prueba de Hipótesis Muestras Independientes y DependientesDocument25 pagesPrueba de Hipótesis Muestras Independientes y DependientesFabiola SilvaPas encore d'évaluation
- Microsoft Word - Formulas EIIDocument2 pagesMicrosoft Word - Formulas EIIThiago CabuliPas encore d'évaluation
- 2 Formulas Tablas 2016Document7 pages2 Formulas Tablas 2016Alejandro SjPas encore d'évaluation
- Taller 3 CALCULO IIDocument4 pagesTaller 3 CALCULO IIEIEEPas encore d'évaluation
- Taller 2 Calculo IiDocument4 pagesTaller 2 Calculo IiEIEEPas encore d'évaluation
- Taller 2 Calculo IIDocument4 pagesTaller 2 Calculo IIMatias FierroPas encore d'évaluation
- Medidas de Posición y Tendencia CentralDocument51 pagesMedidas de Posición y Tendencia CentralJean ElverPas encore d'évaluation
- LeyHooke - Ajuste Lineal - PresentaciónDocument20 pagesLeyHooke - Ajuste Lineal - PresentaciónGiovanni Cruz LópezPas encore d'évaluation
- LaboDocument6 pagesLaboAprovador de PaginasPas encore d'évaluation
- Estimación de parámetros en distribuciones de probabilidadDocument7 pagesEstimación de parámetros en distribuciones de probabilidadDavid AhumadaPas encore d'évaluation
- Taller Integrador PH2102020Document3 pagesTaller Integrador PH2102020Jorge OrozcoPas encore d'évaluation
- ContrastesDocument56 pagesContrastesLeonardo ArbeláezPas encore d'évaluation
- Docima de Diferencia de VarianzasDocument3 pagesDocima de Diferencia de VarianzasPeñafiel Rojas Kimberly RosarioPas encore d'évaluation
- Apoyo Sem 13 Cuantificacion de Cambios AcumuladosDocument4 pagesApoyo Sem 13 Cuantificacion de Cambios AcumuladosLuis Rodrigo Zazueta MedinaPas encore d'évaluation
- Listado 8 SucesionesDocument2 pagesListado 8 SucesionesAlejandro BurkhardtPas encore d'évaluation
- Formulario Distribuciones MuestralesDocument2 pagesFormulario Distribuciones MuestralesFIORELLA LIPas encore d'évaluation
- Unidad 1 - BibliografíaDocument12 pagesUnidad 1 - BibliografíaSebastian AlvarezPas encore d'évaluation
- Series infinitas: generalidades y criterios de convergenciaDocument4 pagesSeries infinitas: generalidades y criterios de convergenciaRonny Alexander Dominguez UtrerasPas encore d'évaluation
- Intervalos de Confianza-1Document11 pagesIntervalos de Confianza-1Kaai CabreraPas encore d'évaluation
- Formulas Regresic3b3n y Correlacic3b3n 2018Document4 pagesFormulas Regresic3b3n y Correlacic3b3n 2018ivan RicaldezPas encore d'évaluation
- Formulariodeintervalosdeconfianza 2012 21 130121111558 Phpapp02Document2 pagesFormulariodeintervalosdeconfianza 2012 21 130121111558 Phpapp02Lautaro RojasPas encore d'évaluation
- Formulario de muestreo en poblaciones finitas e infinitasDocument9 pagesFormulario de muestreo en poblaciones finitas e infinitasA Max Ricardo HerediaPas encore d'évaluation
- Ingeniería Química Análisis Instrumental Rendimiento FluorescenciaDocument4 pagesIngeniería Química Análisis Instrumental Rendimiento FluorescenciaCarlos Bruno TolenPas encore d'évaluation
- Intervalos ConfianzaDocument20 pagesIntervalos ConfianzaJXanath Hyun JoongPas encore d'évaluation
- Formulario Del Intervalo de ConfianzaDocument1 pageFormulario Del Intervalo de ConfianzaJasmin SaavedraPas encore d'évaluation
- Cocientes NotableDocument2 pagesCocientes NotableDalia MedalitPas encore d'évaluation
- Formulario y Tablas - Estadística Inferencial PDFDocument11 pagesFormulario y Tablas - Estadística Inferencial PDFAnii SuarezPas encore d'évaluation
- Distribución MCO estimadoresDocument40 pagesDistribución MCO estimadoresPAOLA RIVAS GARCIAPas encore d'évaluation
- F02 - InferenciaDocument2 pagesF02 - Inferenciajuan pablo ClavijoPas encore d'évaluation
- Bolaños - Castro - Carvajal - Oviedo - Perugachi - NRC4958 Propuesta Sga Grupo 02Document26 pagesBolaños - Castro - Carvajal - Oviedo - Perugachi - NRC4958 Propuesta Sga Grupo 02Lizz Frizz RockPas encore d'évaluation
- GODOY - LIZETH - Orden de Los Cauces y de La Red (Modelo de Strahler)Document3 pagesGODOY - LIZETH - Orden de Los Cauces y de La Red (Modelo de Strahler)Lizz Frizz RockPas encore d'évaluation
- Manual básico para estimar riesgo ambientalDocument1 pageManual básico para estimar riesgo ambientalLizz Frizz RockPas encore d'évaluation
- Asimbaya - Farinango - Lema - Trujillo - Veloz - Yasaca - Sistema de Gestión AmbientalDocument4 pagesAsimbaya - Farinango - Lema - Trujillo - Veloz - Yasaca - Sistema de Gestión AmbientalLizz Frizz RockPas encore d'évaluation
- Estudio Del Uso Del Lodo Residual de La Empresa Extralum S. A. Como Material Alternativo en La Fabricación de Cementos EspecialesDocument10 pagesEstudio Del Uso Del Lodo Residual de La Empresa Extralum S. A. Como Material Alternativo en La Fabricación de Cementos EspecialesLizz Frizz RockPas encore d'évaluation
- Taller 12.1Document3 pagesTaller 12.1Lizz Frizz RockPas encore d'évaluation
- Epa 4Document30 pagesEpa 4Lizz Frizz RockPas encore d'évaluation
- Epa 5Document24 pagesEpa 5Lizz Frizz RockPas encore d'évaluation
- Mapa Conceptual 07 Ale - DigitaalDocument4 pagesMapa Conceptual 07 Ale - DigitaalLizz Frizz RockPas encore d'évaluation
- Implementación ISO 14001 Central Hidroeléctrica GuangopoloDocument27 pagesImplementación ISO 14001 Central Hidroeléctrica GuangopoloLizz Frizz RockPas encore d'évaluation
- Capilla de Villacis 3dDocument9 pagesCapilla de Villacis 3dLizz Frizz RockPas encore d'évaluation
- Análisis de Estudios Multitemporales - Resultados - BorradorDocument12 pagesAnálisis de Estudios Multitemporales - Resultados - BorradorLizz Frizz RockPas encore d'évaluation
- Utilizacindela Pipetade Robinsonparaelanlisistexturalensuelosdela Provinciade Entre RosDocument5 pagesUtilizacindela Pipetade Robinsonparaelanlisistexturalensuelosdela Provinciade Entre RosLizz Frizz RockPas encore d'évaluation
- Reformas a la LOEI y la Unión Nacional de EducadoresDocument3 pagesReformas a la LOEI y la Unión Nacional de EducadoresLizz Frizz RockPas encore d'évaluation
- Bolaños Practica1Document20 pagesBolaños Practica1Lizz Frizz RockPas encore d'évaluation
- Universidad Central Del Ecuador TI 8.2Document1 pageUniversidad Central Del Ecuador TI 8.2Lizz Frizz RockPas encore d'évaluation
- Trabajo IndividualDocument2 pagesTrabajo IndividualLizz Frizz RockPas encore d'évaluation
- Generación de La Cartografía BásicaDocument11 pagesGeneración de La Cartografía BásicaLizz Frizz RockPas encore d'évaluation
- AGUIAR-Infografía Vertedero de BasuraDocument2 pagesAGUIAR-Infografía Vertedero de BasuraLizz Frizz RockPas encore d'évaluation
- Tarea Microensayo Nicole Godoy 002Document2 pagesTarea Microensayo Nicole Godoy 002Lizz Frizz RockPas encore d'évaluation
- Liceo Naval - ManzanasDocument1 pageLiceo Naval - ManzanasLizz Frizz RockPas encore d'évaluation
- Cruz Cruz Imbaquingo León Cervantes Proyecto Final III ParcialDocument19 pagesCruz Cruz Imbaquingo León Cervantes Proyecto Final III ParcialLizz Frizz RockPas encore d'évaluation
- Trabajo IndividualDocument2 pagesTrabajo IndividualLizz Frizz RockPas encore d'évaluation
- Informe Técnico Ruta Ciudades 14-38Document12 pagesInforme Técnico Ruta Ciudades 14-38Lizz Frizz RockPas encore d'évaluation
- AGUIAR - Informe Vertedero BasuraDocument12 pagesAGUIAR - Informe Vertedero BasuraLizz Frizz RockPas encore d'évaluation
- Poster - Ruta Más Optima Desde Chacopamba A Huagra RanchoDocument1 pagePoster - Ruta Más Optima Desde Chacopamba A Huagra RanchoLizz Frizz RockPas encore d'évaluation
- Crespo Ortega PosterDocument1 pageCrespo Ortega PosterLizz Frizz RockPas encore d'évaluation
- Trabajo IndividualDocument2 pagesTrabajo IndividualLizz Frizz RockPas encore d'évaluation
- SextoDocument3 pagesSextoLizz Frizz RockPas encore d'évaluation
- Acelerar Reacciones Químicas MedianteDocument4 pagesAcelerar Reacciones Químicas MedianteLizz Frizz RockPas encore d'évaluation
- Alcoholismo en El Colegio Montufar de Quito EcuadorDocument50 pagesAlcoholismo en El Colegio Montufar de Quito EcuadorGalo Quintana50% (2)
- Asistencia en Fisioterapia y Rehabilitación Clase 4Document16 pagesAsistencia en Fisioterapia y Rehabilitación Clase 4Lindsay MaytaPas encore d'évaluation
- Seminario Planificación FamiliarDocument1 pageSeminario Planificación FamiliarDiego PinzonPas encore d'évaluation
- Norberto Chaves PDFDocument94 pagesNorberto Chaves PDFGigibPas encore d'évaluation
- 9º Mat e 23 AgostoDocument2 pages9º Mat e 23 Agostokko-hector SilveroPas encore d'évaluation
- Calcul Bigues I Pilars Fusta MassissaDocument16 pagesCalcul Bigues I Pilars Fusta Massissammmarc_Pas encore d'évaluation
- Capitulo 15 Terminaciones Nivel IIDocument39 pagesCapitulo 15 Terminaciones Nivel IIIngeniero Angeles Miranda BustamantePas encore d'évaluation
- Distribución planta ingenieríaDocument16 pagesDistribución planta ingenieríaMarcos VC100% (1)
- HS-S-58 01 Espacios ConfinadosDocument16 pagesHS-S-58 01 Espacios ConfinadosOscar Eduardo Valladares LopezPas encore d'évaluation
- Práctica 4Document7 pagesPráctica 4Fernanda TorresPas encore d'évaluation
- 2 - Etapa - 3Document35 pages2 - Etapa - 3Juan David EcheverryPas encore d'évaluation
- Losa en Una DirecciónDocument6 pagesLosa en Una DirecciónVictor Gutierrez CruzPas encore d'évaluation
- El Otro Amenazante y La CuraDocument15 pagesEl Otro Amenazante y La CuraCarlos AlbertoPas encore d'évaluation
- Spencer Primeros PrincipiosDocument10 pagesSpencer Primeros Principiosrafanob82100% (1)
- Proyecto Educativo Davinci 2021 FinalDocument23 pagesProyecto Educativo Davinci 2021 Finalian fuentesPas encore d'évaluation
- Taller de Educación Sexual Integral - Mitos SexualesDocument9 pagesTaller de Educación Sexual Integral - Mitos SexualesvaleriaPas encore d'évaluation
- GermanioDocument2 pagesGermanioMay RomeroPas encore d'évaluation
- Circulación TermohalinaDocument4 pagesCirculación TermohalinaDiego Guillen GuillenPas encore d'évaluation
- Inf. Pruebas Met - Arturo MusirisDocument3 pagesInf. Pruebas Met - Arturo MusirisJeanpierre TorreblancaPas encore d'évaluation
- Todo para El Aula 2DO CICLO - ABRIL 2019Document134 pagesTodo para El Aula 2DO CICLO - ABRIL 2019Gloria FloresPas encore d'évaluation
- Inmunidad en Trasplantes USMP2014Document18 pagesInmunidad en Trasplantes USMP2014TatiFernandezPas encore d'évaluation
- Triptico CancerDocument2 pagesTriptico CancerdenisguillePas encore d'évaluation
- PDFServletDocument2 pagesPDFServletIvan Hernandez BecerraPas encore d'évaluation