Vous aimerez peut-être aussi
- Header IODocument12 pagesHeader IOSandyPas encore d'évaluation
- Secure C CodingDocument62 pagesSecure C Codingjagadish12Pas encore d'évaluation
- 02 Essential C Security 101Document76 pages02 Essential C Security 101ksmaheshkumarPas encore d'évaluation
- Avr-Libc Avr-Pgmspace - H Program Space UtilitiesDocument11 pagesAvr-Libc Avr-Pgmspace - H Program Space UtilitiesJesus GarzaPas encore d'évaluation
- MIT6 087IAP10 Lec04Document31 pagesMIT6 087IAP10 Lec04umuthumalaPas encore d'évaluation
- Unit - 4Document3 pagesUnit - 4abhishekthummar6Pas encore d'évaluation
- C/C++ Standard I/ODocument6 pagesC/C++ Standard I/OSerban PetrescuPas encore d'évaluation
- C ProgrammingDocument56 pagesC ProgrammingHaritha rajeswari1810Pas encore d'évaluation
- Text Input / Output:: Programming For Problem Solving Using C Unit-VDocument12 pagesText Input / Output:: Programming For Problem Solving Using C Unit-VNaresh BabuPas encore d'évaluation
- C ProgrammingDocument125 pagesC ProgrammingPrafful SomaniPas encore d'évaluation
- DTC Unicode ProgrammingDocument14 pagesDTC Unicode Programmingheckle1Pas encore d'évaluation
- Coroutines in CDocument6 pagesCoroutines in Cadalberto soplatetasPas encore d'évaluation
- CH12Document87 pagesCH12Sam VPas encore d'évaluation
- The Computer Journal 1972 Stoy 195 203Document9 pagesThe Computer Journal 1972 Stoy 195 203Ridho AfwanPas encore d'évaluation
- C Programming Language TutorialDocument45 pagesC Programming Language TutorialAyushi ShrivastavaPas encore d'évaluation
- CodeVisionAVR User Manual (13tr)Document13 pagesCodeVisionAVR User Manual (13tr)Nhân Mã HiềnPas encore d'évaluation
- C Programming Standard I o Print Fs Can FDocument68 pagesC Programming Standard I o Print Fs Can FkvsrvzmPas encore d'évaluation
- C Standard LibrariesDocument9 pagesC Standard LibrariesJimmy GomezPas encore d'évaluation
- AmberTools13 Cpptraj PtrajDocument91 pagesAmberTools13 Cpptraj PtrajmayankgiaPas encore d'évaluation
- Pep 8 PaperDocument5 pagesPep 8 PaperBrent ButlerPas encore d'évaluation
- Advanced Use of C Language: ContentDocument23 pagesAdvanced Use of C Language: ContentsybaritzPas encore d'évaluation
- 21bee0278 Da 2Document8 pages21bee0278 Da 2Raynier SenpaiPas encore d'évaluation
- Waside SseDocument20 pagesWaside SsesunbeamPas encore d'évaluation
- C TutorDocument15 pagesC Tutorjangid_ramPas encore d'évaluation
- King Fahd University of Petroleum and Minerals: Information & Computer Science DepartmentDocument8 pagesKing Fahd University of Petroleum and Minerals: Information & Computer Science DepartmentarabsamaPas encore d'évaluation
- CPDS MaterialDocument167 pagesCPDS MaterialSesha Sai KumarPas encore d'évaluation
- LibquadmathDocument26 pagesLibquadmathJJAJJPas encore d'évaluation
- Part 2: Benchmarks and Case Studies of Forth Kernels: by Brad RodriguezDocument1 pagePart 2: Benchmarks and Case Studies of Forth Kernels: by Brad Rodriguezmichael0richt-880205Pas encore d'évaluation
- Matlab CheatsheetDocument2 pagesMatlab CheatsheetEphraimSongPas encore d'évaluation
- MIT6 087IAP10 Assn03Document7 pagesMIT6 087IAP10 Assn03JHON LIZARAZOPas encore d'évaluation
- 2 Marks Q&A, 16 Mark Q - NPMDocument25 pages2 Marks Q&A, 16 Mark Q - NPMearth2hellotherePas encore d'évaluation
- AutoLISP Programming TechniquesDocument63 pagesAutoLISP Programming TechniquesioanPas encore d'évaluation
- C and Data Structures - BalaguruswamyDocument52 pagesC and Data Structures - BalaguruswamyShrey Khokhawat100% (2)
- Introduction Cand CDocument22 pagesIntroduction Cand CBa Thanh DinhPas encore d'évaluation
- CMSC 313 Final Practice Questions Fall 2009Document6 pagesCMSC 313 Final Practice Questions Fall 2009Ravi TejPas encore d'évaluation
- C Progragramming Language Tutorial PPT FDocument47 pagesC Progragramming Language Tutorial PPT FTharun kondaPas encore d'évaluation
- Scripting Langauge For DynaDocument117 pagesScripting Langauge For DynahellobigPas encore d'évaluation
- Chapter 2Document7 pagesChapter 2truptiPas encore d'évaluation
- Programming in CDocument110 pagesProgramming in CArun BaralPas encore d'évaluation
- Progress Report: Kristoffer Rosén September 25, 2012Document16 pagesProgress Report: Kristoffer Rosén September 25, 2012kristoffer_rose7812Pas encore d'évaluation
- Turbo C LectureDocument14 pagesTurbo C LecturebanglecowboyPas encore d'évaluation
- CCS0007 - Laboratory Exercise 5Document9 pagesCCS0007 - Laboratory Exercise 5LAWRENCE CALZADOPas encore d'évaluation
- NP Lab MANUALDocument40 pagesNP Lab MANUALsuryavamsi kakaraPas encore d'évaluation
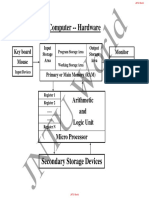
- Computer - Hardware: Arithmetic and Logic UnitDocument24 pagesComputer - Hardware: Arithmetic and Logic UnitBabuPas encore d'évaluation
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationD'EverandPractical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationPas encore d'évaluation
- Learn C Programming through Nursery Rhymes and Fairy Tales: Classic Stories Translated into C ProgramsD'EverandLearn C Programming through Nursery Rhymes and Fairy Tales: Classic Stories Translated into C ProgramsPas encore d'évaluation
- Modern Introduction to Object Oriented Programming for Prospective DevelopersD'EverandModern Introduction to Object Oriented Programming for Prospective DevelopersPas encore d'évaluation
- Servlet Session I: Cookie APIDocument26 pagesServlet Session I: Cookie APISmita BorkarPas encore d'évaluation
- PracticesGuide - Ethernet Send Receive Data - Rev.ADocument23 pagesPracticesGuide - Ethernet Send Receive Data - Rev.Ajunior cezarPas encore d'évaluation
- Top 100 PHP Interview Questions and Answers Are Below 120816023558 Phpapp01Document26 pagesTop 100 PHP Interview Questions and Answers Are Below 120816023558 Phpapp01Ashok MadineniPas encore d'évaluation
- 3GPP TS 29.415Document15 pages3GPP TS 29.415NguyenDucTaiPas encore d'évaluation
- Chapter 12 MCQs in Multiple AccessDocument14 pagesChapter 12 MCQs in Multiple AccessIan Von ArandiaPas encore d'évaluation
- Mikrotik PDFDocument337 pagesMikrotik PDFdika8Pas encore d'évaluation
- (700 Million Records) Database (2022)Document56 pages(700 Million Records) Database (2022)Juan Hernandez40% (5)
- Overall DWH Concepts HandbookDocument27 pagesOverall DWH Concepts HandbookFelipe CordeiroPas encore d'évaluation
- Lecture 1 XML IntroductionDocument64 pagesLecture 1 XML IntroductionVinit Vini JainPas encore d'évaluation
- DX DiagDocument8 pagesDX DiagSanata BangunPas encore d'évaluation
- B08DC9ZWQXDocument551 pagesB08DC9ZWQXanisPas encore d'évaluation
- Sera Gem 0022001Document13 pagesSera Gem 0022001Sunil YadavPas encore d'évaluation
- MIS Lego PresentationDocument13 pagesMIS Lego PresentationShubashini Mathyalingam0% (1)
- IMS Status CodeDocument5 pagesIMS Status Codedirceu_bimontiPas encore d'évaluation
- Pin Diagram of 8086Document34 pagesPin Diagram of 8086vinayaaaPas encore d'évaluation
- Hi3516A Professional HD IP Camera SoC Brief Data SheetDocument7 pagesHi3516A Professional HD IP Camera SoC Brief Data Sheetco_stel817842Pas encore d'évaluation
- Application Server Using ABAPDocument7 pagesApplication Server Using ABAPSai KumarPas encore d'évaluation
- Chapter 9 - LAB - Database SecurityDocument8 pagesChapter 9 - LAB - Database SecurityThy TrânPas encore d'évaluation
- WWW Movable Type Co Uk Scripts Sha256 HTMLDocument2 pagesWWW Movable Type Co Uk Scripts Sha256 HTMLBenny LangstonPas encore d'évaluation
- Syllabus RGPVDocument5 pagesSyllabus RGPVकिशोरी जूPas encore d'évaluation
- Blueprism QuestionsDocument24 pagesBlueprism Questionsdhivya2451989Pas encore d'évaluation
- 3 DTiles in ActionDocument42 pages3 DTiles in ActionEduardo NunoPas encore d'évaluation
- What Is A Hard Disk DriveDocument19 pagesWhat Is A Hard Disk DriveGladis PulanPas encore d'évaluation
- Module 1: Infrastructure and Capacity Planning For Microsoft Dynamics Ax 2012 Module OverviewDocument34 pagesModule 1: Infrastructure and Capacity Planning For Microsoft Dynamics Ax 2012 Module OverviewBobby PratomoPas encore d'évaluation
- DA 100 Mod2 ENU PowerPointDocument25 pagesDA 100 Mod2 ENU PowerPointmagiwarePas encore d'évaluation
- SIU CMD, Backup and Replacement MOPDocument2 pagesSIU CMD, Backup and Replacement MOPAzea ADAPas encore d'évaluation
- Port Server SEL-3610Document8 pagesPort Server SEL-3610Nguyễn Tuấn ViệtPas encore d'évaluation
- Wireshark Basics Self StudyDocument51 pagesWireshark Basics Self StudymzyptPas encore d'évaluation
- Archiving SynonymsDocument300 pagesArchiving SynonymsRockey ZapPas encore d'évaluation
- 3-Distribution DesignDocument66 pages3-Distribution Designmba20238Pas encore d'évaluation