Vous aimerez peut-être aussi
- Anotaciones TESORERIADocument2 pagesAnotaciones TESORERIAandreaPas encore d'évaluation
- Caso FinalDocument13 pagesCaso FinalandreaPas encore d'évaluation
- Ejercicios EstadisticaDocument9 pagesEjercicios EstadisticaandreaPas encore d'évaluation
- Ejercicios EstadisticaDocument9 pagesEjercicios EstadisticaandreaPas encore d'évaluation
- Ejercicios Segundo QuizDocument14 pagesEjercicios Segundo QuizandreaPas encore d'évaluation
- Notas de Design ThinkingDocument2 pagesNotas de Design ThinkingandreaPas encore d'évaluation
- Variable Volume Pumping FundamentalsDocument16 pagesVariable Volume Pumping Fundamentalsadca100% (1)
- Ciclo de DieselDocument10 pagesCiclo de DieselEver PadillaPas encore d'évaluation
- Nissan Estacas 2021Document3 pagesNissan Estacas 2021Aldo EsparzaPas encore d'évaluation
- Desarrollo PuberalDocument7 pagesDesarrollo PuberalAlonso ChipanaPas encore d'évaluation
- CS 2do Estudiante Ubicacion EspacialDocument8 pagesCS 2do Estudiante Ubicacion EspacialVentas CoquimboPas encore d'évaluation
- LibroprimeroDocument194 pagesLibroprimeroWENBO TANPas encore d'évaluation
- Induccion 2021Document127 pagesInduccion 2021Sebastián HernandezPas encore d'évaluation
- InglesDocument4 pagesInglesMartha LePas encore d'évaluation
- Elevar 1 Mentalidad y NichoDocument8 pagesElevar 1 Mentalidad y NichoPamela RaveraPas encore d'évaluation
- Manual de Almacén y DespachoDocument62 pagesManual de Almacén y DespachoPaulo Stefan Huerta DE LA VegaPas encore d'évaluation
- Paso 2 - Importancia de La Psicometría y La Variable AsignadaDocument8 pagesPaso 2 - Importancia de La Psicometría y La Variable AsignadaViviana ChaconPas encore d'évaluation
- Maria Tesis Titulo 2019Document113 pagesMaria Tesis Titulo 2019Judith Angelica TCPas encore d'évaluation
- CV Sheyla Porras Huaman 2023Document18 pagesCV Sheyla Porras Huaman 2023Alonso Cubas GuzmánPas encore d'évaluation
- Geometría PlanaDocument4 pagesGeometría PlanaEdson André Cortés SilvaPas encore d'évaluation
- Respuesta en Frecuencia de Un Sistema DiscretoDocument5 pagesRespuesta en Frecuencia de Un Sistema DiscretoKarlitosmanPas encore d'évaluation
- Catalogos SCHNORRDocument44 pagesCatalogos SCHNORRjaropePas encore d'évaluation
- Ori and the Blind Forest: Análisis del aclamado Metroidvania de Moon StudiosDocument3 pagesOri and the Blind Forest: Análisis del aclamado Metroidvania de Moon StudiosAndrés Bandera RojasPas encore d'évaluation
- VALENCIANO PLAZA, José Luis - Educación PlásticaDocument317 pagesVALENCIANO PLAZA, José Luis - Educación PlásticaJonatan Lubo100% (1)
- Copia de Planeador 2023 ParvulosDocument183 pagesCopia de Planeador 2023 ParvulosLUZ YANETH VARGASPas encore d'évaluation
- Original Deshidratacion HipernatremicaDocument13 pagesOriginal Deshidratacion HipernatremicaJuampyVillaPas encore d'évaluation
- Trabajo Diseño de Obras Hidraulicas 2Document32 pagesTrabajo Diseño de Obras Hidraulicas 2Yhonatan Gaspar ReyesPas encore d'évaluation
- Framedia ADocument13 pagesFramedia ASara Jimenez RodriguezPas encore d'évaluation
- Ficha Tecnica Porcelanato Nuevo Boss Gris ClaroDocument2 pagesFicha Tecnica Porcelanato Nuevo Boss Gris ClarojaesPas encore d'évaluation
- TA3 - Direccion Financiera - Grupo N°1.....Document19 pagesTA3 - Direccion Financiera - Grupo N°1.....Brenda Solis100% (1)
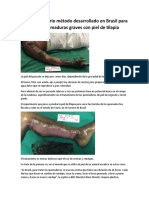
- Método Desarrollado en Brasil para Tratar Quemaduras Graves Con Piel de TilapiaDocument3 pagesMétodo Desarrollado en Brasil para Tratar Quemaduras Graves Con Piel de TilapiaJose Maria VargasPas encore d'évaluation
- Caracterización de EucaliptoDocument14 pagesCaracterización de EucaliptoDaniel ApazaPas encore d'évaluation
- Ficha de bloqueo de máquina xxxxDocument1 pageFicha de bloqueo de máquina xxxxLuis GomezPas encore d'évaluation
- Marihuana WikiDocument323 pagesMarihuana WikiM. Rafael Gutiérrez D.Pas encore d'évaluation
- Pruebas de Confianza TLG 0111Document37 pagesPruebas de Confianza TLG 0111Freddy Suatunce AyalaPas encore d'évaluation
- Densidad de PulpDocument232 pagesDensidad de PulpTravis BradyPas encore d'évaluation