Académique Documents
Professionnel Documents
Culture Documents
Diseño de Encuestas para Estudios de Mercado Tecnicas de Muestreo y Analisis Multivariante Licenciatura de Economia UNED PDF
Transféré par
angeldcristo100%(1)100% ont trouvé ce document utile (1 vote)
407 vues251 pagesTitre original
Diseño.de.encuestas.para.estudios.de.mercado.Tecnicas.de.muestreo.y.analisis.multivariante.Licenciatura.de.Economia.UNED.pdf
Copyright
© © All Rights Reserved
Formats disponibles
PDF ou lisez en ligne sur Scribd
Partager ce document
Partager ou intégrer le document
Avez-vous trouvé ce document utile ?
Ce contenu est-il inapproprié ?
Signaler ce documentDroits d'auteur :
© All Rights Reserved
Formats disponibles
Téléchargez comme PDF ou lisez en ligne sur Scribd
100%(1)100% ont trouvé ce document utile (1 vote)
407 vues251 pagesDiseño de Encuestas para Estudios de Mercado Tecnicas de Muestreo y Analisis Multivariante Licenciatura de Economia UNED PDF
Transféré par
angeldcristoDroits d'auteur :
© All Rights Reserved
Formats disponibles
Téléchargez comme PDF ou lisez en ligne sur Scribd
Vous êtes sur la page 1sur 251
Diseno de encuestas
para estudios
de mercado
Técnicas de Muestreo
y Analisis Multivariante
INDICE
Presentacién..
PRIMERA PARTE
Capitulo 1. Conceptos estadisticos basicos para la investigacién econé-
mico-social ..
1.1. Introducci6n. Los métodos empfricos en Ia investigacién econ6-
mico-social
1.2. Conceptos estadisticos basicos
1.2.1. Conceptos elementales de Estadistica Descriptiva .
1.2.2. Conceptos elementales de Teoria de la Probabilidad.
1.2.3. Conceptos elementales de Inferencia Estadistica
13, Estimadores.
13.1. Introduccién ..
1.3.2. Definiciones basicas
1.3.3. Comparacién de estimadores
1.3.4, _Intervalos de confianza .
1.3.4.1. Aproximacién normal .
1.3.4.2. Desigualdad de Tchebychev.
Capitulo 2, Las investigaciones econémico-sociales mediante muestreo.
Etapas de las encuestas por muestreo.
2.1. La complejidad de los trabajos de disefio y tratamiento estadistico
de encuestas
2.2. Etapa previa o de estudio y planteamiento del problema.
2.2.1. Fase de definicién de objetivos...
. XVII
53
53
54
55
vu DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
2.2.2. Fase de estudio 56
2.2.3. Fase de anilisis y diagnéstico de la informacién estudiada
en la fase anterior . 58
2.2.4. Fase de planificaci6n de la operaci6n y de disefio del plan
de muestreo. 71
2.2.4.1. Decisién sobre la informacién a obtener en cam-
po. Disefio de los cuestionarios 0 soportes fisicos
para la observacién. 2
2.2.4.2. Definicién de la petiocidad con que se realizaré
el trabajo y del marco temporal de referencia..... B
2.2.4.3, Eleccién del método de observacién y del modo
de administracién del trabajo de campo. . 78
2.2.4.4. Decisién sobre el tipo de muestreo a imple-
mentar . 719
Calculo del Tamajio de la Muestra y de su afija-
ciOn.... 87
Seleccién de las unidades muestrales 91
Elaboracién del plan de logistica y de intendencia 91
2.3. Etapa preparatoria de los trabajos de campo. 92
2.3.1. Preparacién y edicién de materiales 92
2.3.2. La seleccién y formacién de personal. 94
2.3.3. La organizacién. Asignacién de tareas, funciones y rela-
ciones a los miembros del equipo investigador.. . 96
2.3.4. La previsiGn y solucin de posibles incidencias en campo. 97
2.3.5. Otras tareas previas al inicio del trabajo de campo... 102
2.4. Etapa de observacién o de aplicacién del cuestionario: trabajo de
campo. . 102
2.5. Etapa de tratamiento de la informacién recab: 104
2.5.1. Depuracién.. 104
2.5.2. Codificacién 106
2.5.3. i 106
2.5.4. 107
2.5.5. 109
Revisién del cumplimiento de la muestra 109
Anilisis y tratamiento de la no-respuesta 110
Imputacién 112
La post-estratificacion o reequilibrado la muestra, 113
2.5.6. Analisis estadistico primario y tabulacién de los resultados... 113
6.1, Anélisis preliminar de los datos . 14
Obtencién de las estimaciones 114
CAlculo de los errores de muestreo 11S
Tabulacién 1S
Anilisis estadistico especializa 116
Interpretacién de resultados y presentacién y pu-
blicacién de los mismos... . 7
INDICE.
eae
2.5.7. Limitaciones y critica del trabajo de cara a operaciones fu-
turas.
Control de cali
e la investigacién
Capitulo 3, Muestreo aleatorio simple. Muestreo sistematico. Mues-
3.4.
3.5.
3.7.
Capitulo 4. Muestreo estratificado.
4.1.
43.
lades desiguales. Estimadores de razon. Estima-
Obtencién de muestras MAS y MASR
Estimaci6n de parametros poblacionales
3.3.1. Conceptos previos.
3.3.2, Estimacién de la media, el total y la proporcién.
3.3.3. Estimacién por intervalos....
Célculo del tamafio muestral.
3.4.1. Célculo del tamafio muestral con el error absoluto.
3.4.2. Célculo del tamaiio muestral con el error relativo
3.4.3. Céloulo de la varianza poblacional
Muestreo sistemético con arrangue aleatorio.
3.5.1. Estimadores lineales insesgados
3.5.2. Estimadores de la varianzi
Muestreo con probabilidades desiguales
3.6.1. Seleccién con reemplazamiento: estimador de Hansen y
Hurwitz
3.6.2. Seleccién sin reemplazamiento: estimador de Horvitz
Thompson
Métodos indirectos de estimacién.
3.7.1. Estimadores de razon
3.7.2. Estimadores de regresién ..
Introduccién
Variable utilizada
4.2.2. Niimero de estratos
4.2.3. Determinacién de los limites de los estratos
Estimadores en el muestreo estratificado. Sus varianzas.
4.3.1. Estimaci6n de la media y el total
2. _Estimacién de la proporcién
Afijaci6n igual.
Afijacién proporcional
Afigacién éptima.
Caso particular de afijacién éptima
118
118
121
121
123
125
125
126
134
137
138
141
143
145
148
149
152
152
156
158
158
163
167
167
168
169
170
170
171
172
172
172
174
176
176
178
181
183
x DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
4.4.5. Errores en los parémetros poblacionales. 185
4.4.6. Estratos exhaustivos 186
4.4.7. Afijaci6n 6ptima con més de una caracterfstica, 186
4.5. Precisién comparada del muestreo estratificado. 187
4.6. Unejemplo... 188
4.7. Estimadores de raz6n en el muestreo estratificado 194
Capitulo 5. Muestreo por conglomerados. 197
5.1. Introduccién 197
5.1.1. Definicién. 198
5.1.2. Unidades primarias, secundarias, etc. Unidades finales 198
5.2. Muestreo por conglomerados en una etap: 199
5.2.1. Estimadores de la media y del total 200
5.2.2. Estimadores de la proporcién. 204
5.2.3. Seleccién de conglomerados con probabilidades desi:
guales 205
5.2.4. Eficiencia de los conglomerados utilizando MAS. 208
5.3. Muestreo por conglomerados en dos etapas 210
5.3.1. Probabilidades, esperanzas y varianzas condicionada: 212
5.3.2. Estimacién del total 213
5.3.2.1. Muestreo sin reposicién de unidades de primera
214
.0 con reposicién de unidades de primera
p 219
5.4. Tamajio éptimo de una muestra bietépica, 221
5.5. Muestreo polietépico. 222
Capitulo 6. Disefios muestrales prdcticos 0 complejos. 223
6.1. Introduccién.... 223
6.2. La Encuesta de Poblacién Activa (EPA) como ejemplo de Encues-
tas a Hogare 223
6.2.1. Objeti 223
6.2.2. Poblaciér 224
6.2.3. Marco de la encuesta.. 224
62.4. Disefio muestral 224
6.2.4.1. Tamafio muestr 225
6.2.4.2. Estratificacién de la muestra de secciones.. 225
6.2.4.3. Afijacién de la muestra de seccione: 227
6.2.4.4. Seleccién de la muestr 227
a Actualizacién del marco y rotacién de la muestra. 228
Estimadores. 228
63. Hi indice de Precios al Consumo (IPC) 229
6.3.1. Objetivo de la encuesta 229
6.3.2. Determinacién de la estructura de consumo 229
INDICE
x1
6.4.
=
6.6.
6.3.3. Calculo del indice ..
6.3.4. Determinacién de los precios de los articulos que compo-
nen la cesta de la compra ..
6.3.5. Conclusiones...
Encuesta Econémica a Empresas.
6.4.1. Objetivos de la Encuest:
6.4.2. Estudio y planteamiento del problema.
6.4.3. Poblacién..
6.4.4. Unidades de investigacién.
6.4.5. Marco de la encuesta..
6.4.6. Disefio muestral .
6.4.6.1. Tipo de muestreo..
6.4.6.2. Estratificacion
6.4.6.3. Determinacién del tamajio de la muestra.
6.4.6.4. Seleccién de las unidades muestrales .
6.4.6.5. Modo de administracién de la Encuesta
6.4.6.6. Informacién a obtener.
6.4.7. Estimadores.
6.4.8. Errores de muestreo
Encuesta a los consumidores para obtener informacién sobre la
percepcién que tienen de un producto ..
6.5.1. Objetivo de la encuesta ..
6.5.2. Estudio y planteamiento del problem:
6.5.3. Poblacién..
6.5.4. Marco de la encuesta..
6.5.5. Unidades de investigacién.
6.5.6. Método de investigacién
6.5.7. Disefio muestral ..
6.5.7.1. Tipo de muestre:
6.5.7.2. Estratificaci6n de la muestra de secciones..
6.5.7.3. Afijacién de la muestra de secciones y seleccién
de las unidades de muestreo...
6.5.8. Estimadore:
6.5.9. Errores de muestreo
Medici6n de la calidad de un set
6.6.1. Objetivo de la encuesta .
6.6.2. Estudio y planteamiento del problema.
6.6.3. Poblacién..
6.6.4. Marco de la encuest:
6.6.5. Unidades de investigacién.
6.6.6. Disefio muestral ...
Tipo de variables a medir
Tipo de muestreo...
Definicién de estrato:
Definicién de conglomerados
icio de transporte..
230
px)
232
232
a
232
233
234
234
234
234
a
236
237
238
=
XI
DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
6.6.6.5. Afijacién de la muestra por estratos y con-
glomerados: 260
6.6.7. Estimadores.. 260
6.6.8. Errores de muestreo 261
6.7. Encuesta para determinar el nimero de los turistas de una ciudad y
el gasto turistico realizado vw 262
6.7.1. Objetivo de la encuest: 262
6.7.2, Estudio y planteamiento del problema. 262
6.7.3. Poblacién.... 263
6.7.4. Marco de la encuesta 263
6.7.5. Unidades de investigacion. 264
6.7.6. Método de investigacién 264
6.7.7. Disefio muestral ... 265
Tipo de variables a investigar.. 265
Tipo de muestreo... 265
Estratificacién de la muestr: 265
Seleccién de las unidades de muestreo 265
6.7.8. Estimadores y errores de muestreo .. 266
SEGUNDA PARTE
Capitulo 7. Andlisis estadistico especi
gramas SPSS. 2723
7.1. Introduce 273
7.2. Introduccién de los datos y generacién de estadistica descriptiva en
el programa SPSS .. 274
7.2.1. Programas SPSS versiones 7 a 9..
7.2.2. Utilizacién de los resultados gener:
los con el SPSS
7.3. Introduccién de los datos en las versiones 10 y 11... 288
Capitulo 8. Introduccién al andlisis multivariante 291
8.1. Concepto. 291
8.2. Conceptos previo: 291
8.2.1. Objetivos y escalas. 292
8.2.2. Inferencia estadistic 292
8.3. Etapas a seguir en el andlisis multivariante.. 294
8.4. Comprobacién de las hip6tesis de normalidad, homocedasticidad y
linealidad: ejemplo practico 295
8.4.1. Normalidad .. 295
8.4.2. Homocedasticidad 301
8.4.3. Linealidad 303
8.5. Conclusiones... 305
INDICE,
Capitulo 9. Regresién lineal
o1
92.
9.3.
9.4.
9.5.
9.6.
9.7.
98.
Capitulo 10. Tablas de contingencia
10.1.
10.2.
oe
10.4.
10.5.
10.6.
10.7.
Capitulo 11, Regresién logistica
oe
11.2.
Introduccién
Regresién lineal simple.
9.2.1. Formulacién del problema
Regresién lineal multiple .
9.3.1. Formulacién del problema
Variables cualitativas en la regresién lineal ..
Problemas de la regresi6n lineal
9.5.1. Problemas de la autocorrelacién ..
9.5.2. Problema de la multicolinealidad.
9.5.3. Numero de datos en la regresién..
Causalidad y correlacién...
Regresi6n lineal en el programa SPS:
9.7.1. Mediante comandos
9.7.2. Mediante ventana:
Apéndice matematico.
9.8.1. Regresién lineal simpl
9.8.2. Regresién lineal multiple
Introduccién..
Método...
Tablas de contingencia 2 x 2
10.3.1. Resumen del caso de una tabla de contingencia 2 x 2
(Recomendaciones de Cochran).
Tablas de contingencia con G.L. mayor que
10.4.1. Independencia en tablas (filas) x C (columnas)
Determinacién de las fuentes de asociacién
10.5.1. Andlisis de los residuos
10.5.2. Particién en tablas dependientes
Medidas de asociacién en tablas de contingent
10.6.1. La@ de Yule ..
10.6.2. El coeficiente de contingencia
10.6.3. Otras medidas de asociacién
10.6.4. Frecuencias esperadas pequefias
Anilisis con el programa estadistico SPS:
10.7.1. Ejemplo propuesto ..
10.7.2. Anilisis en el SPSS mediante ventanas
10.7.3. Mediante comandbs .
Introduccién....
Etapas en la estimacién de del modelo: presentacién del ejem-
plo
xi
307
307
307
307
311
312
315
316
316
316
317
317
=
318
318
323
323
323
327
Bay
329
330
=e
333
aa
=o
335,
338
340
341
343
346
347
351
351
353
358
359
aa
360
xiv DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
11.3. Aplicacién del SPSS a los modelos de regresi6n logistica (ejem-
11.4, Aplicacién del SPSS a los modelos de regresién logistica. Estudio
de interacciones (ejemplo 2)
itt Presentacién del ejemplo
11.5. Apéndice matemético de la regresién logistica.
11.5.1. Célculo de los prametros del modelo de regesi6n logisti-
ca (método de méxima verosimilitud)..
Capitulo 12. Modelos de respuesta probit
12.1, Introduccién
12.2. Modelos de respuesta probit
12.3. Modelos de respuesta probit en el SPSS.
Capitulo 13. Ai de la varianza ..
13.1. Definici6n de andlisis de la varianza (ANOVA) ..
13.2. Tipos de modelos ANOVA segtin las categorias del factor ..
Modelo de efectos fijos
Modelo de efectos aleatorios
13.3. Andlisis de la covarianz:
Introduccién
Definicién del andli
13.4. Modelos ANOVA en el SPSS ..
13.4.1. Opciones del programa
is de la covarianza (ANCOVA),
Capitulo 14, Andlisis factorial y de componentes pri
14.1. Introduccién
14.2. Modelo causal y andlisis factorial
14.3. El andlisis factorial y los componentes principales
14.3.1. Introduccién...
14.3.2. Componentes principales...
14.4, Anilisis factorial en SPSS
14.4.1. Ejemplo propuesto
14.4.2. Analisis mediante ventanas
14.5. Apéndice matemético: célculo y andlisis de los factores mediante
un ejemplo.
Ejempl
Clasificacién de los métodos de resolucién
. Componentes principales
14.5.4. Propiedades de los componentes principales.
367
367
369
377
Be
385
ENDICE.
Ejemplo de explicacién de componentes principales
Ejemplo de extraccién de componentes principales
Relacién de andlisis factorial y de componentes princi-
pales .. ve
Capitulo 15. Tests estadisticos ..
15.1. Elecci6n de la prueba estadistica adecuada ..
1.1. El modelo estadistico
Potencia-Eficiencia de las pruebas no paramétricas .
Pruebas estadisticas paramétricas y no paramétricas
15.2. Nociones previas
15.3. Conceptos previo:
15.4. Tabla resumen de tests estadisticos.
15.5. Pruebas paramétricas
. Prueba ¢ para dos muestras independientes..
Prueba ¢ para dos muestras independientes en el SPSS.
Prueba ¢ para dos muestras relacionadas.
Prueba ¢ para dos muestras relacionadas en el SPSS
15.6. Tests no paramétricos
Tests no paramétricos para dos muestras relacionadas
Tests no paramétricos para dos muestras independientes
Tests no paramétricos para K muestras relacionadas
Tests no paramétricos para k independientes..
Las medidas de correlaci6n y sus pruebas de significa-
ci6n...,
Capitulo 16. Anélisis de conglomerados.
16.1. Introduccién..
16.2. Etapas a seguir en el desarrollo del andlisis Cluster
16.2.1. Seleccién de individuos y variables
16.2.2. Medidas de similitud.
16.3. Distintos modelos de andlisis Cluster
16.3.1. Modelos jerérquico:
16.3.2. Modelos no jerarquicos
Capitulo 17. Andlisis de correspondei
17.1. Introduccién..
17.2. Finalidad
17.3. Ejemplo de aplicacién.
17.3.1. Método de Normalizacién.
17.4. Anilisis de correspondencias miltiple.
17.4.1. Andlisis de homogeneidad
17.4.2. Analisis de componentes principales categéricos (prin-
cals)
17.4.3. Anilisis de la correlacién canénica no lineal (Overals)..
481
482
485
489
489
489
491
492
493
493
494
495,
495
496
499
499
502
502
SiS
S41
SSL
558
567
567
567
568
569
580
580
588
593
593
593
594,
606
607
607
608
XVL
oe 18. Escalamiento multidimensional
18.1,
18.6. Ejemplos de aplicacién: aplicacién con el SPSS
Capitulo 19. Anilisis conjunto
1
DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Concepto ..
Modo de introduccién de los datos
Escala de medida de los datos
18.3.1, Condicionalidad de la medi:
18.3.2. Obtencién de proximidades a partir de una matriz rec-
tangular.
18.3.3. Modelos de escalamiento empleado
Ajuste del modelo
Otros modelos de escalamiento multidimensional
18.5.1. Modelo de escalamiento desdoblad .
18.5.2. El modelo de escalamiento de diferencias individuales
(INDSCAL?
18.5.3. Modelo de escalamiento con replicacién
18.6.1, Ejemplo 1: Modelo general...
18.6.2, Ejemplo 2: Modelo desdoblado
Introduccién
Anilisis conjunto: definicién e historia
Las etapas de un experimento de andlisis conjunto .
19.3.1, Introduccién ..
19.3.2. Eleccién de los atributos y nivele:
19.3.3. Selecci6n del procedimiento de recogida de datos .
19.3.4. Presentacién de estimulo:
19.3.5. Estimacién de la funcién de preferencia
19.4. Interpretacién de resultados de un experimento de anélisis con-
19.5. Caso practico de andlisis conjunto con SPSS
Apéndice. Distribucién de probabilidad mas sig
de tablas ...
1.
ae
Bibliografia ...
junto .
19.5.1. Descripcién del caso presentado..
19.5.2. Procedimiento de ejecucién con SPSS.
icativas. Utilizacién
Distribucién binomial
Distribucién de Poisson...
Distribucién normal
Distribucién x? (chi cuadrado) de Pearson
Distribucién f de Student...
Distribucién F de Snedecor
Anexo de tablas estadisticas ..
609
609
609
611
611
612
614
615
616
616
617
617
618
618
631
639
639
639
640
640
641
643
645
645
646
646,
647
647
661
661
663
665
670
671
672
674
707
CAPITULO 8
INTRODUCCION AL ANALISIS MULTIVARIANTE
8.1. CONCEPTO
Con este capitulo se inicia el comienzo de la parte correspondiente al estudio de
las técnicas de andlisis multivariante. Con este calificativo se hace referencia a las téc-
nicas que tratan de un modo simulténeo mas de dos variables.
El objetivo fundamental del este tipo de analisis es el de buscar relaciones entre
las variables para a partir de éstas estimar modelos de prediccién o simulacién, bus-
car agrupaciones entre individuos, reducir el ntimero de las mismas etc.
Asf pues cada técnica tiene un propésito especifico: unas servirdn para estimar
funciones que permitan predecir o simular el comportamiento de una variable o va-
riables en funci6n de otras, otras para buscar semejanzas y diferencias de los indivi-
duos de acuerdo con distintas variables, u otras para reducir el niimero de variables y
expresar éstas en funcién de otras.
8.2, CONCEPTOS PREVIOS
‘Antes de decidir la técnica especifica debemos tener en cuenta los siguientes as-
pectos:
12 El objetivo pretendido y el tipo de escala en el que las variables objeto de
andlisis estén referidas.
22 Los aspectos relativos a la posibilidad de inferir los datos a la poblacién ob-
jeto de estudio: inferencia estadistica.
Analicemos cada uno de estos aspectos con mayor detalle.
292 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
8.2.1. Objetivos y escalas
Tal y como se ha indicado en el apartado correspondiente a la introduccién del
tema cada técnica tiene un propésito y utilidad. Ademas se debe tener en cuenta la es-
cala en que estén medidas las variables.
Como se traté en el capitulo primero de este libro existen cuatro escalas: las de-
nominadas métricas propias de las variables cuantitativas (escalas de intervalo y ra-
z6n) y las no métricas propias de las cualitativas (la nominal o clasificatoria, y Ia or-
dinal). El tipo de técnica multivariante va a estar condicionada por el tipo de escala
empleado.
El cuadro de la pagina siguiente realiza un pequefio resumen de las principales
técnicas de andlisis multivariante en funcién de los objetivos y escalas que admiten !
8.2.2. Inferencia estadistica
En la mayor parte de las ocasiones el investigador trabaja con muestras. Sin
‘embargo lo que se desea es poder extrapolar las caracteristicas, relaciones, modelos
o estadisticos hallados a la poblacién en conjunto. Por ejemplo, si quisiéramos cons-
truir un modelo que nos predijera el precio de la vivienda en una zona en funci6n de
distintas variables como la superficie construida y la antigtiedad de la vivienda de-
seariamos que dicho modelo no fuera sélo aplicable a nuestros datos sino que sirviese
también para poderlo extrapolar a otros casos.
La teoria estadistica nos ensefia que para esto suceda deben cumplirse los si-
guientes requisitos*:
1° Normalidad: Se debe comprobar para cada variable medida en una escala
métrica, La mayorfa de las técnicas exigen también que las variables sean multiva-
riablemente normales. Es decir, que la combinacién de las variables siga también una
distribuci6n normal.
2° Homocedasticidad: Las varianzas de las variables explicativas o indepen-
dientes (en nuestro ejemplo la superficie construida y la antigiiedad) deben tender a la
igualdad con la de la explicada.
3° Linealidad: Se debe comprobar en el caso de biisqueda de relaciones line-
ales o cuando se utilizan instrumentos como el coeficiente de correlacién de Pearson
para medir relaciones entre variables (caso del andlisis factorial o de la regresién li-
neal).
En muchas ocasiones* no se cumplen estas condiciones. En estos casos existiri-
an tres posibilidades:
Los requisitos concretos se abordarén en el capitulo correspondiente a cada una de las téenicas
2 En el ejemplo se indicaré como realizar la comprobacién a través del SPSS.
> Especialmente el requisito de la normalidad de tos datos.
INTRODUCCION AL ANALISIS MULTIVARIANTE
293
Nombre de la técnica
Funcién
Escalas de las variables
admitidas
Regresién lineal.
Estimaci6n de modelos a partir
de la dependencia entre varia-
bles.
Métrica.
Regresién logistica
Estimacién de modelos a partir|
de la dependencia entre varia-
bles.
Variable Dependiente:
No métrica.
Independientes: Ambas.
de ordenacién conjunta,
Modelos probit. Estimacién de modelos a partir| Variable Dependiente:
de la dependencia entre varia-| No métrica.
bles. Independientes: Métrica.
Tablas de contingencia. Analizar la relaci6n entre las| No métrica,
variables.
Modelos logaritmico lineales.| Analizar la relacién entre las| No métrica,
variables.
Contrastes paramétricos. | Analizar la relacién entre las| Métrica,
variables.
Contrastes no paramétricos. | Analizar la relacién entre las| No métrica.
variables.
Anélisis factorial. Establecer modelos de reduc-| Métrica,
cin de la dimensionalidad.
Anélisis de corespondencias.| Establecer modelos de reduc-| No métrica,
cién de la dimensionalidad y
analizar relacién entre varia-
bles.
Anilisis de conglomerados. | Agrupar individuos por proxi-| Ambas.
midades,
Escalamiento multidimen-| Agrupar individuos por proxi-| Ambas.
sional. midades y reducir la dimensio-
nalidad.
Anilisis conjunto. Obtencién de utilidades a partir] Ambas.
294 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
a) Realizar transformaciones de las variables originales que no cumplan
las hipétesis de normalidad y homocedasticidad: Una de las mas empleadas
es aplicar el logaritmo neperiano a la variable original que no lo cumpla. El in-
conveniente de esta posibilidad es que la transformacién de las variables hace
que se pierda informacién de la original y que sea mucho mas complicado in-
terpretar los resultados.
b) Utilizar técnicas que no necesiten estos requisitos: Tal seria el caso de los con-
trastes no paramétricos 0 el escalamiento multidimensional no métrico. El pro-
blema de esta opcidn es que impide que se usen técnicas mucho més potentes.
c) Realizar el analisis con las variables originales: Esta seria la opcién mas
practica aunque menos correcta desde el punto de vista de la teoria estadistica.
Sin embargo, el hecho de que en muchas ocasiones no se cumplan estas hi-
pétesis y de que la transformacién conlleve pérdida de informacién y facilidad
de cara a la interpretacién de los resultados hace que atin sabiendo que el mo-
delo podria tener sesgos de cara a poderlos usar en todas las circunstancias sea
ésta la opcién que desde el punto de vista préctico sea més recomendable.
8.3. ETAPAS A SEGUIR EN EL ANALISIS MULTIVARIANTE
Cualquier técnica de Andlisis Multivariante debe ast seguir los siguientes pasos:
1° Determinacién del objetivo a conseguir: Segiin cual sea el objetivo debe-
remos optar por unas técnicas u otras. Los objetivos pueden ser muy variados como la
de determinar un modelo de prediccién y/o simulaci6n, analizar las relaciones entre
las mismas, o reducir su dimensionalidad.
2° Determinacién de las variables y el tamafo muestral 6ptimo: Aqui se
conecta esta parte con la primera parte del libro. Para poder extraer conclusiones ex-
trapolables se hace necesario tener una muestra representativa de la poblacién que se
estudia. Ninguna técnica podré suplir el desarrollo de un buen estudio muestral pre-
vio ya que la calidad de los datos es la que determinaré la validez del andlisis. Asi-
mismo es muy importante la seleccién de las variables.
La determinacién de éstas y el modo de medicién de las mismas (la escala em-
pleada) es uno de los aspectos més importantes. Como se veré al estudiar cada una de
las técnicas cada una de ellas admite un tipo de variables por ello es fundamental el
objetivo que se desea lograr.
3.° Comprobacién de las condiciones de aplicabilidad de la técnica: Es
fundamental saber las condiciones de aplicabilidad de las técnicas elegidos. Dentro de
este apartado incluimos también con las puntualizaciones vistas anteriormente el
cumplimiento de las hipétesis de normalidad, homocedasticidad y linealidad en los
casos en los que se requieran.
4° Interpretacién de los resultados: Una vez realizado el estudio sera funda-
mental saber interpretar los resultados obtenidos mediante el ordenador. Una mala in-
terpretacin puede Ievar a conclusiones errdneas. El objetivo principal de los si-
guientes capitulos es la de que el alumno sepa aplicar e interpretar la técnica.
INTRODUCCION AL ANALISIS MULTIVARIANTE, 295
5.° Validez del modelo: Todas las técnicas dispondran de distintos estadisticos
que permitiran contrastar la validez del modelo o anilisis realizado.
8.4. COMPROBACION DE LAS HIPOTESIS DE ORMALIDAD,
HOMOCEDASTICIDAD Y LINEALIDAD: EJEMPLO PRACTICO
Como se ha dicho anteriormente el cumplimiento de estas hipétesis nos va a per-
mitir realizar inferencias mucho més potentes. Su cumplimiento es muy deseable en
especial en el caso de las técnicas que como la regresién lineal emplean variables me-
didas en escalas métricas, ya que en caso contrario deberemos saber que las estima-
ciones efectuadas podrian contener sesgos 0 errores a la hora de extrapolar los re-
sultados al total de la poblacién.
En este ultimo apartado se estudiarén los contrastes principales que existen en el
SPSS para contrastar estas hipstesis.
Partamos de un ejemplo prictico. Se dispone de datos de tasaciones de un grupo
de viviendas del distrito Centro de Madrid. Se pretende realizar un modelo que pre-
diga el valor de una vivienda en funcién de la superficie construida. Como se vera en
el capitulo de la regresi6n lineal ésto se podria hacer empleando esta técnica. La ex-
plicaci6n de la misma se encuentra en el capitulo correspondiente por lo que aqui tan
s6lo indicaremos como contrastar las hipétesis de normalidad, homocedasticidad y li-
nealidad.
8.4.1. Normalidad
Este requisito se deberé comprobar en el caso de las variables cuantitativas (me-
didas en escala métrica). Veamos como hacerlo con el SPSS.
Existen dos modos de comprobarlo: graficamente y a través de la realizacion de
contrastes. Respecto al primero encontramos los graficos q-q 0 graficos de probabi-
lidad normal en donde se representan los valores observados de los residuos y los es-
perados en el caso de que siguieran una distribucién normal. Respecto a los segundos
existen muchos contrastes uno de los mds usados es el de Kolmogorov-Smirnov-Li-
Ilefords (KSL).
a) Variable valor de tasacién (valortasac)
a,) Método grafico
Emplearemos los gréficos q-q que sirven al igual que los p-p para comprobar si
unos datos se ajustan a una determinada distribucion prefijada de antemano (normal,
logistica, uniforme, etc.). Si la variable seleccionada coincide con la de la distribuci6n
seleccionada (en nuestro caso la normal) los puntos se concentrarén en tomo a la If-
nea recta. La opcién para realizar esta prueba se encuentra en el menti «Graficos».
296 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
ERE dE RR CeR RR ReR RARE Reales REE
oe we
2 tos
a a aioe
a an “Rp arf aa:
or “od” Stagg ae
‘ oe Bemion al ees
‘ar ‘oat ep ee
a rast Ber 6a were
& ue Oaseo) a ah ao.
Lo pose ea aa
». goa
A continuacién obtenemos la siguiente caja de didlogo donde seleccionamos la
variable a analizar:
1 Precio mevo cuadiado
1 eniguedesd fentiouel
> aniguedad lantigu]
@ Precio meto cuadiad
® Supeticie constuida
@ Distitos municipal [
INTRODUCCION AL ANALISIS MULTIVARIANTE 297
Al realizar la prueba obtenemos el siguiente resultado:
Normal grafico Q-Q de valortasac
200000000:
g °
g fo
§ 100000000-
3
E
2
s °
100000000.
100000000 "100000000 " 300000000 500000000
° 200000000 400000000 600000000
Valor observado
Como vemos los datos no parecen agruparse en torno a la recta por lo que no pa-
rece que estemos ante una distribucién normal.
a,) Uso de contrastes
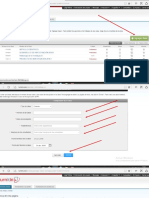
Ahora utilizamos el contraste Kolmogorov-Snimov KSL. Esta opcién se en-
cuentra en el submenti «Explorar» sito en el ment «Analizar».
Explorar
D valotacac[valetas]
298 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
All colocamos la variable de la que deseamos realizar el contraste. A continuacién
pulsamos en la opcién de «Gréficos» y marcamos la opcién «Graficos con pruebas de
normalidad>. Es esta opcién la que nos permitiré obtener el valor del contraste.
Este contraste tiene como Hipétesis nula el ajuste de los datos a la distribucién
normal por lo que siempre que salga un valor de la p asociada superior a 0,05 0 0,01
(segiin el nivel de significacién elegido) deberemos aceptar que los datos se ajustan a
Ia distribucién normal. En caso contrario, es decir que la p sea inferior a ese valor di-
Temos que no se ajusta a una distribucién normal. En nuestro caso el valor de la p
(Sig) es igual a 0,000 valor que indica que no sigue una distribucién normal
Pruebas de normalidad
Kolmogorov-Smirnovt
Estadistico gl Sig.
valortasac 257 194 .000
a. Correcci6n de la significacién de Lilliefors.
Junto a este estadistico el SPSS ofrece estadisticos generales que pueden resultar
de interés como el mtimero de datos (194), la media, varianza y otros estadisticos des-
ctiptivos.
Resumen del procesamiento de los casos
Casos
Véilidos Perdidos Total
N Porcentaje N Porcentaje N | Porcentaje
valortasac | 194 100.0% 0 0% 194 100.0%
INTRODUCCION AL ANALISIS MULTIVARIANTE 299
Descriptivos
Estadistico | Error tip.
valortasac Media 36,989.01 | 3.120.703
Intervalo de confianza Limite inferior 30.833.949
para la media al 95% Limite superior
43.144.073
Media recortada al 5% 31.345.186
Mediana 26,304.615
1,89E+15
43.466.368
0
519.670.262
Rango 519.670.262
Amplitud intercuartil 21.861.668
Asimetria 7.108 115
Curtosis 79.820 347
En resumen, concluimos que no sigue una distribuci6n normal. Ante esta situa-
cién podemos optar por realizar transformaciones de la variable: tomar logaritmos ne-
perianos es la més habitual, realizar andlisis que no requieran la normalidad de los da-
tos como los contrastes no paramétricos o prescindir de este hecho atin sabiendo que
de cada a la inferencia estadistica pueden existir errores.
b) Variable superficie construida (supercons)
Realizamos ambos métodos para esta variable. En el grdfico obtenemos el si-
guiente:
b,) Analisis grafico
Normal grit 0-0 de Supertice construe
LC
100. re
~100 6 100 20
Valor Normal esperado
a 8
Valorobsenvado
300,
DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
Gréfico que tampoco parece concluir que estemos ante una distribucién normal.
Véamos a continuacién el contraste.
b,) Contraste
Pruebas de normalidad
Kolmogorov-Smirnov’
Estadistico gl Sig.
Superficie construida 236 177 .000
a
Correccién de la significacién de Lilliefors.
Resumen del procesamiento de los casos
Casos
Vélidos Perdidos Total
N | Porcentae | N | Porcentaje | N | Porcentaje
Superficie constr. | 177 91,2% 7 88% 194 | 100.0%
Descriptivos
Estadistico | Error tip.
valortasac Media 109.45 8,30
Intervalo de confianza Limite inferior 93,07
para la media al 95% Limite superior
125,83
Media recortada al 5% 94,97
Mediana 85,00
Varianza 12.193.669
Desv. tip. 110,42
Minimo 0
Maximo 1.241
Rango 1.241
Amplitud intercuartil 59,50
Asimetria 6.748 183
Curtosis 63,437 363
INTRODUCCION AL ANALISIS MULTIVARIANTE, 301
Como se observa tampoco parecen cumplir la hipétesis de normalidad.
8.4.2, Homocedasticidad
Este concepto hace referencia a la igualdad de las varianzas entre variables, ya
sean éstas cuantitativas 0 cualitativas respecto a la variable dependiente. El test em-
pleado es el de Levene. Esta prueba calcula la diferencia entre el valor de cada caso y
la media de su casilla y Heva a cabo un andlisis de varianza‘ de un factor sobre estas
diferencias, Como se vers en el capitulo donde se explica esta técnica para realizar el
andlisis de la varianza de un factor necesitamos que la variable explicativa esté en es-
cala nominal u ordinal con el fin de que pueda formar varios grupos. En nuestro
ejemplo dividiremos la variable superficie construida en tres grupos. En concreto los
determinados por sus percentiles 33 (70,74 m2), y 66 (103).
Mediante sintaxis (vista en el capitulo anterior) creamos una nueva variable a
1a que denominamos (superco) que asigna un 1 a los valores inferiores a 70,74 m?,
un 2 los que se encuentran entre 70,74 m? y 103 m?, y, un 3 los superiores a ese
valor.
if (supercon le 70.74) superco=1
if (supercon gt 70.74) and (supercon le 103)) superco=2
if (supercon gt 103) supercok3.
execute.
* Ver la explicacién del andlisis de la varianza en el capitulo correspondiente.
302 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
Con esto logramos tres grupos iguales que recogen los niveles de superficie
construida.
La prueba de Levene se encuentra en la opci6n «Anova de un factor» sito en el
submenti «comparar medi
& Supeticie conse
|@® Precio metio cuads:
=| ® Precio metro cuadi
<® Supetticie constr
4 @ Distitos municipale
1® precio
Colocaremos como variable dependiente valortasac (valor de la tasacién) y como
factor (superco) que es la variable que determina los grupos surgidos de la division en
tres grupos de la variable superficie construida.
En «opciones» pulsamos la opcién «Homogeneidad de varianzas» que halla el
test de Levene.
Por tiltimo pulsamos «continuar» y luego «aceptar». En uno de los resultados ob-
tenemos el test de Levene. Esta prueba tiene como hip6tesis nula la homogeneidad de
las varianzas por lo que como en el caso anterior cuando la p (Sig.) sea mayor que
0,05 aceptaremos la homogeneidad de las varianzas (homocedasticidad), y cuando
sea menor la hetegeroneidad. En este caso no habré homocedasticidad.
INTRODUCCION AL ANALISIS MULTIVARIANTE 303
Prueba de homogeneidad de varianzas
valortasac
Estadistico
de Levene gl gl2 Sig.
11.689 1 115 001
Como vemos la p (sig.) es igual a 0,001 que al ser menor que 0,05 inferiremos
que no hay homogeneidad de las varianzas, y por lo tanto no habra homocedasti-
cidad.
Las observaciones son similares a las realizadas al hablar de la normalidad. Es
decir, existen tres posibles opciones: optar por realizar transformaciones de la va-
riable: tomar logaritmos neperianos es la mAs habitual, realizar andlisis que no re-
quieran la normalidad de los datos como los contrastes no paramétricos o prescindir
de este hecho atin sabiendo que de cada a la inferencia estadistica pueden existir
errores.
8.4.3. Linealidad
Se exige sobre todo en aquellas técnicas que presuponen medidas de asociacién
ineales ®. La més habitual es la del coeficiente de correlacién de Pearson. Entre
ellas podemos mencionar la regresi6n lineal o el andlisis factorial.
Para comprobar la linealidad lo més titil reside en el célculo del coeficiente de
correlacién lineal para cada par de variables cuantitativas. El SPSS ofrece asimismo
un contraste que considera como hipétesis nula la ausencia de correlacién por lo que
los valores de la p (sig.) superiores a 0,05 indicardn coeficientes de correlacién no
significativos y viceversa valores de la p inferiores a 0,05 mostrarén valores signifi-
cativos.
El coeficiente de correlaci6n nos va a indicar grados de relacién lineal en una es-
cala que varia de —1 hasta 1. Cuanto mayor sea el valor en valor absoluto® serd la re-
laci6n de las variables y viceversa. El signo positivo indica una relacién directa’ y el
negativo inversa*.
Para determinar el coeficiente de correlaci6n lineal esta opcién se encuentra en el
mend «Correlaciones bivariadas».
5 Propio de variables cuantitativas.
© Mas proximo a 1.
7 Alcrecer una variable crece la otra y viceversa.
* Al crecer una variable decrece la otra y viceversa.
304 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
A continuacién encontramos la siguiente caja de didlogo donde sefialamos la op-
ci6n correspondiente al coeficiente de correlacién de Pearson y arrastramos las va-
riables de las que queremos hallar el coeficiente de correlacién (valortas (valor de ta-
saci6n)) y supercon (superficie construida):
Tras pulsar «Aceptar» obtenemos los resultados:
INTRODUCCION AL ANALISIS MULTIVARIANTE 305
Correlaciones
valortasac Superficie
construida
valortasae Correlacién de Pearson 1.000 664*
Sig. (bilateral) . 000
N 194 177
Superficie construida __Correlaci6n de Pearson 664% 1,000
Sig. (bilateral) 4
N v7
* Lacorrelacion es significativa al nivel 0,01 (bilateral).
La tabla muestra un valor del coeficiente de correlacién igual a 0,664 que mues-
tra un valor de la p igual a 0,000 valor que indica que el coeficiente es significativo.
8.5. CONCLUSIONES
Las técnicas de andlisis multivariante tratan de un modo simultdneo mas de dos
variables a la vez. Cada una tiene un propésito distinto y unas condiciones de apli-
cabilidad diferentes. En el uso de las mismas sera fundamental comprobar la escala
en el que las variables estan formuladas,
Asimismo muchas de las técnicas, especialmente las que tratan datos formulados
en escalas métricas (de intervalo o de raz6n) exigen normalidad y homocedasticidad
para poder realizar inferencias generales a la poblacin objeto de estudio.
‘Sin embargo, dado que en muchas ocasiones estas condiciones no se cumplen se
hace necesario lograr distintas soluciones.
A lo largo del capitulo se han enunciado tres: la primera es realizar transforma-
ciones de las variables originales. La més usual es la de hacer el logaritmo neperiano
de la variable. El de esta solucién es la pérdida de informacién y de facilidad inter-
pretativa. La segunda radica en elegir otras técnicas que no requieran estas hipstesis
como los contrastes no paramétricos. La tiltima menos correcta estadfsticamente
pero a la que muchas veces lleva la practica es tomar las variables originales atin a ex-
pensas que no cumplan estas condiciones °. En este caso deberemos saber que los
coeficientes que determinasemos por ejemplo en la regresién lineal del ejemplo no
podrén ser extrapolados a todos los pisos de la zona. Sin embargo si el modelo est4
bien validado su uso puede Ievar a conclusiones perfectamente validas desde el
punto de vista practico.
* Tntentando siempre que al menos la muestra sea significativa.
CAPITULO 13
ANALISIS DE LA VARIANZA
13.1, DEFINICION DE ANALISIS DE LA VARIANZA (ANOVA)
El andlisis de la varianza permite estudiar si un conjunto de variable/s indepen-
dientes o explicativas influyen sobre una variable dependiente de tipo continuo.
Desde una perspectiva formal, el andlisis de la varianza es un caso especial del
modelo lineal general, con una variable dependiente continua, en el que las variables
explicativas son no continuas, estando expresadas en forma de categorias.
La variable explicativa o factor debe presentar distintas categorias y la variable
dependiente debe aparecer clasificada en funcién de dichas categorias, formando gru-
pos. El andlisis comprueba si existen diferencias significativas entre las medias de
cada uno de los grupos definidos y si estas diferencias se deben a variaciones alea-
torias o sistemticas.
E] andlisis de la varianza es especialmente adecuado para investigaciones expe-
rimentales, como, por ejemplo, la determinacién del efecto sobre las ventas de un
producto de distintos niveles de precios, presentacién, tipo de puntos de venta, si-
tuacién que ocupa la marca en Ja estanteria del establecimiento, etc.
EJEMPLO 13.1. Se plantea estudiar c6mo influye la decoracién en la valoracién
que se hace de un restaurante por parte de sus clientes.
Para ello, dos restaurantes de una misma cadena son decorados de modo distinto.
Uno de modo muy sobrio, y otro con una decoracién creativa Se pide a dos grupos de
personas (que fueron a cada uno de los restaurantes) que hagan una valoracién del
restaurante que habjan visitado. La valoracién se realiza en una escala de | a 10.
402 ‘DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
Los datos obtenidos son los siguientes:
Indivduo | Valoracién
(Decoracién creativa)
a 5
Grupo 1 b 4
Restaurante A c 4
(Decoracién sobria) d 4
e 3
f 7
Grupo 2 z 5
Restaurante B h 6
i 6
i 6
La variable dependiente es la valoracién que los individuos han dado sobre los
restaurantes.
La variable independiente o factor aparece con dos categorfas: decoracién sobria
(grupo 1) y decoracién creativa (grupo 2).
13.2. TIPOS DE MODELOS ANOVA SEGUN LAS CATEGORIAS
DEL FACTOR
1. Efectos fijos: los niveles del factor estén previamente determinados y s6lo se
sacan conclusiones para estos.
2. Efectos aleatorios: los niveles que se pueden establecer son infinitos y se es-
tudia Ginicamente una muestra aleatoria de los mismos. Los resultados de la
muestra se extienden a la poblacién.
3. Efectos mixtos: Se trabaja con factores de ambos tipos.
13.2.1. Modelo de efectos fijos
Se puede realizar una clasificacién del andlisis de la varianza en funcién del
ndmero de factores que intervienen en el mismo. Asf, se hablara de ANOVA para
uno, dos, tres o mas factores,
‘Anova para un factor
El andlisis de la varianza se puede enfocar desde dos puntos de vista: desde una
perspectiva tradicional y desde el punto de vista del andlisis de regresiGn. Se verd que
estos dos enfoques legan a los mismos resultados.
Para ilustrar el andlisis se desarrolla el ejemplo anterior que es el caso de una va-
riable dependiente y un factor con dos categorias.
ANALISIS DE LA VARIANZA 403
Anova tradicional
Este modelo tiene la siguiente expresién:
Y,=u+4+6,
+ Y,, = variable dependiente.
+ 11=constante que recoge la respuesta media de todos los niveles.
+ 1, = efecto diferencial del nivel j. Recoge la influencia de cada grupo y es el ob-
jetivo del andlisis. Son efectos diferenciales sobre 4, y por tanto: 7, = 0.
+ €, = término de error. Es aleatorio y se distribuye como una N(0, 02).
siendo:
Cuando el nimero de elementos de cada grupo es el mismo, el modelo se deno-
mina equilibrado. En caso de que el ntimero de elementos sea distinto recibe el
nombre de modelo no equilibrado.
Para medir las diferencias entre las observaciones se parte de descomponer la va-
riacién total en varianza entre y varianza intra:
VARIACION TOTAL = VARIACION ENTRE + VARIACION INTRA
La variacién total (VI) mide la variacién de cada elemento respecto de la media
total y se calcula segiin la siguiente formula:
donde:
+ Y,, = observaci6n i del grupo j de la variable dependiente.
+ ¥.. = media aritmética total de la variable dependiente.
La variaci6n entre (VE) recoge la variaci6n de la media de cada uno de los gru-
pos respecto a la media total, es decir, es la suma de la variacién o dispersién entre
los grupos y se expresa matematicamente segiin la siguiente formula:
ve = Som.
a
404 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
donde:
+ ¥,=media aritmética del grupo j.
+ m, = mimero de elementos por grupo. Aparece debido a la necesidad de pon-
dérar el ntimero de elementos de cada grupo j.
La variacién intra (VD) mide la homogeneidad de cada uno de los grupos, es de-
cir, es la diferencia entre cada observacién y la media del grupo al que pertenece. Se
define segtin la siguiente ecuacién:
Los grados de libertad correspondientes a las anteriores expresiones son:
“We
+ VE=
+ Visk-n
-1
siendo:
+ k=ntmero total de observaciones.
+ n=nimero total de grupos.
Por tanto, la expresin VI = VE + VI queda:
M:
&
1
I
aia al iI
Contraste F para el Anova tradicional
Para contrastar el andlisis de la varianza se utiliza una F de Snedecor. Se trata de
ver si las diferencias entre e intra grupos son significativamente importantes y si son
aleatorias o sisteméticas.
Para calcular el estadistico F se parte de las siguientes igualdades:
EIVEin—1] =" + (Un) x Smt?
c
E[VI/n-1]= 07
ANALISIS DE LA VARIANZA 405
Entonces:
E
(ik=ny
Y se calcula F como:
La hipétesis nula que se contrasta es que no existan diferencias en los grupos, es
decir, que la variaci6n entre es igual a la variaci6n intra. En este caso los efectos di-
ferenciales de cada grupo tienen que ser nulos:
=0
Hy 4 = ,
La hipétesis alternativa H, es que alguno de los efectos diferenciales sea distinto
de cero.
‘Comparando el valor de F segtin las tablas (F,) y el valor de F calculado segtin la
expresi6n anterior (F) se concluye que:
— si F > F.entonces se acepta H, y existen elementos diferenciales.
— si F ¥Z,- ZY, -¥)
ia iat
Ia ecuacién (6) queda:
VI yay) = Vy ~ BVT, = VI, - VISIVT,
Siguiendo un proceso semejante se llega a definir la variacién intra ajustada, es
decir, Ia variaci6n entre los valores de la variable debida al efecto residual:
=V1,- BVI, =V1,,-VEIVI,, 1)
Vd, ‘yx(adj)
426 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
La variaci6n entre ajustada, que representa la variacién debida a los efectos de los.
niveles de los factores se define a partir de (6) y (7):
VE, 7
‘sm(adhy = VE yy¢aaiy —
co
(ag)
Es decir, como se vio en ANOVA la descomposicién de las variaciones sigue el
siguiente esquema:
VARIACION TOTAL = VARIACION ENTRE + VARIACION INTRA
Queda por contrastar la hipétesis de efectos diferenciales nulos:
7=0
a través del test F definido del siguiente modo:
p Ein h=1
Vinualh=n
A partir del cuadro del ejemplo se pueden realizar los siguientes célculos:
Lugar en que se coloca el producto
Estanteria baja_| Estanterta media | Estanterta alta
Zz Y Z Y Zz Y
190 | 177 | 252 | 226 | 206 | 226
261 | 225 | 228 | 196 | 239 | 220
194 | 167 | 24 | 198 | 217 | 215
2ai7_[ 176 | 246 | 206 | 177 | 188
2155 | 18625 | 2415 | 2065 | 209,75 | 2145
Lo que hacemos es calcular los coeficientes f de la ecuacién por minim
Grados ordinarios, se toma después la variable se corrige, y luego se hace la vari
entre e intra.
cua-
43
¥ YG, -Za, -¥) = 4153,75
ANALISIS DE LA VARIANZA_ 427
w= %- Y,,)? =3670,75
VE,, = VI, ~V1., = 2289,5
VE,, = VI, — VI, =1696,17
VE,, = VI ~ VI, = 148,08
Con estos resultados se puede calcular la variacién total, intra y entre ajustadas, es
decir, las variaciones entre los valores de la variable dependiente debidas al efecto de
os factores una vez corregidas por la variable control.
oad = 536,92 — (4153,75)? / 784,25 = 3150.44
VI ayy = 3670,75 — (405,67)? / 544,75 = 748,68
VE yas = 3150,44 — 748,68 = 2401,76
‘yagi
El test F queda:
F = (2401,76 / 3 — 1)] / [748,68 / (12-3 - 1)] = 12,83
dado que la F (2; 8; 0,95) = 4.46 de las tablas toma un valor de 4,46 para un nivel de
significacién del 95% rechazamos la hipstesis nula y se concluye que el modo de co-
locacién del producto en las estanterias tiene efectos diferenciales.
Ancova para dos factores
Se trata de conocer el efecto simultsneo de dos factores o variables indepen-
dientes sobre una variable dependiente. Se consideraré un factor A con p categorias y
un factor B con q categorias, de tal forma que se definen p x q categorfas sobre la va-
riable dependiente y la variable control.
428 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Modelo formal
El modelo formal queda definido del siguiente modo:
Yn SHAG, +7, +07), + BZy -Z) + ey
donde:
_
+ 11= constante (media total).
* a, = efecto de la categorfa i del factor A, con Da, = 0.
*+ 1, efecto de la categoria j del factor B, con L,= 0.
* (a, = efecto interaccién de la categoria i del factor A y la categoria j del fac-
tor B, con 5, (a9), = Oy E, (orp, = 0.
+ B=coeficiente de la variable control.
valor observado de la variable dependiente.
+ Z,= valor observado de la variable control.
* &, = error, variable aleatoria con media cero y varianza 0”,
+12 nap
q.
‘m, numero de observaciones por categoria.
Se trata de analizar los efectos diferenciales de los niveles de los factores y del
efecto interaccién. La hipétesis de nulidad de efectos se contrasta mediante el test F.
El paso previo consiste en descomponer la variacién total como hasta ahora se ha
ido haciendo, es decir:
VARIACION TOTAL = VARIACION ENTRE + VARIACION INTRA
donde:
— Variaci6n intra
Visca = Viyy — VIB IVI,
siendo:
ANALISIS DE LA VARIANZA_ 429
— Variaci6n entre del factor A
Si se supone que los efectos del factor A son nulos:
VE yas) = Vly — VE IV
siendo:
VW = SY YOu -FP
fal jal fal
WL YE a-Z)Mu-P)
fal tt
Vi, x > SiZ_-Z.¥ con¥., yZ.;
tal fel
con ¥,, y Z., como las medias de ¥,, y Z, para el nivel j del factor B.
Si se supone que los efectos del factor A no son nulos, V/",,.y) Se descompone en
el efecto debido al factor A y el efecto residual. Restando ef efecto residual, Ia va-
riacién entre para el factor A queda:
VE(A) 08) = Vesey ~ VEaan
Como:
+ Ii, =VE(A),, + V1,
+ I, =VE(A),, + Vy
+ I =VE(A),, +VL,
430 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
VECA), = am SZ.
VE(A),, =am(Z,.—
‘a
VE(A),
=qm¥(Z,.-Z.°
a
Y,.y Z,, como las medias de Y,, y Z,, para el nivel i del factor A.
— Variacién entre para el factor A queda:
VE(A) yeaa = (VE(A),, + VE, ]-[VE(A),, + VI, P IVE(A),, + VI,,1- V1,
tas)
— Variacién entre del factor B
Siguiendo un proceso andlogo se llega a que la variacién entre para el factor B es:
VE(B),y(44) = [VE(B),, + VIyy1—(VE(B),y + V1, P AVE(B).. + Vle.1—VIyaay
a
ANALISIS DE LA VARIANZA 431
— Efecto interaccién de los factores A y B:
EFINT(AB), yas) = [VE(AB),, + VI,,]-[VE(AB),, + VIP NVE(AB),, + V1..}— Vyas
con:
VE(AB),, = nS, G,-
al fat
VEAB),, = mS. YZ, -Z,.-Z.,+Z.9
fat Jal
Resta por contrastar las hipotesis nulas de efectos diferenciales nulos.
El test F para contrastar la hipétesis de nulidad de efectos relativa al factor A
(a, =0) es:
VE(A) cay
VE yaa Mk = Pq
)
El test F para contrastar la hipétesis de nulidad de efectos relativa al factor B
(y= O)es:
— VEB) ys) (P—V
Viyyaay Mk Pq-1)
Por ultimo la hipétesis de efecto interaccién nulo se contrasta del siguiente
modo:
EFINT(AB) ys(agy (DP — )(q- 1)
Vyas Kk = pq 1)
EJEMPLO 13.5. Se plantea aqui un nuevo ejemplo. Se quiere saber si el nimero
de licencias para vender alcohol en los EEUU tiene relacién con el ntimero de acci-
dentes (Y). Con el fin de comprobarlo se estudian en varias zonas la relacién entre es-
432 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
tas variables. Se distinguen dos establecimientos: restaurantes y tiendas. Y se utiliza
como variable control (Z) el ntimero de accidentes ocurrido en el afio anterior al pe-
riodo de andlisis. De este modo el estudio se puede realizar como un ANCOVA
para dos factores, donde el factor A es la concesién de la licencia a tiendas (con dos
categorfas en funcién de si existe o no dicha concesién) y el factor B es la concesién
de la licencia a restaurantes (con las mismas categorias que A). Los datos se muestran
a continuacién:
Y Tienda $I | TiendaNO | __ Media
Restaurante. 226 229
SI 229 190
215 (214,5) | 195 (204) 209,25
188 202
Restaurante. | 226 177
NO 196 225
198 (206,5) | 167 (186,25)] 196,375
206 176
Media 2105 195,125, 202,81
Entre paréntesis figura la media aritmética de cada celda.
El propésito es contrastar el impacto sobre la variable dependiente de los factores
Ay By su combinacion. Los resultados del anilisis se muestran a continuaci6n:
4 Tienda S! | TiendaNO | Media
Restaurante. | 226 248
St 239 208
217 (209,75)| 225 (230) 218,75
177 239
Restaurante. | 252 190
NO. 228 261
240 (241,5) | 194(215,5) | 229,94
246 217
Media 225,625 222,75 224,34
Al ser el valor de F segiin tablas (para un nivel de significacién del 95%) 4,84, to-
dos los valores de F calculados son significativos y se rechazan las tres hipétesis de
nulidad de efectos. Se concluye que la influencia sobre el ntimero de accidentes de
tréfico de la concesi6n de licencias para la venta de bebidas alcohdlicas existe y es
significativa.
ANALISIS DE LA VARIANZA 433
MANOVA
Es una generalizacién del ANOVA a una situacién con multiples variables de-
pendientes, lo que permite analizar la influencia de los distintos factores y sus dis-
tintos niveles sobre las variables dependientes.
Trabajar con multiples variables permite bajo ciertas condiciones detectar as-
pectos no contemplados en ANOVAS independientes.
Desgraciadamente los programas informéticos para MANOVA y MANCOVA, no
estén tan desarrollados como para ANOVA y ANCOVA.
y aunque te6ricamente, no existen limitaciones en las aplicaciones de estos mo-
delos, en la prictica y sin la ayuda de! ordenador, su realizaci6n resulta demasiado
compleja.
Todas las cuestiones y diferencias analizadas con ANOVA, pueden ser ampliadas
con MANOVA, contando ademés con la posibilidad de determinar la importancia de
la variable dependiente, es decir, nos indica que variable dependiente refleja mas cla-
ramente el comportamiento o comportamientos afectados por la variable indepen-
diente.
Las técnicas para MANOVA han sido investigadas y desarrolladas en un contex-
to de investigaci6n experimental, pero no existe un desarrollo matemético diferente al
del andlisis de funciones discriminantes, es més, hay programas informédticos como el
BMDP que los aplica de la misma manera.
La diferencia principal con el andlisis de funciones discriminantes es que MA-
NOVA se aplica en situaciones experimentales en donde algunas de las variables in-
dependientes son manipuladas como parte de Ia investigacién. Los sujetos son asig-
nados a grupos de tal manera que los grupos son homogéneos. Mientras que los
anélisis de funciones discriminantes son usados en situaciones donde los grupos
esta formados naturalmente y no necesariamente han de ser homogéneos.
EJEMPLO 13.6. Se busca testar que la ansiedad, definida
de inestabilidad, varia en funcién del tratamiento que se aplica.
-giin distintos niveles
Flojo Medio Fuerte
wre] wal iol wri wal il wr] wal io
TRA. 15} 108 | 110 | 100 | 105 | 115 89 8 99
98 | 105 | 102 | 105 95 98 | 100 85 | 102
107 98 | 100 95 98 | 100 | 90 | 95 {| 100
PLA. 90 | 92 | 108 70 | 80 | 100 65 62 | 101
85 95 | 115 85 68 99 so | 70 | 95
80 81 95 78 82 | 105 2 73 | 102
B34 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Este ejemplo tiene dos variables independientes. Grado de inestabilidad y trata~
miento. El grado de inestabilidad tiene tres niveles: flojo, medio y fuerte. Mientras
que la variable tratamiento (TRA) tiene dos niveles: tratamiento y efecto placebo
(PLA) (no tratamiento). Tres nifios son asignados a cada uno de los seis grupos, 0
combinaciones de las variables independientes. Se establecen dos niveles para la va-
riable dependiente: grado para el nivel de prueba (WRAT-R, es decir, «WIDE RAN-
GE ACHIVEMENT TEST») y la puntuacién para el subtest aritmético (WRAT-A).
En adicién una puntuacién /Q (mediciones pre-experimentales) estn dados para
cada nifio.
El objeto del andlisis MANOVA es determinar:
1. Sin tener en cuenta los distintos niveles de inestabilidad jafecta el trata-
miento en los dos test (WRAT-R y WRAT-A)?
2. Los efectos del tratamiento en los dos test ,varfan en funcién del grado de in-
capacidad?
El primer objetivo se responde testando el efecto principal del tratamiento, mien-
tras que para el segundo objetivo se necesita analizar la interacci6n entre tratamien-
to y grado de incapacidad.
Una tercera cuestién se responde automticamente con cualquier programa que
nos de el TEST-F: Estan los niveles de WRAT afectados por los niveles de incapa-
cidad?
MANCOVA
Es la extensién multivariante del andlisis de la covarianza, es decir, después de los
ajustes estadisticos para uno o mas factores correctores, ,existen diferencias signifi-
cativas entre los grupos en la mejor combinacién lineal de las medias de las variables
dependientes?
Las combinaciones lineales de las variables dependientes, estén ajustadas esta-
disticamente para las diferencias en los factores correctores. La nueva combinacién li-
neal ajustada de variables dependientes, representa la combinacién que se obtendria
si todos los sujetos empezaran con el mismo nivel o en la misma categoria de varia-
ble independiente.
En el ejemplo anterior, para conseguir una mejor medida del efecto del ansioliti-
co, se afiaden factores correctores. Antes del periodo de tratamiento, voluntarios de
os tres grupos de tratamientos, serdn evaluados segiin tres tipos distintos de test para
medir la ansiedad. El test estadistico medira ahora, que ansiedad difiere segtin que
tratamiento después de ser ajustado para diferencias que pudieran existir antes del tra-
tamiento en los tres niveles de ansiedad.
ANALISIS DE LA VARIANZA 435
13.4. MODELOS ANOVA EN EL SPSS
13.4.1. Opciones de! programa
La opcién para realizar un andlisis de la varianza en cualquiera de las vertientes
vistas se encuentra en la opcién Modelo lineal general. En ella encontramos las si-
guientes opciones.
1. opeién: Andlisis Factorial simple
Realiza un anélisis de la varianza, El procedimiento ANOVA factorial simple lle-
va a cabo un andlisis de varianza para disefios factoriales. Contrasta la hipétesis de
que las medias de grupo o casilla de la variable dependiente son iguales. Si el modelo
contiene cinco factores menos, el modelo por defecto es factorial completo, es de-
cir, se incluyen todos los términos de interaccién factor por factor hasta el de orden
cinco. Aunque pueden especificarse covariables, ANOVA factorial simple no permite
el andlisis completo de la covarianza,
Estadisticos. Media de casillas, tamafio de muestra de casillas, tabla de anilisis
de varianza, coeficientes de covariables, R, R**2. Tabla de andlisis de clasificacién
miltiple que contiene una lista de los efectos de categorias sin corregir para cada fac-
tor, efectos de categorias corregidos respecto a otros factores, efectos de categorias
corregidos respecto a todos los factores y covariables y valores eta y beta. Numero to-
tal de casos, ntimero y porcentaje de casos incluidos y excluidos del modelo.
436, DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Para ver el funcionamiento realizaremos el andlisis en SPSS de distintos ejemplos
vistos en el capitulo.
eee
EJEMPLO 13.7. Anova para un factor. Reproducimos en el SPSS el ejemplo
13.1 sobre la relacién entre la decoraci6n del restaurante y la valoracién de los
clientes. Tras pulsar la opcién Analisis factorial simple. Aparece el siguiente cuadro
de didlogo en el que introduciremos la variable dependiente y los factores:
‘Tras pulsar Aceptar presentamos la salida que nos ofrece el programa.
Salida del SPSS
ANOVA*”
Método tinico
Suma Medida
cuadrados| gl | cuadrdtica| FF Sig
VALOR Efectos decoracién 10,000
principales _restaurante
10,000 | 20,000 | 0,002
Modelo 10,000 1 | 10,000 | 20,000 | 0,002
Residual 4,000 8 | 0500
Total 14,000 9 | 1556
* VALOR por decoraci6n restaurante.
» Todos los efectos introducidos simulténeamente.
ANALISIS DE LA VARIANZA
Resumen del procesamiento de los casos"
Casos
Incluidos Excluidos Totat
N Porcentaje N Porcentaje N Pocentaje
10 66,7% 0 0,0% 10 100,0%
* VALOR por decoracién restaurante.
En ella encontramos los siguientes elementos:
La variable Suma de cuadrados (Modelo) que muestra la variacién entre.
437
La variable Suma de cuadrados (Residual) que muestra la variacién intra (den-
tro de cada grupo).
La variable Suma de cuadrados (Total) que muestra la variacién total. Como
vemos equivale a la suma de las dos anteriores.
Asimismo muestra el valor de la F y su significatividad, en este caso al ser un va-
lor inferior a 0,05 (en conereto 0,002) se rechaza la hipétesis nula aceptando Ia rela-
ci6n entre las dos variables analizadas (decoraci6n y valoracién del restaurante).
EJEMPLO 13.8. _Anova para dos factores (disefio balanceado). Reproducimos el
ejemplo 2 sobre Influencia de las ventas del producto del hilo musical y situacién del
producto. De nuevo utilizamos la opcién Anilisis factorial simple
438, DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Se presenta a continuacién la salida del SPSS.
Resumen del procesamiento de los casos*
Casos
Incluidos Excluidos Total
N | Porcentaje | N | Porcentaje | __N Pocentaje
12 100,0% 0 0,0% 12 100,0%
* Valoracién por lugar, hilo musical.
ANOVA*®
Método tinico
‘Suma Medida
cuadrados| gl | cuadrética] —F Sig
Valorac. Efectos (Combinadas)] 60,000 2 | 30,000 | 20,000 | 0.001
principales lugar 48,000 1 | 48,000 | 32,000 | 0,000
hilo musical | 12,000 1] 12000 | 8,000 | 0.022
Interaciones lugar x
de orden 2 —hilomusical | 12,000 1 | 12,000 | 8,000 | 0,022
Modelo 72,000 3 | 24,000 | 16,000 | 0,001
Residual 12,000 8 | 1,500
Total 84,000 u_| 7,636
* Valoracién por lugar, hilo musical.
» Todos los efectos introducidos simulténeamente,
‘Tras mostrar el resumen del procedimiento aparecen la variaci6n entre del primer
y segundo factor combinados, sin tener en cuenta las interacciones (60). Obtenemos
ademis el valor de la F y su significatividad (0,01) que nos sefiala la existencia de re-
lacién entre las dos variables en su conjunto y la variable dependiente.
Lugar: Obtenemos la variacién entre (48) de la variable lugar de colocacién
(48), y su significatividad (0,000).
Hilo musical: Muestra la variaci6n entre de la variable (12), ofreciendonos tam-
bién su significatividad (0,0022).
‘A continuacién obtenemos el valor referente a la influencia de las interacciones
entre las dos variables. Dado que el valor F (8) es significativo (0,022) se debe con-
cluir que existe relacién entre las dos variables asociadas y la variable dependiente.
‘A continuaci6n se muestra la variacién entre del modelo (Modelo) que es igual a
72 (60 + 12), la variaci6n intra (Residual) igual a 12, y por tiltimo la total igual a 84.
Podemos comprobar que 72 + 12 = 84.
Como en el caso anterior se ofrece el valor de la F y su significatividad.
ANALISIS DE LA VARIANZA_ 439
EJEMPLO 13.9. Reproducimos el ejemplo 13.3. Anova para dos factores (disefio
no balanceado). Como ejemplo de esta opcién tenfamos la relacién entre la valora~
ciGn de la economfa segiin el sexo (hombre, mujer), y a situacién laboral (parado, no
parado). Para efectuarla procedemos de la misma manera que en los casos anteriores.
A continuacién se muestran los resultados obtenidos:
Resumen del procesamiento de los casos"
Casos
Incluidos Excluidos Total
N | Porcentaje | N | Porcentaje | N | Pocentaje
15 100,0% 0 0,0% 15 100,0%
* VALORAC por sexo, situacién laboral.
ANOVA*®
Método itnico
‘Suma Medida
cuadrados| gt | cuadrdtical—F Sig
VALORAC Efectos (Combinadas) | 82,545 2| 41,273 | 25,222 | ~ 0,000
principales sexo 10971 1| 10971 | 6705} 0.025
situacién laboral | 43,886 1] 43,886 | 26,819 | 0,000
Interaciones sexo x
de orden 2 situacién laboral | 0,000 1] 0,000 | 0,000 | 1,000
Modelo 88,000 3] 29333] 17,926 | 0,000
Residual 18,000 1} 1,636
Total 106,000 14] 7971
* VALORAC por sexo, situacién laboral
® Todos los efectos introducidos simulténeamente.
440, DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
En primer lugar se nos indica la existencia de 15 casos en el anilisis, habiendo
sido todos inclufdos en el andlisis. En el segundo cuadro aparecen la variaciGn entre
de los dos factores sin tener en cuenta las interacciones (82,545), y las del primer y
segundo factor (10,971) y (43,886) tomados individualmente. Como se observa:
10,971 + 43,886 # 82,545
En el caso de las interacciones el valor de Ja F es igual a 0, y la significativi-
dad (1). Se comprueba asi la no significatividad (1) de la interaccién entre las dos va-
riables.
Se muestra a continuacién la variacién entre del modelo (Modelo) que es igual a
88, la variacién intra (Residual) igual a 18, y por ltimo la total igual a 106.
Como en el caso anterior se ofrece el valor de la F y su significatividad.
2. opeién: Procedimiento MLG Factorial
Utilizaremos esta opcién para realizar andlisis de la covarianza, El procedimien-
to MLG Factorial general proporciona andlisis de regresién y andlisis de varianza
para una variable dependiente mediante uno o ms factores y/o variables. Se pueden
investigar interacciones entre factores as{ como los efectos de los factores indivi-
duales, algunos de los cuales pueden ser aleatorios. Ademés, se pueden incluir los
efectos de las covariables y las interacciones de covariables con factores. Para el and-
lisis de regresién, las variables (predictoras) independientes se especifican como
covariables.
En la caja de dislogo encontramos la posibilidad de distinguir efectos fijos y efec-
tos aleatorios. Un modelo es de efectos fijos si de cada factor se incluyen todas sus
posibles modalidades; es decir, todos los individuos de la poblacién pueden enmar-
carse 0 ser asignados bajo una de tales modalidades. Se trataré de un modelo de efec-
tos aleatoriamente seleccionadas de entre todas las posibles. El modelo de efectos
mixtos incluye factores de ambos tipos.
Se pueden contrastar los modelos equilibrados y no equilibrados. Un disefio
est equilibrado si cada casilla del modelo contiene el mismo nimero de casos.
‘Ademés de contrastar hipstesis, MLG Factorial general produce estimaciones de pa-
rémetros.
Los contrastes a priori usados de forma comiin estén disponibles para realizar
contrastes de hipétesis, Ademds, después de que una prueba F global haya mostrado
cierta significaci6n, se pueden utilizar las pruebas post hoc para evaluar las diferen-
cias entre las medias especificas. Las medias marginales estimadas ofrecen estima-
ciones de valores de las medias pronosticados para las casillas del modelo y los
graficos de perfil (grdficos de interacciones) de estas medias permiten visualizar f4-
cilmente algunas relaciones.
Se pueden guardar residuos, valores pronosticados, distancia de Cook y valores
de influencia como variables nuevas en el archivo de datos para comprobar su-
puestos.
ANALISIS DE LA VARIANZA 441
EJEMPLO 13.10. Anilisis Ancova: Se pretende analizar la relaci6n entre la asis-
tencia anual a conciertos, el nivel socioeconémico (medido en 3 niveles), y el nivel
cultural (medido en tres niveles). La edad se considera una covariable. Al pulsar la
opcién MLG factorial aparece la siguiente caja de didlogo. En ella introduciremos la
variable dependiente (en nuestro caso n.° de conciertos), y los factores (nivel socio-
econémico, y nivel cultural).
Una de las opciones del programa permite la visualizacién de los parémetros del
modelo, Esta posibilidad se encuentra tras pulsar el bot6n Opciones.
442
Presentamos a continuacién la sa
DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
ia del SPSS.
Factores inter-sujetos
Etiqueta valor | N
Nivel cultural 1,00 | Bajo 6
2,00 | Medio 9
3,00 | Alto 5
Nivel socioeconémico 1,00 | Bajo 8
2,00 | Medio 6
3,00 | Alto 6
Pruebas de los efectos inter-sujetos
Variable dependiente: asistencia a conciertos.
‘Suma Parémetro
cuadrados Media deno | Potencia
Fuente | tipoit | gt |euadrétical —F Sig. |centralidad| observader
ae 1132,896° 7| 161842] 3537] 0027 | 24,758} 0,806
Interseccién | 25,933 1] 25933] 0567] 0466] 0567 | 0,107
Edad 6313 1] 6313] 0138] 0717] 0138 | 0.068
Cultural 10,829 2[ sais] ous] oss | 0237 | 0,068
Socioeco, 285,865 2 142932| 324] 0081] 6247] 0491
ene 0313 2| 0257] 0006] 0994] 0011 | 0051
Socioeco.
Error 549,108 2 45,759
Toul 3302,000 20
‘Total corregido| 1682,000 19
* Caloulado con alfa = 0,05.
© Rcuadrado =:
),674 (R cuadrado corregido = 0,483).
ANALISIS DE LA VARIANZA 443
Estimaciones de los parémetros
Inervalo de confianca
Pardmero
Valor Eror uimite | Limite | deno | Povenia
dependiente —Paramero B | pico | ot Sig. | inferior | superior |centratdad) obserrad
‘sintencia| T1618 0208] 9.692 40935[ 1.345] 0.236]
conciertos 0199 on7| 0360] 0.508] 0471] 0.064]
8651 359] -20'424) 17.276] 0,182] 0.053]
5.875 0379] 11885) 13.718] 0,156] 0.052]
7596 opsi| 32,284) oes] 2,068] 0.473]
7361 0.189] 28081] 6.173] 1,393] 0.250]
11,733] 0.040] 0.969] -25.091] 26,037] 0,040] 0.050
[SOCIOECO = 1,00)
[CULTURAL = 1,00)
* o A 7 : 7
{socI0Eco:
[CULTURAL
* o c 7 7
970} -o98) 092s] -22,241 20,333] 0.098] 0051
[SOCIOECO = 2,00)
[CULTURAL = 2,00)
o 7 7 7 7
[SOCIOECO = 3,00]
[CULTURAL = 3.00)
* o ‘| | : A
[SOCIOECO = 2,00}
[CULTURAL = 3,00]
. o | 7
[SOCIOECO = 3,00]
* Caleulado con alfa = 0,05,
» Al pardmetro se le ha asignado el valor cero porque es redundante,
En el primer cuadro aparece el nimero de sujetos en cada uno de los niveles.
El cuadro 2 es de interpretacién similar a la de los ANOVA con dos o més fac-
tores, Obtenemos asf Ia suma de cuadrados del modelo (variaci6n entre), la residual
(error), y la total. Se puede comprobar que la suma de las dos primeras es igual a la
ltima: 1132,896 + 549,104 = 1682. En el apartado de interseccién obtenemos los da-
tos para los factores (nivel socioecondmico, y nivel cultural), y para la covariable
(edad). El programa realiza el contraste F, determinando la significatividad de las va-
riables, y el modelo. A continuacién se nos ofrecen datos sobre la interaccién de los
factores. Al ver el valor de la F(0,006), y su significatividad (0,994) deducimos que
no existe interaccién entre los mismos.
Por tltimo, obtenemos el coeficiente de determinacién del modelo igual a 0,674
(0,483 corregido).
El tltimo cuadro ofrece la estimacién de los parémetros del modelo. Como se ve
las variables no son significativas para un nivel de error del 5%.
Se puede comprobar que es igual a la divisién entre la suma de cuadrados del modelo, y la suma de
ccuadrados total (varianza total). (1132,896/1682 = 0,67).
444 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
3.* opci6n: MLG Multivariante
El procedimiento MLG Multivariante proporciona andlisis de regresién y anélisis
de varianza para variables dependientes multiples por una 0 més covariables 0 va-
riables de factor. La opcién MLG mulivariante permite especificar mas de una va-
triable explicada.
Las variables de factor dividen la poblacién en grupos, Utilizando este procedi-
miento de modelo lineal general, es posible contrastar hipétesis nulas sobre los efectos
de las variables de factor en las medias de varias agrupaciones de una distribucién con-
junta de variables dependientes. Puede investigar las interacciones entre factores asi
‘como los efectos de los factores individuales. Ademés, se pueden incluir los efectos de
las covariables y las interacciones de las covariables con los factores. Para el andlisis de
regresiGn, las variables (predictoras) independientes se especifican como covariables.
Se pueden comprobar los modelos equilibrados y desequilibrados. Un disefto
esté equilibrado si cada casilla del modelo contiene el mismo numero de casos, En un
modelo multivariado, las sumas de cuadrados debidas a los efectos en el modelo y las
sumas de cuadrado error se encuentran en forma de matriz més que en la forma esca-
Jar encontrada en andlisis univariado. Estas matrices se Haman matrices SCPC (sumas
de cuadrados y productos cruzados). Los contrastes a priori utilizados con frecuencia
se encuentran disponibles para realizar los contrastes de hipotesis. Ademas, después de
que una prueba F global haya mostrado significacién, se puede utilizar una prueba post
hoe para evaluar las diferencias entre medias especificas. Las medias estimadas mar-
ginales proporcionan estimaciones de valores medios pronosticados para las casillas
del modelo y los gréficos de perfil (gréficos de interaccién) de estas medias le permi-
ten visualizar facilmente algunas de estas relaciones. Las pruebas de comparaciones
miiltiples post hoc se realizan de forma separada para cada variable dependiente.
Se pueden guardar residuos, valores pronosticados, distancia de Cook y valores
de influencia como variables nuevas en el archivo de datos para comprobar supuestos.
También se dispone de una matriz SCPC residual, que es una matriz cuadrada de su-
mas de cuadrados y productos cruzados de residuos, una matriz de covarianza resi-
dual que es la matriz SCPC residual dividida por los grados de libertad de los resi-
duos, y la matriz de correlaci6n residual, que es la forma tipificada de matriz de
covarianza residual.
Ponderacién MCP permite especificar una variable usada para aplicar a las ob-
servaciones ponderaciones diferentes para un anilisis de minimos cuadrados ponde-
rados (MCP), por ejemplo para compensar Ia distinta precisién de las medidas.
EJEMPLO 13.11. _Un profesor desea saber la influencia que en las notas de ma-
tematicas y lengua, tiene el coeficiente de inteligencia (medido en una escala de tres
valores: alto, medio, bajo), y las horas de estudio de sus alumnos medido también en
una escala (una hora diaria, dos horas diarias, més de dos horas diarias). Tras intro-
ducir los datos y pulsar la opcién obtenemos la siguiente caja de didlogo donde in-
troducimos las variables dependientes (calificaciones de lengua y matemiticas), y los
correspondientes factores (coeficiente de inteligencia y horas de estudio).
ANALISIS DE LA VARIANZA 445
Tras hacerlo pulsamos la opcién Aceptar, obteniendo la salida del SPSS.
Factores inter-sujetos
Etiqueta valor N
Horas de estudio 1,00 | 1 hora diaria 6
2,00 | 1 hora diaria 18
3,00 | Mas de dos horas diarias 5
Coeficiente de inteligencia 1,00 | Bajo 5
2,00 | Medio 10
3,00 | Alto u
El primer cuadro de Ia salida es similar al visto en opciones anteriores. En lo que
se refiere al segundo cuadro observamos una serie de tests estadisticos multivariantes
que nos informan de la significatividad del modelo en su conjunto. Es decir, nos in-
dican si los factores (inteligencia, y horas de estudio) influyen en las notas de lengua
y matemiticas. Se puede ver la significatividad del modelo en todos los tests gene-
rales y de las variables (0,000), con la excepcién del parémetro de interaccién estu-
dio x inteligencia.
446 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Pruebas de los efectos inter-sujetos
Suma Pardmero
Variable | cuadrados| Media deno | Potencia
Fuente dependiente |" tipottt | gl |cwadrdtica]__F | Sig. _|centraidad|observader
peoelo) notas: 69,913" 6 11,652 19,045 0,000 | 114,267 1,000
comegido de lengua
pots de | ras 6| 12860} 15575] 0000] 93.451) 1,000
Imereept a 490,691. 1] 490,691 | 801,990 0,000 | 801,990 1,000
de lengua
notas de
nots de | 505.281 1] 505,281] 611,974] 0.000] 611.974] 1,000
ogni) al 27,895 2 14,948 22,796 0,000 45,592 1,000
de lengua
eee 31,849 2 15,924 19,287 0,000 38,574 1,000
rmatemiticas
INTEL sos 11,335 2 5,668 9,263 0,002 18,526 0,953
de lengua
aaa 10,963 e 5,482 6,639 0,007 13,278 0,862
rmatemétias
ESTUDIO notas
TG ee 2.368 2} ase} 1936] oa] 3am] 03st
notasde 240 2} 1070] 1296] 0297] 2591] 0246
Error notas
ao 115 9] 0612
eee 15,687 19 0,826
mateméticas
Total notes
no aa | 16000] 26
notas de
mateméticas oe -
Total nots
corregido de lengua 81,538 e
tan ae 92,846, 25
rateméticas
* Calculando con alfa = 0,05.
» R cuadrado = 0,857 (R cuadrado corregido = 0,812).
© Rcuadrado = 0,831 (R cuadrado corregido = 0,778).
ANALISIS DE LA VARIANZA. 447
Contrastes multivariados*
Pade
Grdetn| tet eno” | Poenie
Reto valor | _# | bows | erorat | sig. enna eerste
eee 0986] 611,88%] 2,000] 18,000] 0,000] 123,778] 1,000
Lambnde | gore! suiaa%] 2000/1000] 0000] 1223778] .o00
aaa 67,988 | 611,889 2,000 18,000, 0,000 | 123,778 1,000
Hocing
Ramer ) gross] ouisi] 2900] 180m] ooo] r2zn7r8] 100
ESTUDIO Twa [ ogia| ser] 000] ago] a0] asaue| owe
lampaace | o497| 11200] 4000} 6000] 0000} 45200] 1000
eed 4,046, 17,197 4,000 | 34,000 0,000 | 68,788. 1,000
Hace
Ratz mayor 4,036 | 38,343° 2,000 19,000 0,000 | 76,687 1,000
sey
INTELIG Tae [ois sasr] 4000] a8] a2] 21046] asso
lambande ] 9362] sox] 4000} 6000] ooo} 23840] os71
Taade
Trarte —| 1556] gots] 4000] 34000] oom] 2eass| ope
Raz eager .
same] raaee | 2q00] 19000] goo] 25768} 0903
sey
ERTUBIO aaa :
ESTUDIO Tava oar] sae] 4000] akon] 0226] 902] oats
lamsiade | oes} 1a] com] seo] 0202] 5741) osm
Deke 0,325 1,382" 4,000] 34,000 0,261 5,528 0,383
Hoching
Raiz mayor 0,248 2,353" 2,000 19,000 0,122 4,706 oat
soy
* Calculando con alfa
0 exacto.
co es un limite superior para la F el cual oftece un limite inferior para el nivel de significacién.
4 Disefio: Intercept + ESTUDIO + INTELIG + ESTUDIO x INTELIG.
> Bstadis
«© Blestadi
0.05.
448 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
El tercer cuadro nos ofrece estadisticos ya vistos en otras opciones. En primer lu-
gar tenemos la variaci6n entre (suma de cuadrados del modelo) de cada una de las va-
riables explicadas. Como se puede comprobar en ambos casos el modelo disefiado es
valido, demostrandose la relacién de los factores con las variables explicadas. Mas
abajo obtenemos la relacién que cada uno de los factores (horas de estudio (estudio),
coeficiente de inteligencia (inteligencia), e interaccién (estudio x inteligencia)) con
cada una de las variables explicadas, (notas de lengua y notas de matematicas). Se
comprueba la significatividad de los factores estudio (0,000 para ambas notas) e in-
teligencia (0,002 para las notas de lengua, y 0,007 para las notas de matematicas), he-
cho que no sucede en la interaccién que se da como no significativa [0,172 (notas de
lengua), y 0,297 (notas de matemiticas)].
A continuacién se obtienen la suma de cuadrados residual y total para las dos va-
riables explicadas?.
Finalmente se puede observar el coeficiente de determinacién del modelo para
cada una de las variables dependientes (0,857 para las notas de lengua; y 0,831 para
Jas notas de matemiticas)*.
4.* opcién: MLG Medidas repetidas
MLG Medidas repetidas analiza grupos de variables dependientes relacionadas
que representan diferentes medidas del mismo atributo. Este cuadro de didlogo per-
mite definir uno o mas factores intra-sujetos para su utilizacion en MLG Medidas re-
petidas. Tenga en cuenta que el orden en el que se especifiquen los factores intra-su-
jetos es importante, Cada factor constituye un nivel dentro del factor anterior. Para
utilizar Medidas repetidas, deberd establecer los datos correctamente. Debe definir los
factores intra-sujetos en este cuadro de didlogo. Observe que estos factores no son va-
riables existentes en sus datos, sino factores que deberd definir en la caja de didlogo
que aparece tras pulsar la opcidn.
EJEMPLO 13.12. Se mide la marca de un grupo de atletas al correr los 100 me-
tros, y su evolucién en 4 tiempos que se recogen en las variables: Marca 1, Marca 2,
Marca 3, y Marca 4, En la caja de didlogo se deberé seffalar el nombre del factor in-
tra-sujetos (marca), y los niveles que esta tendré (4) correspondientes al grupo de va-
riables que engloban las marcas de los atletas. Tras hacerlo pulsamos aifiadir, y tras
hacerlo «defini».
* Como se observa la suma de cuadrados total = suma de cuadrados modelo+suma de cuadrados error
para cada una de las variables.
En el caso de las notas de lengua: 69,913 + 11,625 = 81,538
En el caso de las notas de matemiticas: 77,159 + 15,687 =92,846
* Se puede comprobar que:
Enel caso de las notas de lengua: [(69,913/81,538) = 0,857]
En el caso de las notas de mateméticas: [(77,159/92,846) = 0,831]
ANALISIS DE LA VARIANZA 449.
A continuacién se obtendré la siguiente caja de didlogo donde se debe definir las
cuatro variables que en nuestro caso definen las variables intra-sujetos (marcal,
marca2, marca3, y marca4). La opcién factor intra-sujetos permite distinguir el factor
intra-sujetos por grupos, en nuestro caso lo diferenciamos por el sexo: marcas en
hombres, y en marcas en mujeres.
Tras pulsar Aceptar obtenemos la salida del SPSS.
Factores inter-sujetos
‘Medida: MESAURE_1
Marca Variable dependiente
1 MARCAL
2 MARCA2
3 MARCA3
4 MARCA4
450 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Factores inter-sujetos
Etiqueta valor |__N
Sexo del atleta 0,00 | Mujer ul
1,00 | Hombre 12
Contrastes multivariados*
Partner
Gtdets | cra ‘emo | Pencia
Efecto Valor F hipétesis | error gl ‘Sig. _|centralidad| observada’
a Ui 0,776 | 21,949" 3,000 | 19,000 0,000 | 65,848 1,000
Lambinde | 9224} 214| 20m0| 19000] ooo} esse | 1000
Trade
Tarde | sais] 2199] 3.000] 13.000] aon] esas] 1.00
Raimayor | 34] 219%] 3000] 19.000] a0] esas] 1.00
MARCA asad :
MARCA Tas oor} one] 3000 19mm] ovos] sma] oars
tanpinde | 953] care | a0] 13000] ovo] 14s) oan
haenae 0,075 | 0,474 3,000} — 19,000 0,704 1423 0,128
Rafe mayor 0,075 0,474" 3,000 19,000 0,704 1,423 0,128
Roy
* Caleulando con alfa = 0,05,
® Bstadistico exacto.
© Diseiio: Intercept + SEXO.
Disefio intra sujetos: MARCA.
Prueba de esfericidad de Mauchly”
Medida: MESAURE_1
Epsilon
Fyecto wae | Chi-cuadrado 7
intra-sujetos | Mauchly | aprox. gt | Sig. | Dreenhouse-Geisser | Huynh-Feldt | Limite-inferior
Manca [013 | wos | s [000] 04st osm] 0333
Contrasta la hipétesis nula de que la matriz de covarianza de error de las variables dependientes transfor-
madas en proporcional a una matrix identidad.
* Se puede utilizar para ajustar los grados de libertad de las pruebas de significacién promediados. Las
pruebas corregidas se mostrardn en las capas (por defecto) de las pruebas de la tabla de efectos intra
sujetos.
* Disefio: Intercept + SEXO.
Disefto intra sujetos: MARCA.
ANALISIS DE LA VARTANZA 431
Pruebas de los efectos inter-sujetos
Medida: MESAURE_1
Esfericidad asumida.
Suma Pardmetro
cuadrados Media deno | Potencia
Fuente tipo I gl |euadrética] — F Sig. | ceniratidad| observada'
MARCA. 13,259 3] 4420] 54,049 | 0,000 | 162,147 1,000
MARCA x
cee 0,258 3 |s.616E-02| 1,054] 0,375 | 3,161} 0,272
Error
ny 5,152 63 |8,177E-02
* Calculado con alfa = 0,05.
Pruebas de los efectos inter-sujetos
Medida: MESAURE_1
‘Suma’ Parémetro|
Variable | cuadrados| Media deno | Potencia
Fuente dependiene | tipo | gl |ewadrétical —F Sig. |centratidad| observada"|
MARCA MARCA_L 13,257 1} 13.287] 64271 [ 0,000] 64.271] 1,000
MARCA2 |8.432E-04 1]34328-04| 0,033] 0.857] 0.033] 0,054
MARCA_3_ |1,455E-03 1}rasse-3| 010s} 0,749] 0,105] 0,061
MARCAx — MARCA_1 0.248; 1] 248 [1.208] 0285] 1,204] 0,182
SEXO MARCA 2 |2,582E-03 1)2,5826-03] 0,103] 0,752] 0,103) 0,061
MARCA_3__|7,542E-03 175426.03| 0544] 0,469] 0,544 0,108
Error MARCA 4332 21] 0206
(MARCA) MARCA_2 0529 21 |2,5198-02
MARCA. 3 0291 21 |1,387E-02
* Calculando con alfa = 0,05.
Pruebas de los efectos inter-sujetos
Medida: MESAURE_1
‘Variable transformada: Promedio.
Suma Pardmetro
cuadrados Media deno | Potencia
Fuente tipo IIL gl | euadrdtica] FF Sig. _ | centralidad| observader|
Intercept _|14110,986 1 [14110,986 | 5711190 | 0,000 | $711,190 | 1,000
SEXO 109,546 1{ 109,546 | 44,337 | 0,000 | 44,337 1,000
Error 51,886 2 2,471
© Calculado con alfa = 0,05.
452 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Tras obtener la salida del SPSS se observa la significatividad del efecto evolucién
en las marcas , y la no significatividad de la interaccién sexo x marca. Es decir, se
constata que tanto hombres como mujeres mejoran la marca en cada intento (y por
ello la variable es significativa), pero no se observa més nivel de mejora en los hom-
bres que en las mujeres. Sf se observa sin embargo que existen diferencias significa-
tivas en las marcas de hombres y mujeres.
CAPITULO 14
ANALISIS FACTORIAL Y DE COMPONENTES
PRINCIPALES
14.1. INTRODUCCION
El andlisis factorial procede del campo de la sociologia. Se parte de la idea (Spe-
arman, 1904) de que cuando entre varios fendmenos hay interrelaciones, éstas se pue-
den deber a que lo que se mide son facetas o manifestaciones de un mismo fenémeno
subyacente, no edible y observable directamente. El fenémeno (0 fenémenos) sub-
yacentes se denominan Factores y es comtin denominar el estudio de estos factores
como Anilisis Factorial o Anilisis Factorial de Correspondencia Multiples (AFCM).
El caso puede resumirse de forma que si en un modelo las variables (observables
y medibles) muestran un alto grado de correlaccién entre sf esto puede deberse a la
existencia de unas variables exdgenas al modelo que no son observables directa-
mente, 0 simplemente no conseguimos descubrirlas para nuestro modelo, Estas va-
riables exdgenas son los factores, el objeto del anélisis factorial.
Por ejemplo, si medimos una serie de variables econémicas en las provincias es-
paiiolas, obtendremos, sin duda, un alto grado de correlacién entre ellas. ;S6lo caben
explicaciones casuales? {Cudles serfan las causas y cudles son los efectos? {No se
puede interpretar esas relaciones suponiendo que estamos midiendo de varias mane-
ras distintas el mismo fenémeno y que este fendmeno es el que hace que los datos ob-
servados no sean independientes?
Otro ejemplo puede ser muy actual: si disponemos de las respuestas a una en-
cuesta en que los encuestados se manifiestan mas © menos de acuerdo con la ley del
aborto. Claro esté que las respuestas de los individuos estarén condicionadas por su
ideologia lo que hard que difirieran de manera similar en todas las preguntas que ten-
gan que ver con los diferentes factores ideol6gicos. Estos factores intemios no son me-
dibles directamente, pero se manifiestan a través de las opiniones de los sujetos, pro-
vocando la variabilidad de las respuestas y las correlaciones entre ellas.
454 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
En relacién con un modelo macroeconémico suponiendo que las variables ex6-
genas (Gasto Piblico, Déficit presupuestario, Tasa de Inflaci6n, etc...) son controla-
bles por las autoridades en mayor o menor medida, y las variables endégenas (Con-
sumo, Inversién, Nivel de Desempleo, etc...) son objetivos de politica econémica la
utilidad del Andlisis Factorial puede ser la siguiente:
— El anilisis factorial proporciona la estructura interna, el transformado de
una serie de variables, globalizando el entendimiento del fenémeno, permi-
tiendo elaborar una estructura mds simple, con menos dimensiones que pro-
porciona la misma informacién.
— El anilisis factorial simplifica la modelizacién convirtiendo por eliminacién
de las redundancias expresadas en la alta correlacién de las variables, por
ejemplo, muchas variables econémicas en pocos factores estructurales.
14.2. MODELO CAUSAL Y ANALISIS FACTORIAL
Averiguar las razones por las que se producen correlaciones entre variables eco-
némicas, es uno de los problemas con el que se encuentran frecuentemente los eco-
nomistas.
‘Tradicionalmente la técnica aplicada ha sido la Econometria, que supone que esas
relaciones se deben a influencias causales de unas variables sobre otras, planteando
modelos matemiticos que expresan esas relaciones entre las variables y procediendo
a su estimacion.
Pero otro planteamiento posible, y en muchos casos mas adecuado, es constatar
que no hay variables causa y variables efecto, sino que todas son variables efecto cu-
yos valores y correlaciones se deben a factores subyacentes y no medibles directa-
mente. A este planteamiento responde el andlisis factorial.
Resumiendo las diferencias entre los enfoques del modelo causal y del andlisis
factorial se puede presentar el siguiente esquema:
OBSERVACIONES: X1 X2 (X1, X2, X3, ... Xk)
CORRELACION (X1,X2)_0 (MATRIZ CORRELACIONES SIMPLES R_1)
Modelo causal Andlisis factorial
Explicaciones posibles | X1 — X2 elegida Fox
X2>X1 F3x2
Clasificacién X1 exégena F factor no observable
X2 endégena
Modelo X2=/(X1)
Explicacién X2 < modelo < X1 F © no observable —> X1 X2
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 455
14.3, EL ANALISIS FACTORIAL Y LOS COMPONENTES PRINCIPALES
143.1, Introduccién
En 1.904 Spearman presenta una teorfa psicolégica en la que defiende que las di-
ferencias en los resultados en una bateria de tests entre los individuos dependen de dos
tipos de factores, uno comiin a todos los ests, una capacidad mental general, y un fac-
tor especifico a cada test, y ademés plantea la posibilidad de comprobar esta teorfa ex-
perimentalmente mediante la matriz de coeficientes de correlacién entre los tests.
Esta teorfa se generaliza en los afios siguientes, afiadiendo Spearman a los dos ti-
pos anteriores de factores otro que serian los factores comunes a grupos de fests.
Completan este planteamiento otros autores, como Garnett (1.919) y Thurstone
(1.931) generalizando a un numero indeterminado de factores comunes (obtener su
ntimero serd uno de los resultados del andlisis), y los especfficos. Se crea el modelo
tedrico que se conoce como factores principales.
En 1.901 Pearson presenta un articulo en que plantea la forma matemitica de
ajustar, de manera 6ptima una nube de puntos sobre una recta, un plano, un espacio
de tres, cuatro, etc. dimensiones, lo que da origen a una técnica puramente matemé-
tica que acaba llaméndose componentes principales, fundamentalmente a partir de la
obre de Hotelling (1.933), que le da nombre, y ademés, Ia relaciona con una técnica
matematica preexistente que es la diagonalizacién de una matriz (que se remonta a
mediados del siglo xix).
Con Thurstone, al relacionar el objetivo de factores principales con el andlisis del
rango de la matriz de coeficientes de correlacién, se abre la puerta a la utilizaci6n del
método componentes principales a una transformagion de la matriz de correlaciones.
Aquf es donde los dos métodos entran en contacto y comienza la confusion de la ter-
minologfa; que aumenta mis adelante porque esta técnica, diagonalizar una matriz o
extraer los componentes principales de una matriz, se puede aplicar a otros tipos de
matrices, dando lugar a otras técnicas, algunas de las cuales se les afiade también el
nombre de andlisis factorial.
14.3.2, Componentes principales
Esta técnica consiste en condensar la informacién aportada por un conjunto de K
variables en un conjunto W de componentes, también Ilamados factores, siendo
W Estas puntuaciones son calculadas y guardadas como variables nuevas por el SPSS.
* Para obtener el valor estandarizado se debe restar al valor original la media de esa variable, y dividir
todo ello por su desviacién tipica, Con ello obtendremos una variable con media 0, y desviacién tipica
igual a 1.
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES
461
Lengua or Fisica inate Filosofta| Historia | Quimica ee
5 5 3 5 5 5 5 5
7 4 3 8 4 1 3 8
5 8 7 6 5 6 1 5
7 2 4 8 7 1 3 6
8 9 10 8 8 7 9 4
4 9 8 4 3 4 7 5
6 4 4 6 5 5 3 7
4 7 8 3 3 2 8 2
5 3 4 5 6 5 5 1
7 4 5 7 8 8 4 6
7 8 8 7 7 “6 7 9
4 3 3 4 3 2 1 4
7 4 4 7 8 7 4 5
3 5 5 2 3 3 5 7
5 6 6 5 5 5 6 6
8 9 9 9 9 9 9 8
8 5 5 8 9 9 7
7 5 4 7 7 8 5 7 |
5 2 2 4 5 5 3 6
5 5 5 4 5 5 5 5
462 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
14.4.2, Analisis mediante ventanas
La opcién se encuentra en el ment estadisticos del submenti Reduccién de datos.
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 463
Aparecen a la izquierda las variables de nuestro fichero, y se nos pide que sefia-
Jemos las variables que deseamos introducir en el andlisis. Estudiemos a continuacién
las distintas opciones.
1° Descriptivos:
Coors?
De las posibilidades que ofrece solicitamos el test KMO y la prueba de esferici-
dad de Bartlett. Tras hacerlo presionamos continuar.
2.° Extracci6n:
En extraccién, se nos pide que determinemos el ntimero de factores que reten-
dremos en el andlisis. Se puede realizar de dos modos: o bien determinandolos a prio-
ri: 1,2,3, etc., 0 bien seleccionando todos los factores que tengan un autovalor s
rior a una determinada cantidad, que el SPSS fija por defecto en 1. Esta es la opcién
que se le solicitard, pidiendo ademds que muestre la solucién de los factores sin rotar.
464 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
4.° Rotacién:
En la opcién rotaci6n obtenemos los diferentes tipos de rotacién que se pueden
efectuar. Con el fin de lograr una mayor interpretabilidad de los factores, elegimos la
rotacién Varimax.
5.° Puntuaciones:
La opcién puntuaciones permite afiadir al fichero las variables factoriales. Asi-
mismo permite ver la matriz de coeficientes de las puntuaciones factoriales.
6° Opciones:
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 465
En opciones se pueden suprimir coeficientes inferiores al indicado, e indicar el
modo en que los valores no existentes deben ser tratados (excluirlos, reemplazarlos
por la media, 6 excluir casos segtin pareja).
Presentamos a continuaci6n la salida del SPSS para el ejemplo propuesto.
KMO y prueba de Bartlett
Medida de adecuacién muestral de Kaiser-Meyer-Olkin 0,659
Prueba de esfericidad de Bartlett Chi-cuadrado aproximado 184,406
al 28
Sig. 0,000
Obtenemos en primer lugar el estadistico correspondiente a Ia prueba de Bartlett
que como se puede ver es significativo (Sig = 0,000). Este resultado nos informa de la
existencia de correlacién suficiente entre las variables de estudio para realizar el ané-
lisis factorial.
Comunalidades
Inicial | Extraccién
cee 1,000 | 0,146
FILOSOFIA 1,000 | 0.841
FISICA 1,000 | 0,959
HISTORIA. 1,000 | 0,930
INGLES 1,000 | 0,920
LENGUA 1,000 | 0,957
MATEMATICAS | 1,000 0,949
QUiMICA 1,000 0,954
‘Método de extraccién: Anilisis de Componentes
principales.
Obtenemos a continuacién las comunalidades iniciales (siempre iguales a 1), y fi-
nales, que expresan el porcentaje de informacion (varianza) que se ha logrado expli-
car de cada una de las variables mediante el andlisis factorial. Como se ve (menos en
el caso de las calificaciones de educacién fisica) son bastante satisfactorias.
DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
466
‘sojediouud sarousuodwo;) ap sispuy :4pTO9eNX9 ap OPIN,
ooo'oor | Trz'0 ZO-HOE6'T 8
6SL'66 | 69¢'0 CO-a6P6'T L
o6e'66 | 590 zo-asec's 9
LEL'86 | POST ozo s
€E7'L6 | OFT w6r'0 v
l les'r6 | O29'TT | O€6'0 €
Ives ogre | 068't owes | oer'ee | sis ores | eevee | SL9'% zt
80°Lr O80'Ly | 99L'E IiL6y | LL'6r | 786°C TiLer | 16h | zee 1
opojnunsn| vzupums | yoo, oprjnunzo| vzununa | prio, |opvjmunsn| vzumuva | pio, | aruauodwo
% PLP % % P1 ap % % 71 AP %
up}oD104 b] ap oppspona jD ug}oobuixa b] ap oppapon9 1D
S2UO12DINIDS SD] ap DUNS
sauojopanips so} ap sowing
sappruut sasoppaomny
ageondxa pejoy ezUELIE A,
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 467
El cuadro de la pagina anterior nos da informacién sobre los factores. El primero
explica un 49,771% del total de la informacién (varianza), el segundo un 33,439%,
y los tres primeros tomados conjuntamente logran explicar un 94,831% de infor-
maci6n. Al haberle solicitado que seleccionase los componentes con un autovalor
mayor que 1 selecciona los dos primeros que consiguen explicar un 83,210% de la
informacién total.
Matriz de componentes*
Componente
1 2
aera 0,329 0,195
FILOSOFIA 0,885 0,242
FISICA 0,459 0,865
HISTORIA 0,902 0,340
INGLES 0,909 0,306
LENGUA 0,925 0317
MATEMATICAS 0,404 0,887
QuiMICA 0,470 0,857
Método de extraccién: Andlisis de Componentes
principales.
* 2 componentes extrafdos.
En este cuadro se recoge la matriz factorial indicdndose la relacién de cada va-
riable con el correspondiente componente. Los elementos de esta matriz. factorial son
las puntuaciones factoriales; la suma de las puntuaciones al cuadrado correspon-
dientes a un componente, es igual al autovalor correspondiente a dicho factor. Por
ejemplo el autovalor correspondiente al primer factor es igual a:
3,982 = (0,329)? + (0,885)? + (0,459)? + (0,902) + (0,909)? + (0,925)? +
+ (0,404)? + (0,470)?
Las puntuaciones factoriales pueden también considerarse como los coeficientes
de correlacién lineal de Pearson del factor y la variable implicados. Asi se puede ver
que el primer factor tiene una alta correlacién con todas las asignaturas de letras (len-
gua, inglés, filosofia e historia), y una baja correlacién con las de ciencias (fisica, ma-
teméticas y quimica).
468 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Matriz de componentes rotados*
‘Componente
7 2
ee 0,380 | -444E-02
FILOSOFIA 0,907 0,138
FISICA 6,842E-02 0.977
| HISTORIA 0,963 | 5,534E-02
INGLES 0,955 | _8,899E-02
LENGUA 0,975_| _8,570E-02
MATEMATICAS | 8,845E-03 0974
QUIMICA 8,164E-02 0,973
Método de extraccién: Anélisis de Componentes principales.
Método de rotacién: Normalizacién Varimax con Kaiser.
* La rotacién ha convergido en 3 iteraciones.
Se obtiene aqui la matriz rotada por el método Varimax, método que nos ayuda a
la interpretacién de los factores obtenidos. Como se observa el primer componente
tiene una elevada carga en todas las asignaturas relacionadas con las letras (lengua,
historia, filosofia e inglés), y el segundo con las de ciencias (matematicas, fisica y
quimica). Este hecho nos permitirfa identificar al primer componente o factor como
asignaturas de letras (letras), y al segundo como asignaturas de ciencias (ciencias).
Matriz de coeficientes para el célculo
de las puntuaciones en las componentes
‘Componente “|
7 2
Pay 0,105 0,033
FILOSOFIA 0,240 0,007
FISICA 0,026 0,342
HISTORIA 0,259 0,024
INGLES 0,255 0,012
LENGUA 0,261 0,014
MATEMATICAS, 0,042 0,344
QUIMICA 0,022 0341
Método de extraccién: Anélisis de Componentes principales
Método de rotacién: Normalizacién Varimax con Kaiser.
Puntuacién de componentes.
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 469
En el tiltimo cuadro solicitado al programa, el usuario obtiene los coeficientes uti-
lizados para obtener las puntuaciones factoriales. Puntuaciones que recogidas en
las nuevas variables: FACI, y FAC2, son generadas de modo automatico por el
SPSS.
er
“171768
~BAIST
La puntuacién factorial se obtiene al multiplicar los coeficientes de la tabla an-
terior por el valor estandarizado de las variables de cada uno de los sujetos de la
muestra. Al hacerlo se obtendr4 una puntuacién factorial individual para cada caso y
en cada uno de los componentes seleccionados (Fac! y Fac2).
14,5. APENDICE MATEMATICO: CALCULO Y ANALISIS
DE LOS FACTORES MEDIANTE UN EJEMPLO
14.5.1. Ejemplo
Se consideran los resultados de un grupo de alumnos en el conjunto de las asig-
naturas de la carrera de Ciencias Econémicas y Empresariales.
Segiin el esquema propuesto por Spearman para el caso de los tests psicol6gicos,
se podrfa suponer que el conjunto de las notas (variables) dependen de un factor ge-
neral de inteligencia que influye en todas las materias, y ademas tres factores comu-
470 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
nes a grupos de materias (capacidad de abstracci6n, memoria y capacidad de andli-
sis), y un factor especifico de cada asignatura (su propia dificultad), incluyendo en
este tiltimo factor elementos claramente aleatorios.
Sin embargo, la influencia del factor de abstraccién, no serd la misma en Mate-
miticas que en Historia, por ello se tendrd que distinguir el peso que cada factor tie-
ne en cada nota (variable).
Asi se tiene un modelo causal: la nota que un individuo tenga en una materia de-
penderd de la cantidad que posea de esos factores multiplicado por los pesos de los
factores en esta materia. El problema es que, para estimar estos pesos, no se dispone
de mediciones de las cantidades que los individuos tienen de estos factores, sino que
estos se transparentan sélo a través de las notas.
Poniendo este modelo causal en forma matemitica se obtiene la siguiente ecua-
cin:
Zy = ayy + iaFj + OF, + aeFa; = ay
siendo
+ Z, nota en la materia i del alumno j después de normalizada (media igual a
cero y variabilidad igual a uno).
+ Fy, Fay Fyp Fyj cantidades que el alumno j tiene de los factores general, de abs-
traccién, de memoria y de andlisis, que como influyen en varias materias se de-
nominan factores comunes.
* diy, dy, dy, dy: Son los pesos de esos factores en la materia i, algunos de los cua
les pueden ser préximos a cero.
+ U; cantidad que el individuo j tiene del factor especifico de la materia i,
d,; peso del factor especifico en esta variable.
Generalizando a n variables (materias) y m factores comunes se obtiene la si-
guiente especificaci6n:
2 = DVauky tau,
i
+ i= 1,2, ... nnumero de asignaturas
+ k=1,2, ... m mimero de factores
‘Suponiendo que los factores estén normalizados (media igual a cero y varianza
igual a uno), y que son independientes unos de otros, es decir, estén incorrelacio-
nados (pues uno 0 varios factores combinacién lineal de los demés no afiaden
mis informacién al conjunto) se puede demostrar que se cumplen las condiciones
siguientes:
ANALISIS FACTORIAL ¥ DE COMPONENTES PRINCIPALES 471
1. a, es el coeficiente de correlacién simple entre la variable i y el factor comin k:
ai
Cay, x ZF
Esta primera conclusi6n es fundamental a la hora de interpretar los resultados del
andlisis factorial, ya que la circunstancia de que todos los coeficientes sean coefi-
cientes de correlacién simple los hace totalmente comparables, pudiendo interpretarse
el factor por lo que tienen en comdn aquellas variables con las que est4 muy rela-
cionado.
Las dos conclusiones siguientes son las que permiten estimar los coeficientes.
2. La varianza de una variable, por ejemplo Ia i (que es igual a la unidad, ya que
la variable est4 normalizada) se descompone de la forma siguiente:
1 =
1=9? = var(Z,) =< LZ5 =Yai+d?
7 =
2
Var(Z,)= E| YiayFy sav.) =
a
7 me
= {S+-5) +(dU,) +24U, Sar]
a
Lai +a?
ot a
El coeficiente de un factor en una variable, al cuadrado, es la parte de la varianza
de esa variable que es explicada por ese factor. Se suele distinguir lo que aportan en
conjunto los factores comunes de lo que aporta el factor especifico. A la primera par-
te se le llama «comunalidad» (a la segunda: d?se la denomina «especificidad») y la
anotaci6n usual es la siguiente:
-d
n=Sa =
es la «comunalidad» de la variable i con m factores comunes.
3. Lacorrelacién entre dos variables, por ejemplo la i y la s es igual a:
1, = co(Z,Z,)=
12525 = Lauda
7 I
4 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Cor(Z,Z,) = (San +dU, \ Ean +dU, J Saja,
ft % ts
El coeficiente de correlaci6n entre cada dos variables depende solamente del efec-
to de los factores comunes, Asi la interpretacién del coeficiente de correlacién es la
siguiente: dos variables tienen un alto coeficiente de correlacién cuando los factores
que tienen una gran influencia en una de ellas influyen también mucho en la otra, y
Jos que no influyen nada en una no lo hacen tampoco en la otra. Por el contrario
cuando los factores que influyen mucho en una no Io hacen en Ia otra, el coeficiente
de correlacién sera pequefio.
Es importante resaltar que en el coeficiente de correlacién no intervienen en ab-
soluto los factores especificos.
Resumiendo las dos tiltimas conclusiones se tiene que los factores comunes de-
terminan fotalmente los coeficientes de correlacién , pero sélo en parte las varianzas
(s6lo las comunalidades). Si se elimina de las varianzas lo que no es comunalidad, es
decir la» especificidad», todo depende de los factores comunes.
Si se utiliza la forma matricial, el modelo factorial seré el siguiente:
Z=AF+D
y su matriz de varianzas y covarianzas:
V=AA'+D?
siendo Z la matriz de variables de orden (p x n), A la matriz de parametros (p x m), F
Ia de factores (m xn), y D® una matriz. diagonal de varianzas d?.
Por tanto si de la matriz de coeficientes de correlacién R:
Lone nn
m1 ts nn
a
R=r,, donde r, es el coeficiente de correlacién de Pearson
=5,18,S,
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 473
eliminamos las especificidades de la diagonal principal, queda una matriz corregida,
que Ilamamos R*, que s6lo incluye la influencia de los factores comunes:
Weotig fig in
A
ee
R :
2
nl 42nd...
Por otra parte, si tenemos en cuenta que a? es lo que aporta el factor k a la varia-
ble i, sumando todas las aportaciones de ese factor para todas las variables (sumando
respecto a i), obtenemos la capacidad explicativa total del factor k del conjunto de las
varianzas de las variables, que como estén tipificadas, serd igual an.
La capacidad explicativa del factor k(V,) serd parte de la varianza total que ex-
plica, y vendra dada por:
wade
El tanto por uno de la varianza total, explicada por el factor k seré V,/n.
El método de factores principales consiste en obtener primero los coeficientes del
primer factor de manera que sea el que mds varianza explique (maximizando V,) con
Ia condicién de que se cumplan los valores de R* de acuerdo con las férmulas de las
conclusiones (2) y (3).
Se elimina lo que explica este primer factor y se obtiene el segundo de manera
que maximice V, con la condicién de que sea independiente del primero y cumpla
con la matriz de residuos (diferencia entre R* y lo que explica el primer factor), y asf
sucesivamente hasta que la matriz de residuos no contenga més que ceros, lo que que-
14 decir que se han explicado completamente las correlaciones y la parte de las va-
rianzas debida a influencias comunes.
Resumiend, lo que se pretende es obtener sucesivamente los factores de mane-
ra que:
— cada uno explique el mé
no han explicado,
— los factores obtenidos sean independientes entre si.
imo de la varianza (informacién) que los anteriores
478 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
14.5.2, Clasificacién de los métodos de resolucion
La técnica matemética de componentes principales es, hoy en dia, el principal
método de obtenci6n de factores, Examinaremos este método (que aplicado al pro-
blema de factores principales se denomina «Andlisis de Componentes») con mayor
detalle en el siguiente capitulo del trabajo. En este apartado presentaremos la clasi-
ficaci6n de los métodos de realizacién del andlisis factorial segiin Harman (1967):
1. Métodos basados en el cdlculo directo de la matriz de correlacién:
a) métodos de estimacién de las comunalidades
— método del factor principal
— método de centroide (aplicado por Spearman)
— método de descomposicién triangular
b) métodos basados en la estimacién del niimero de factores comunes
— método de maxima verosimilitud
-— método de minimos cuadrados
— anélisis factorial por imagen
— anélisis factorial alpha
2. Métodos indirectos basados en la rotacién de las matices:
a) rotaciones ortogonales
— varimax
— quartimax
— equimax
b) rotaciones oblicuas
— obimax
— cuartimin
— oblimin
3. Métodos que intentan identificar los factores comunes antes de la estimacién
de las matrices de pardmetros del modelo, basdndose en las teorias ajenas del méto-
do de resolucién que permiten al investigador imponer una estructura te6rica de
factores, La estimaci6n posterior de matrices trata de confirmar la estructura tedrica
de factores lo que hace que este método se denomine como «Anilisis Factorial de
Confirmacién». Dependiendo de las restricciones impuestas «a priori» sobre los
factores se pude distinguir:
a) métodos de anilisis factorial de confirmacién con soluciones restringidas
'b) métodos de andlisis factorial de confirmacién con soluciones no restringidas.
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 475
145.3. Componentes principales
Se usa este andlisis para simplificar los datos estadisticos.
Supongamos que se dispone de dos variables aleatorias observadas Z, y Z,, las
cuales:
— estén distribuidas normalmente (cuestién no indispensable para el método ma-
tematico de Pearson)
— estén normalizadas (tienen promedio = 0 y la varianza = 1, para simplificar)
Se trata de encontrar nuevas variables Y, y Y,, que sean funci6n lineal de las va-
riables originales observadas, de forma que estén incorrelacionadas y mantengan la
informacién contenida en las variables Z, y Z,.
Si se representan las observaciones en dos ejes correspondientes a las variables Z,
y Z,, se tendré una elipsoide, que en el caso de correlacién nula entre las dos variables
se convertirfa en un circulo, y en el caso de que Z, y Z, estuvieran perfectamente co-
rrelacionadas degenerarfa en una recta que coincidiria con el eje principal de la elip-
soide en el caso de correlaci6n positiva, y con el eje horizontal en caso de correlaci6n
negativa.
Correlacién
negativa
Correlacién
positiva
416 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
La Iinea de correlacién positiva puede expresarse como una combinacién lineal
de las variables Z, y Z,
Y= b,Z, + byZ,
Si la correlaci6n es perfecta, esta recta representa la distribuci6n de Z, y Z, tan co-
rrectamente como las variables originales, si no es perfecta la recta s6lo aproxima la
distribucién de las dos variables, recogiendo parcialmente la variabilidad conjunta de
las variables originales.
El eje de correlacién negativa terminarfa de recoger la informaci6n restante:
Vy = by Z, + bn,
Los dos nuevos ejes presentan la mayor incorrelacién y recogen la totalidad de la
informacién de las variables originales.
De esta forma, estos dos ejes Y, y ¥, corresponderian a los componentes principales.
Supongamos que se trabaja con p variables aleatorias expresadas en desviaciones
ala media:
£3
[ey 2 sa Zp]
Se intenta conseguir p componentes principales que absorban el maximo de varia-
cién de las variables Z, y presenten incorrelacién entre ellos. Asi un componente i serfa:
m= 22h,
teniendo en cuenta que j = 1,2, ..... 2 observaciones de las variables originales
En forma matricial ser (teniendo n observaciones para p variables aleatorias):
Zb,
Donde
Ay 2 2a 25)
42 Im % + Zp
Zz :
‘tn 2am 23q 2pm
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 477
¥y
Ya
Y=
Yi,
%y
a=
b,
La variacién de la variable Y, sera:
var(¥,) = b{2'Zb, =
Entonces el método de componentes principales propone maximizar esta va-
rianza, lo que en el caso de dos variables equivaldrfa a buscar el eje principal de la
elipsoide.
max var(¥,) = bf Sb,
con restricciones de normalizacién en forma matricial:
bb, =1
en forma algebraica:
1 bi
a
Utilizando el multiplicador de Lagrange tendremos:
max V = max var(¥,)__max[b/Sb, - A(b/b, - D))
478 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Fy=288 -2Ab, =0
(S-ANB, =0
Para poder obtener las soluciones no nulas tenemos que exigir la singularidad de:
|s-all=0
Esta ecuacién nos permite encontrar A que sustituida en
(S-ADb, =0
nos daria el valor de b, pudiendo determinar asf el primer componente principal.
Para el segundo componente Y, maximizamos su varianza:
max var(¥,) = max(b; $b,)
con restricciones de normalidad:
bsb, =1
y de ortogonalidad (no correlacién) con el primer componente:
¥,¥, =0_bfz’zb, =0_bf Sb, =0
Pero tenemos que:
Sb, =2b,_bAb, =0
y como A es un escalar distinto de 0 tendremos:
Ab; ,
0
de donde deducimos la segunda restriccién:
bb, =0
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES, 479
Entonces para determinar el segundo componente principal tendremos que ma-
ximizar la funeién:
max V = max var(¥,)_max[b; Sb, — V(b; b, - 1)41(b; b,))
5 (vy=280,-2vb, ub, =0
5b, » — vb, — 1b,
premultiplicando por b; obtenemos:
2b, Sb, —2VB/b, — 1b; b, =0
como ademés:
bb, =0
bib, =1
tendremos:
2b/Sb,—H=0
y como:
Teniendo en cuenta la simetrfa de S y trasponiendo la expresi6n anterior, obte-
nemos:
bi Sb, =b/Sb,
determinando asf que j1 = 0 y resolviendo la condicién de primer orden para el se-
gundo componente principal de forma que:
25d, —2vb, =0
Sh, =vb,
(S—vi)b, =0
480 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
Para poder obtener las soluciones no nulas, como en el caso anterior, tenemos que
exigir la singularidad de:
\s-w|=0
y generalizando, concluimos que todos los componentes se resuelven de igual forma.
14.5.4. Propiedades de los componentes principales
Encontraremos el valor de las variaciones de los componentes principales:
var(¥,) = b/Sb, = bj A, b, = A, bjb, = A,
ademas como:
b/b, =0
bb,
matricialmente
BB=I
YY = B’SB=B’AB=AB’B=A
siendo esta una matriz diagonal con los elementos:
(Ay, Ages ,)
Ademés como maximizamos los componentes se cumple que:
A> d,>..>A,
La variacién total de las Z vendrd reflejada por:
tr(S) = (Z’Z)
de otro lado la variacién total de los componentes ¥:
tr(Z’Z) = LA,
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 481
Podemos entonces representar las proporciones respectivas con que cada com-
ponente principal contribuye a la variacién total de las X mediante:
Los resultados de la ordenacién de los componentes se denominan Resultados de
Clasificacién Ascendente Jerarquica (CAH) en diferencia de Clasificaci6n no Jerar-
quica (Bolas Optimizadas).
14.5.5. Ejemplo de aplicacién de componentes principales
Para dos dimensiones se puede ilustrar el proceso de rotacién de los ejes (mate-
méticamente de diagonalizacién de la matriz de covarianzas como se demuestra en
Jéreskog, 1976) en el siguiente ejemplo.
Partiendo de dos variables normalizadas Z se construye un sistema de ecuaciones
de rotacién:
W,=UZ,+Uy,Zy
W, =UyZ,+UnZ,
Donde [U,, Uy], {U,; Ua] se Haman vectores propios y tienen propiedades de ser
de longitud 1 y ortogonales, es decir ortonormales. Estas propiedades hacen que la
matriz. formada por los vectores propios tiene su transpuesta igual a la inversa, lo que
permite reescribir el sistema de forma que:
Z,=U,.M,+U.W,
Z, = U,,W, +UzW,
Pero como W, , W, no tienen varianza uno, los coeficientes de la matriz de los.
vectores propios no son coeficientes de correlaci6n entre factores y variables. Para
normalizarlos realizamos siguientes transformaciones:
W,
r=
482 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
transformando el sistema de modo que:
Z,= ay F + anh,
Z, = dy F + Onky
Tenemos un sistema de ecuaciones muy similar al que aparecfa en el andlisis fac-
torial, pero qui todos los factores son comunes y hay tantos como variables. La ca-
pacidad explicativa de cada factor seria:
y considerando las transformaciones hechas
Vi =Up A, + Uy = Un + UA, =A,
Vz =UpA, + Und, = Ui +n Aa = Ay
Luego las varianzas de W, y W, (A, y 4,), coinciden con las capacidades expli-
cativas de los factores (F,, F,).
Resumiendo, hemos prescindido de los ejes primitivos (Z,, Z,) y hemos pasado a
unos nuevos ejes (W,, W,) que sefialan las direcciones perpendiculares (los factores)
en las que hay mayor dispersién de los datos.
14.5.6. Ejemplo de extraccién de componentes principales
Para ilustrar a nivel intuitivo el método de componentes principales seguimos un
ejemplo propuesto en Narvaiza (1988). Se propone analizar las siguientes variables de
las 50 provincias espafiolas (de corte transversal para el perfodo de las elecciones de
1982):
— ingresos per c4pita provinciales
— porcentaje de la poblacién activa provincial que se dedica al sector secun-
dario
— proporcién entre rentas salariales y rentas de capital en cada provincia
— proporcién de votos de izquierda entre el total de votos
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES
El an
normalizados:
1,00
_}0,84
© | 0,23
0,13
0,84
1,00
0,54
0,46
483,
is de estos datos da una matriz de varianzas y covarianzas de los valores
0,23
0,54
1,00
0,70
0,13
0,46
0,70
1,00
Aplicamos el método de componentes principales, y conservamos los compo-
nentes que expliquen por lo menos el 25% de la varianza total. En nuestro caso de
cuatro variables necesitamos conservar los 4 mayores que 1, resultando dos solucio-
nes con los dos vectores propios correspondientes:
A, = 2.47455
A, =1,14130
(0,44675
0,57671
‘| 0,50157
0,46502
0,63587
0,34050
7) -0,44896
-0,52741
Esto quiere decir que en la nube de puntos formados por 50 provincias en el es-
pacio de 4 variables hemos encontrado una direccién W, que explica el 61,86% de la
varianza:
so 0,6186
n
Y otra direccin W, perpendicular a la primera que explica el 28,53% de la va-
rianza total:
4 =0,2853
n
484 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
De este modo obtenemos otro sistema de ecuaciones en dos ejes ortogonales en
un espacio de 4 dimensiones (en proyeccién sobre un plano):
Z, = 0,44675 W, +0,63587 W,
Z, = 0,57671 W, +0,3405 W,
Zz,
),50157 W, —0,44896 W,
Z, = 0,46502 W, —0,52741 W,
Tipificamos los factores: la varianza de W, es 4,, entonces dividimos W, por sus
desviaciones tfpicas y multiplicamos los coeficientes por los valores correspondien-
tes:
pa
ie
VA
U;
gate
vA;
obteniendo:
Z, = 0,70276 F, +0,67931 F,
Z, = 0,90720 F, + 0,36376 F,
Z, = 0,78901 F, -0,47963 F,
Z, =0,73151 F, —0,56344 F,
En esta ecuaci6n los coeficientes son coeficientes de correlacién, sus cuadrados
son las cantidades que cada factor aporta a la explicacién de cada variable y si su-
mamos esos cuadrados por filas tendremos las comunalidades:
He = 0,95534
1B = 0,95534
13 = 0,85258
13 = 0,85258
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 485
Hay que decir también que si sumamos los coeficientes al cuadrado por columnas
obtenemos las capacidades explicativas de los factores W, que son los A,
La representacin grafica del sistema aparece en la figura.
Correlacién
negativa,
Correlacién
positiva
Los vectores Z son las proyecciones de as variables sobre el plano determinado
por los factores F y su longitud es la rafz cuadrada de las comunalidades, de manera
que cuanto més se acerque esta longitud a la unidad, mejor explicada estard la varia
ble 0 lo que es lo mismo més proxima estard la variable al plano. El primer factor
marca la direcci6n principal hacia cual se orientan las cuatro variables, mientras el se-
gundo factor separa las variables en dos grupos, lo que corresponde con los signos de
los coeficientes del sistema. Ademis la figura demuestra como se cumple el objetivo
principal de nuestro andlisis tratar de simplificar manteniendo el méximo de infor-
macién (es decir con minimo de dimensiones explicar el méximo de dispersi6n de da-
tos). El plano de dos dimensiones conserva el 90.39% de la informacién previa.
14.5.7. Relacién de anilisis factorial y de componentes principales
Como dice Kendall, «el andlisis de componentes parte de las observaciones y bus-
ca los componentes con la esperanza de poder reducir las dimensiones de la varia-
486, DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
cién, pudiendo, en ciertos casos, dotar de significado fisico a dichas componentes
(..). En el andlisis de factores se trabaja de otra forma. Es decir, se parte de un mo-
delo y queremos ver si este esté de acuerdo con los datos, y si es asi, estimar sus pa-
metros. (...) A menudo son ambos andlisis etapas diferentes del mismo ciclo: del ex-
perimento a la hipétesis y viceversa»’.
Concluyendo se puede decir que el andlisis de 1os componentes, como caso par-
ticular del andlisis de factores, se basa en maximizar la suma de cuadrados de los pe-
sos de un factor individual, y no tiene en cuenta el factor residual.
Relacién entre el método del factor principal y el método del componente principal
Se puede establecer una correspondencia numérica entre el método de compo-
nentes principales y el de andlisis factorial sin término de error, es decir, con tantos
componentes como variables.
Se tienen las mismas variables, y los componentes al igual que los factores son
independientes, aunque los factores estén estandarizados (media nula y varianza
unitaria), mientras que los componentes tienen media nula pero varianza no nula.
La relacién entre ambos seria:
pak
WA
de forma que el factor se igualarfa al componente una vez tipificado.
En forma matricial, esto se podria representar como
ya,”
sustituyendo Y por su valor y A, por A, quedaria la siguiente expresién:
F’=XB
puesto que B es ortogonal y su traspuesta es igual a su inversa, se tendré
X=F'K
siendo:
K=A?B’
que es muy similar al modelo del andlisis factorial.
* KENDALL, M.G. op. cit. pég. 37.
ANALISIS FACTORIAL Y DE COMPONENTES PRINCIPALES 487
Por este motivo el problema del cAlculo de cargas en el andlisis factorial se pue-
de resolver a través de la utilizacién del método de componentes principales, ha-
ciendo:
AB!
siendo:
+ A: la matriz de cargas del andlisis factorial
+ A: la matriz de cargas de los componente
CAPITULO 16
ANALISIS DE CONGLOMERADOS
16.1. INTRODUCCION
Si se tiene un conjunto de individuos puede resultar de gran interés lograr aso-
ciaciones en funcién de las similitudes o diferencias que éstos tienen. El estudio de
las relaciones y cémo se asocian puede servir para realizar innumerables estudios.
El andlisis de conglomerados o andlisis Cluster es el nombre genérico que se da
a.una amplia variedad de técnicas que se pueden utilizar para realizar clasificaciones
de los distintos casos de una muestra. Estas técnicas generan grupos formados por
elementos similares entre sf. Ms especfficamente un método cluster es un procedi-
miento estadistico multivariante que, partiendo de los datos de una muestra de indi-
viduos, reorganiza la muestra formando grupos de individuos relativamente homo-
géneos.
Los cuatro objetivos que principalmente persigue un andlisis cluster son:
+ elaboracién de una tipologia o clasificacién,
+ investigaci6n de esquemas conceptuales titiles para agrupar sujetos,
+ generacién de hipétesis a través de exploraciones de datos y
+ comprobar si las hip6tesis generadas a través de otros procedimientos se cum-
plen en la muestra de datos.
16.2. ETAPAS A SEGUIR EN EL DESARROLLO
DEL ANALISIS CLUSTER
Podemos distinguir cuatro pasos basicos para todos los estudios realizados con
anilisis cluster:
1, Seleccién de la muestra que queremos dividir en grupos. Por ejemplo paises
de la Unién Europea, compradores de un producto, etc.
568 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
2. Seleccién de las variables que se van a utilizar para realizar el andlisis.
3. CAlculo de las similitudes 0 disimilitudes entre los casos 0 sujetos.
4. Validacién de los resultados obtenidos.
16.2.1. Seleccién de individuos y variables
Es el primer paso. Se pueden elegir individuos, asociaciones, empresas 0 paises,
Respecto a la seleccién de las variables que van a ser utilizadas en el andlisis cluster
es uno de los pasos més criticos. Se pueden distinguir los siguientes puntos:
1. Némero de variables: Se puede creer que con ms variables, se va a con-
seguir una mayor homogeneidad dentro de cada grupo. Esto es un error, ya que
podemos estar introduciendo variables que nos estén desvirtuando las semejanzas
entre los sujetos al no estar estas relacionadas con el objetivo de nuestra investiga-
cién.
2. Utilizacién de variables transformadas: La decisién aqui reside en si uti-
lizamos las variables tal cual son obtenidas o si debemos realizar alguna modifica-
cién.
Una posible modificacién en las variables es estandarizarlas, es decir, convertir-
las en variables con media igual a cero y varianza igual a uno. Para hacerlo basta con
restar a la variables la media y dividirlo por la desviacién tipica.
donde:
+ ¥= Media,
= Desviaci6n tipica.
Realizar esta modificaci6n puede reducir las diferencias entre grupos en aquellas
variables que pudieran ser el mejor discriminante para las diferencias entre grupos. La
estandarizaciOn puede suponer una transformacién no equivalente entre las variables
y podria cambiar las relaciones entre ellas. La decisién de estandarizar o no debe ser
por lo tanto una de las primeras a tomar y debe tenerse en cuenta que los resultados
de la investigacién pueden variar en funcidn de que se haya realizado o no dicha es-
tandarizacién.
La estandarizacién es util especialmente en el caso de variables que estan medi-
das en distintas escalas o magnitudes. Por ejemplo, si se quiere estudiar la semejan-
za entre los distintos paises de la UE y se tienen en cuenta variables como el mimero
de televisores por 1.000 habitantes, la renta per cApita, 0 el porcentaje de usuarios de
Intemet son variables que estén medidas en unidades muy distintas la estandarizacion
puede servir para compararlas entre sf.
ANALISIS DE CONGLOMERADOS _ 569
Otro tema que se discute es si se pueden ponderar las variables para dar mas im-
portancia a alguna de ellas.
16.2.2. Medidas de similitud
Para medir la semejanza entre los individuos es necesario emplear distintos ins-
trumentos o medidas. Estas estan claramente relacionadas con el tipo de variable 0 es-
cala en el que estén referidas las variables,
Bésicamente encontramos las siguiente medidas:
+ medidas de distancia o disimilaridad,
+ medidas de proximidad o similaridad.
A) Medidas de distancia
Se laman de distancia 0 de disimilaridad porque cuanto mayor es el valor de la
medida muestra una mayor diferencia entre los individuos.
Los distintos tipos que existen dependen de la escala en la que éstas estén for-
muladas. A continuacién se exponen las mas empleadas en los distintos tipos de es-
calas:
a) Escala de intervalo (Variables cuantitativas): Cuando la variable esté
medida en una escala de intervalo las distancias mas empleadas son las siguientes:
1. Distancia euclidea: Es la raiz cuadrada de la suma de las diferencias al
cuadrado entre los dos elementos en la variable o variables consideradas
D(X,Y)= XG, -¥y
2. Distancia euclidea al cuadrado:
DYX,Y)= Dx, -¥?
3. Distancia métrica de Chebychev :Es la referencia maxima en valores ab-
solutos entre los valores de los elementos
D(X.) = MaxX, -¥|
370 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
EJEMPLO 16.1. Deseamos hallar las semejanzas que desde el punto de vista in-
formitico existen en tres empresas. Las denominaremos A, B, y C. Las variables se-
leccionadas son: el ntimero de ordenadores por cada 10 empleados, el porcentaje de
Estos que tienen acceso a Internet, y por tltimo el ntimero de informaticos por cada
10 empleados.
Empresa | NE deordenaderes | emery |S eoreada
ee a Internet 10 empleados
Empresa 1 10 80 : 05
Empresa 2 7 60 02
Empresa 3 6 50 02
Con arreglo a estos datos la distancia euclidea entre la empresa 1 y Ia 2 seria
igual a:
DIX) = JY, -¥,)? = (0-7) + (80-60)? + (0,5-0,2)* = 20,22
EI SPSS permite obtener todas las distancias. Esta instruccién se encuentra en el
médulo de correlaciones (opcién distancias)
ANALISIS DE CONGLOMERADOS: sm
Tras pulsar la opci6n introducimos las tres variables
Por defecto se calcula la distancia euclidea, Al pulsar en «Medidas» obtenemos
todas las posibilidades citadas anteriormente.
f Distancia euclidea al cuadrado
Chebychev
572 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
Se observa también que el sistema permite también estandarizar las variables y
transformarlas. Al pulsar «continuar» y luego «aceptar» obtenemos la matriz de
distancias entre las tres empresas
Resumen de procesamiento de los casos
Casos
Valid Perdidos Toral
N Porcentaje N Porcentaje N Porcentaje
3 100 0 0 3 100
Matriz de distancias
Casos
1 2 3
1 20.226 30.267
2 20.226 10.050
3 30.267 10.050
Esta es una matriz de disimilaridades
Tras realizar un resumen def ntimero de casos procesados se obtienen todas las
distancias. Como se observa la mayor distancia se da entre la primera y tercera em-
presa. Del mismo modo se calcularfa el resto de estadisticos.
b) Frecuencias: Cuando se utilizan frecuencias agrupadas en tablas los tests
mis usados son los siguientes:
roy y= PRK REQ), w(K BK)
BO Ga) Ba
donde:
+ X,= Frecuencia observada
+ E(X,) = Frecuencia esperada
(KB) (KE)
ao De
ANALISIS DE CONGLOMERADOS: 573
c) Datos binarios: Este es el dltimo caso que se da cuando se usan variables di-
cotémicas. Entre los coeficientes tenemos:
Los coeficientes mas utilizados son los siguientes:
1) Distancia euclidea
D(X, ¥)=Vb+e
2) Distancia euclidea al cuadrado
D(X,Y)=b+e
3) Diferencia de tamafio
oe
T(X,Y)= reed
4) Varianza
Va
5) Lance y Williams
uxyy=—2t!
2at+b+e
EJEMPLO 16.2. Se quiere analizar la similitud entre varios individuos a la hora de
comprar. Para ello se seleccionan tres productos registrandose con un 1 cuando el su-
jeto compra y con un cero cuando no lo hace. Los resultados se presentan en la si-
guiente tabla:
Individuos Producto A Producto B Producto C
Individuo 1 1 1 1
Individuo 2 1 0 1
Individuo 3 i 0 0
Individuo 4 1 1 0
574. DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
Para calcular las medidas debemos convertir esta tabla en tablas de 2 x 2 para
cada par de individuos. Por ejemplo la similitud entre el Individuo 1 y 2 quedaria
configurado por la siguiente tabla. En ella anotamos el nimero de casos en que
coinciden ambos:
INDIVIDUO 2
Compra No compra
Compra 2@) 10)
Inpivipuo 1
No compra 0 0@
Con estos datos la distancia euclidea entre el individuo | y 2 serfa igual a:
D(X,Y)=Vb+ce=yvl+0=1
E] resto de distancias se pueden obtener en el SPSS mediante la opcién de «Dis-
tancias». Tras introducir los datos vamos a la opcién de «correlaciones» dentro del
ment «analizar>:
@® Producto A [proda]
|. @ Producto B [prodb]
ANALISIS DE CONGLOMERADOS
Distancia euclidea
(ieee ee
Distancia euclidea al cuadrado.
Diferencia de tamafio
Diferencia de configuracién
Williams
S15,
Por defecto la medida empleda es la euclidea pero como se observa se puede ele-
gir cualquier otra de las mencionadas. Tras hacerlo pulsamos el bot6n de «continuar»
y posteriormente el de «Aceptar». Al hacerlo obtenemos en forma de matriz el cAl-
culo de distancias de todos los individuos entre si.
Resumen de procesamiento de los casos
ez Casos
Valid Perdidos Toral
N Porcentaje N Porcentaje N Porcentaje
4 100,0 % 0 0% 4 100.0 %
Matriz de distancias
Distancia eucltdea binaria
7 2 3 4
7 1.000 1.414 1.000
2 1.000 1.000 144
3 1414 1.000 1.000
4 1.000 144 1.000
Esta es una matriz de disimilaridades
516 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
B) Medidas de proximidad o similaridad
En este caso la interpretacién es al revés de las medidas de distancia. Es decir, un
mayor valor indica una mayor cercanfa entre las variables. Como en el caso anterior
dependen de la escala en la que estén formuladas las variables:
@) Escala de intervalo
Las més usadas son dos:
1. Coeficiente de correlacién de Pearson: Como se vio en el capitulo de la re-
gresi6n lineal su valor varfa de —1 a 1. La mayor cercanfa en valor absoluto al uno in-
dica una mayor relacién o proximidad entre los individuos.
2. Coseno de vectores; Su formula es la siguiente
DXi
COX, Y= ——
furLr
Usando los datos del ejemplo 1 la proximidad entre la empresal y la 2 seria igual a:
LX 10x7 +8060 + 0,5x0,2 870.1
VLAD? yo? +80? +0,5° (7? +60" +0,2*) 4.870,
COS(X,Y)
El resto de medidas se puede hallar con el SPSS. Se hallan en el mismo lugar que
las «distancias» pero hay que marcar medidas de «similaridad». Como en casos an-
teriores los resultados se muestran en forma de matriz.
ANALISIS DE CONGLOMERADOS S77
Resumen de procesamiento de los casos
Casos
Valid Perdidos Toral
N Porcentaje N Porcentaje N Porcentaje
3 100.0% 0 0% 3 100.0%
Matriz de distancias
Coseno de vectores de valores
1 2 3
1 1.000 1.000
2 1.000 1.000
3 1,000 1.000
Esta es una matriz de disimilaridades
5) Datos binarios
Los més usados son los siguientes:
1. Coeficiente de concordancia simple: Este coeficiente considera como se-
mejanzas entre los dos casos tanto la presencia en ambos de una variable (a) como la
ausencia de ésta en ambos (d)
a+b
P(X, Y)=———_
Coy atbt+c+d
578 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
Va a tomar valores entre cero y uno. Si P(X,Y) vale cero ser porque a y d valen
cero, por Jo que hay una ausencia total de similitud entre los dos casos. Si vale uno
entonces c y b valdrén cero, es decir, ausencia de disimilitud, o lo que es lo mismo,
similitud piena.
2. Coeficiente de Jacard:
a
X,Y)=—2—
TOM ote
Este coeficiente no tiene en cuenta las ocasiones en que en ambos casos no apa-
rece una de las variables (d), no considera esa ausencia en ambos casos como un ma-
yor parecido entre los casos.
Otros coeficientes de asociacién utilizados en menor medida son:
3. Coeficiente de Russell y Rao: Que no tiene en cuenta en el numerador las
ocasiones en que en ambos casos no aparece una de las variables, pero sien el de-
nominador:
RR(X,Y)
ee
4. Coeficiente de Dice: Al igual que el de Jacard, no tiene en cuenta las oca-
siones en que en ambos casos no aparece una de las variables. Ademas, da doble im-
portancia al hecho de que una variable se dé en ambos casos:
D(X,Y 2a
a orto
5. Coeficiente de Rogers-Tanimoto: Que da doble importancia a la no coin-
cidencia, es decir, a que una variable aparezca en un caso pero no en el otro:
a
RT(X,Y) = _——1_—_
atd+26+0)
Con los datos del ejemplo 16.2 se calculan estos estadfsticos. En concreto, el coe-
ficiente de concordancia simple serfa igual a:
a+b 2+0
P(X, ¥)=—4 > __ =
Cg cers goss 0c0
),66
Es decir, existe un grado de similitud bastante elevado.
ANALISIS DE CONGLOMERADOS 579
EI resto de coeficientes se pueden obtener en el SPSS. Veamos cémo:
Introducimos los datos y pulsamos la opcidn de Distancias como se ha hecho an-
teriormente. Tras hacerlo introducimos las tres variables (producto A, producto B y
producto C) cambiamos la opcién de medida a «similaridades» y pulsamos el bot6n
«medidas».
Pens
Sokaly Sneath 2
43] Sokal y Sneath 3
Tras hacerlo obtenemos los resultados de nuevo en forma de matriz:
580 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
Resumen de procesamiento de los casos
Casos
Valid Perdidos Total
N Porcentaje N Porcentaje N Porcentaje
4 100,0 % 0 0% 4 100,0 %
Matriz de distancias
‘Medida de concordancia simple
1 2 3 4
1 0,667 0,333 0,667 |
2 0,667 0,667 0,333
3 0,667 0,333 0,667
4 0,667 0,333 0,667
Esta es una matriz de disimilaridades
Se observa la coincidencia entre lo calculado previamente y el resultado del
SPSS.
16.3. DISTINTOS MODELOS DE ANALISIS CLUSTER
Como se ha dicho al principio el objetivo del Anilisis Cluster 0 de conglomera-
dos es el de agrupar a los individuos por su grado de homogeneidad. Existen distin-
tas clasificaciones de este tipo de modelos. La clasificacién més usada es la de mo-
delos jerarquicos frente a modelos no jerérquicos.
16.3.1, Modelos jerérquicos
En el anélisis cluster jerérquico se parte del ntimero de individuos (pafses, em-
presas etc.) a partir de aquf se van uniendo entre sf en funci6n de la mayor o menor
proximidad de los individuos entre sf formando grupos. Estos a su vez se van uniendo
entre s{ hasta llegar a un tinico grupo. Obviamente las dos decisiones que existen son:
a) La determinacién de la medida de distancia o proximidad a usar: estas medi-
das son las que hemos visto anteriormente. Como se ha dicho anteiormente se
deberd tener en cuenta la medida en que los datos estén referidos.
b) El método que determinard el modo de unién sucesiva de los distintos grupos
entre si. Es decir, el que determinard la distancia existente entre los sucesivos
grupos. Entre ellos encontramos los siguientes:
ANALISIS DE CONGLOMERADOS: 581
. Vinculacién inter-grupos: Segiin ella se define la distancia entre dos
clusters (grupos) como la media de las distancias entre todas las combina-
ciones posibles dos a dos de los elementos de uno y otro grupo. Por ejem-
plo, sien primer lugar se han agrupado los individuos 1 y 2 la distancia en-
tre el grupo (cluster) formado por éstos y el grupo 3 vendria dada por la
media de las distancias 1-3 y 1-2. Usa pues los pares de distancias.
. Vinculacién intra-grupos: combina los grupos (clusters) de manera que la
media de las distancias entre todos los pares de sujetos dentro del resultante
sea la menor posible.
. Vecino mas préximo o distancia minima: los individuos que se combi-
nan en cada grupo son aquellos que tienen una menor distancia 0 mayor si-
militud. Posteriormente se recalcula la distancia del cluster respecto al
resto de casos formandose el siguiente mediante el mismo criterio
. Vecino més lejano o distancia maxima: la distancia se calcula a partir de
la distancia de los dos puntos més alejados.
. Método de Ward: El objetivo de este método es minimizar la varianza in-
tra-grupos. Su funcionamiento es el siguiente:. Se parte de n grupos for-
mados todos ellos por un tinico punto (todos los individuos). En este mo-
mento la suma de las varianzas intra-grupo es cero. A continuacién se
unirén dos grupos (individuos) en uno sélo. Mas concretamente, se uniran
aquellos dos puntos que minimicen el incremento en la suma de las va-
rianzas intra-grupo. El proceso continua del mismo modo sucesivamente.
Veamoslo con un ejemplo: La Unién Europea ha decidido la incorporacién de
nuevos miembros para el afio 2004. En concreto: Letonia, Estonia, Lituania, Polonia,
Repiiblica Checa, Eslovaquia Eslovenia y Hungrfa. Tomando una serie de variables
representativas se pretende agrupar a estos paises:
Coches | Salario | Usuarios
PIBpc | Inflacién | Desempleo| (x 1.000 | medio | internet
habitan.) | por hora | (%)
Letonia 3.300 34 82 235 19 7
Estonia 3.800 44 65 339 3 30
Lituania 3.300 13 12,9 317 23 7
Polonia 4.400 35 18,1 259 3.6 10
Reptblica
Checa 5.400 39 93 362 3,2 14
Eslovaquia 3.900 42 19,7 236 25 2
Hungria 4.900 62 56 235 29 15
FUENTE: Diario «El Mundo» (11-Octubre-2002).
582 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
En primer lugar se introducen los datos en el SPSS. Los pafses deberdn ser in-
troducidos como una variable nueva tipo cadena’.
La opcién para realizar Andlisis de conglomerados se encuentra dentro del menti
clasificar. Escogemos «Conglomerados jerérquicos».
"Es importante sefialar que el procedimiento més habitual en el resto de técnicas es siempre usar va-
riables numéricas a las que asociamos una etiqueta. Este caso se encontraria entre las excepeiones,
ANALISIS DE CONGLOMERADOS: 983
Tras hacerlo se introducen todas las variables, indicando que la variable paises se
usaré para etiquetar los casos.
ee ee rer eT
En el de grficos e] dendograma
Corre ren eres eres rey
584 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
En el apartado referido al método se debe elegir:
a) El tipo de medida, que como sabemos varia segtin la escala de la variable
analizada (pudiendo realizar distintas transformaciones posteriores como es-
tandarizar las variables). En nuestro caso con el fin de usar variables mas ho-
mogéneas optamos por estandarizar las variables.
b) El modo de vinculacién de los grupos.
Por tiltimo la opcién «Guardar» permite determinar un niimero 0 rango de grupos
(clusters) previos y que se nos guarde como una nueva variable el cluster al que per-
teneceria el pais.
‘Tras hacerlo obtenemos los resultados:
ANALISIS DE CONGLOMERADOS 585
Andlisis de conglomerados
Matriz de distancias
Distancia euctidea al cuadrado
ae 1 2 3 4 5. 6. 2.
Letonia | Estonia | Litwania | Polonia | Rep. Checa | Eslovaguia | Hungria
1. Letonia 15260 | 5.62 | 784 | 14720 | 5.790 | 980s
2. Estonia 15.260 18.290 | 23.121 | 15.878 | 18483 | 16.469
3. Lituania 5.162 | 18.290 1754] 12677 | 8.620 | 20.583
4. Polonia reat | 23.121 | 7.754 8.060 192 | 9.809
5. Rep.Cheea | 14.720 | 15878 | 12677 | 8.060 12.823 | 8.805
6. Esiovaquia | 5.790) 18.483] 8.620 | 1.982 | 12.823 10.067
7. Hungria 9.805 | 16.469 | 20583 | 9809 | 880s | 10.067
Esta es una matriz de disimilaridades.
Vinculacin promedio (Inter-grupos)
Historial de conglomeraci6n
Etapa en la que
Conglomerado
fae combina el conglomerado '
oe Coeft- | aparece por primera vez | Proxima
cientes etapa
Conglome- | Congiome- Conglome- | Conglome-
radol | rado2 radol | rado2
1 4 6 1.982 0 0 3
2 1 3 5.162 0 0 3
3 1 4 701 2 1 5
4 5 7 8.805 0 0 5
5 1 5 12318 3 4 6
6 1 2 17917 5 0 0
Encontramos en primer lugar la matriz de distancias. La medida usada es la dis-
tancia euclidea al cuadrado. El procedimiento de clculo es similar al visto anterior-
mente.
El siguiente cuadro muestra como se van uniendo los individuos en este caso los
paises en funcién del criterio escogido (la vinculacién promedio). En primer lugar se
586 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
une el pais 4 (Polonia) con el 6 (Eslovaquia) como se observa son los que tienen me-
nor distancia entre sf (1,982). En segundo lugar se unen el 1 (Polonia) con el 3 (Li-
tuania) a ambos les separa una distancia euclidea al cuadrado igual a 5,162. Las dos
columnas siguientes indican cuando se forma por primera vez un multicluster, es de-
cir, un grupo de més de dos individuos. Esto sucede en el paso 3. En él se unen el
elemento 1 (Letonia) (que ya estaba unido desde el primer paso a Lituania (elemento
3) y el 4 (Polonia) que ya estaba unido al 6 (Eslovaquia). Esta informacién aparece
en las dos titimas columnas indicandose donde se unieron estos elementos por pri-
mera vez (en el paso 2 en el caso de Lituania (elemento 3) y en el I en el caso de Po-
Ionia (elemento 4). Se observa que el coeficiente asociado en este caso no coincide
con la distancia euclidea al cuadrado. Ese valor surge de hacer las medias de las dis-
tancias 1-4 (7,841), 1-6 (5,790), 3-4 (7,754), y 3-6 (8,620) valor que es igual a
7,50.
De este modo y de manera paulatina se van uniendo los distintos grupos y ele-
mentos. Esto es lo que se recoge en el dendograma que aparece a continuacién:
Dendrograma
*** HIERARCHICAL CLUSTER ANALYSIS***
Dendrogram using Average Linkage (Between Groups}
Rescaled Distance Cluster Combine
CASE 0 5 10 15 20 25
Label
Polonia
Eslovaquia
Letonia
Lituania
Rep. Checa
Hungria
Estonia
auras
A través del dendograma y segtin el momento en el que nos situaramos podria-
mos decidir formar distintos grupos segdin el momento en el que nos situaramos.
Como se ha visto anteriormente a través de la opcién «guardar» y tras haber visto el
dendograma se le puede indicar que se guarde en forma de nuevas variables el grupo
al que estaria asociado cada pais. Supongamos que repetimos el ejercicio indicando
que se agrupe a los paises en tres grupos (opcién guardar). Al hacerlo el SPSS guar-
da como nueva variable el grupo al que pertenecerfa el pais. Al hacerlo obtenemos los
siguientes resultados
ANALISIS DE CONGLOMERADOS 587
Analisis de conglomerados jetatquico: Guardar variables nuevas
‘Tras hacerlo solicitamos los resultados del mismo modo que anteriomente hemos
hecho. Al volver a la pantalla de resultados observamos Ja existencia de una nueva va-
riable que de un modo automiitico el SPSS ha denominado «clu3_1» y que recoge el
grupo de pertenencia.
Se puede observar que el grupo 1 quedarfa conformado por Letonia, Lituania, Po-
lonia y Eslovaquia. El grupo 2 por Estonia, y el grupo 3 por la Reptiblica Checa y
Hungria.
Si observamos el dendograma hubiésemos podido deducir lo mismo. Estos tres
grupos estén formados por los elementos de mayor proximidad entre sf.
588 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO.
16.3.2. Modelos no jerarquicos
Tienen por objeto realizar una sola partici6n de los individuos en K grupos, lo que
implica que previamente se debe fijar el ntimero de grupos. Esta es la principal dife-
rencia con los modelos jerérquicos. Uno de éstos modelos es el andlisis cluster de K
medias. El procedimiento a seguir es el siguiente:
Se comienza dividiendo los casos 0 puntos en un nimero prefijado de grupos.
Se calcula el centro (media) de cada uno de esos grupos.
Se reasigna cada punto al grupo de cuyo centro se encuentre mas cercano.
Se vuelven a calcular los centros de cada grupo.
Se vuelven a repetir los pasos 3 y 4 hasta que ningdn punto cambie de grupo.
Yaype
A diferencia de los métodos de aglomeracién jerarquica, que requieren el céleu-
o de una matriz de similitud, los métodos iterativos que usa este andlisis trabaja di-
rectamente sobre la matriz inicial de datos.
El principal problema que presentan estos métodos es que el nimero de grupos
debe ser previamente especificado por el investigador.
Repitamos el ejemplo anterior, En primer lugar, vamos a trabajar con variables es-
tandarizadas con objeto de homogeneizarlas. Para lograr las variables estandarizadas
se debe acudir al menii «estadisticos descriptivos»
ANALISIS DE CONGLOMERADOS: 389
: Al hacerlo, obtenemos la siguiente pantalla que nos permite guardar como nuevas
‘ variables las variables tipificadas (estandarizados). Al volver a la pantalla de datos ob-
servamos las nuevas variables que conservan el nombre de la variable original con
una z delante.
Estas son las variables que usaremos para el andlisis. Acudimos a la opcién
«Analisis de conglomerados de K medias» y en el recuadro introducimos las variables
estandarizadas (tipificadas).
1 @® Inllacion [inflac]
F1@ Desemoleo [desem
4.@ Coches (por 1000 +
590 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
En la opci6n «guardar» le solicitamos que indique el grupo al que pertenece cada
pats.
Tras hacerlo obtenemos los resultados.
Centros iniciales de los conglomerados
Conglomerado
I 2 3
Puntda: PIB per c4pita 1.05672 42985 1.57613
Puntia: Inflacién ~.30347 38179 03916,
Puntia: Desempleo ~.58398 ~.88774 =.38762
Punt ‘oches (por 1000 habitantes) ~.88340 1.01931 1.44011
Punt jalario medio por hora 44941 —.1,92982 -75342
Punt % de usuarios Internet ~.83266 2.08164 .05430
En primer lugar tenemos los centros de los grupos o clusters iniciales. En segundo
lugar el historial de iteraciones.
Historial de iteraciones
Cambio en los centros de los
Mteracién conglomerados
a: = 5
1 1.542 000 1.484
2 000 000 ‘000
© Convergencia alcanzada debido a un cambio en la distancia nulo
© pequefio. La distancia méxima en la que ha cambiado cada
centro es .000. La iteracién actual es 2. La distancia minima en-
tre los centros iniciales es 3.837.
ANALISIS DE CONGLOMERADOS 591
En la siguiente pantalla se obtiene el valor de los centroides finales que servirdn
para asignar los paises a cada grupo.
Centros de los conglomerados finales
Conglomerado
1 2 3
Puntda: PIB per c4pita —52388 — 42985 1.26269
Puntda: Inflacién 50905 38179 82721
Puntiia: Desempleo 58079 —88774 | -71786
Punttia: Coches (por 1000 habitantes) —39400 1.01931 27835
Puntda: Salario medio por hora 17514 | ~1.92982 61463
Puntia: % de usuarios Internet — 57924 2.08164 -11766
Pertenencia a los conglomerados
Paises
Niimero de caso| _candidatos _| Conglomerado Distancia
1 Letonia i 1.542
2 Estonia 2 000
3 Lituania 1 1.750
4 Polonia 1 1.440
5 Rep. Checa 3 1.484
6 Eslovaquia 1 1,333
7 Hungrfa 3 1.484
Por tiltimo obtenemos la asignacién de cada uno de los pajses a los tre:
merados fijados previamente. Se observa que el resultado es similar al del andlisis de
conglomeerados jerérquico®,
Namero de casos en cada conglomerado
Conglomerado 1 4,000
Conglomerado 2 1,000
Conglomerado 3 2.000
Validos 7.000
Perdidos 000
* Incluso teniendo en cuenta que en este caso hemos normalizado las variables.
CAPITULO 17
ANALISIS DE CORRESPONDENCIAS
17.1, INTRODUCCION
El anélisis de cormespondencias permite analizar variables nominales y ordinales
que dan lugar a una tabla de contingencia, Este andlisis permite asf tanto descompo-
ner y observar las relaciones de los niveles de las variables como realizar un estudio
de las mismas caracterfsticas que el andlisis factorial, pero referido a variables me-
didas en una escala ordinal o nominal.
Cuando el andlisis es de dos variables hablamos de andlisis simple de correspon-
dencias. Si es de tres o mas lo denominamos anilisis de correspondencias miiltiple.
En las tablas de contingencia se estudiaba si dos variables medidas en una esca-
la nominal u ordinal tenfan relaci6n entre si. En el andlisis de correspondencias va-
mos a profundizar en la relaci6n que existe entre ellas y los niveles de las mismas.
17.2. FINALIDAD
La finalidad principal de este andlisis es la de determinar la posicién que tienen
Jos distintos niveles de las variables y relacionarlos entre s{ en unas coordenadas a las
que denominamos dimensiones. Estas tienen mucha similaridad con lo que en el ané-
lisis factorial se denominaban factores.
Se puede decir por ello que existen muchos paralelismos con el andlisis factorial.
Lo que allf denominabamos valores propios es lo que el SPSS denomina inercia. La
inercia va a determinar la cantidad de informacién o varianza que conseguimos ex-
plicar de las relaciones existentes entre las variables.
Es importante destacar que lo que el SPSS denomina valores singulares 0 propios
corresponde a la raiz cuadrada de la inercia'.
"En el programa SPAD, la inercia se identifica directamente como valor propio o eigenvalue.
594 DISENO DE ENCUESTAS PARA ESTUDIOS DE MERCADO
La inercia total va a ser igual al valor que en las chi cuadrado de las tablas de
contingencia dividido por el nimero total de individuos. Esta inercia total va a ser
posteriormente repartida entre las distintas dimensiones.
Si el andlisis factorial extrafa factores aqui vamos a hablar de dimensiones. El nti-
mero méximo de éstas serd igual al minimo del numero de filas o del nimero de co-
lumnas menos uno.
Es decir, si estuviésemos estudiando la relaci6n entre cuatro productos (A, B, C,
y D) y el aspecto més apreciado en ellos por una serie de individuos (precio, estética
y utilidad) el ntimero maximo de dimensiones serfa igual a 3-1 = 2, ya que el menor
ntimero de niveles se da en las columnas (3) al restarle uno obtendremos dos.
17.3. EJEMPLO DE APLICACION
Retomando el ejemplo que describfamos en el capitulo de las tablas de contin-
gencia sobre la relacién del nivel de renta con la opini6n que se tenia del sistema sa-
nitario vamos a realizar un andlisis de correspondencias mediante el SPSS.
Nivel de renta Bueno Malo Regular Totat
Bajo 15 40 35 150
Medio 60 50 70 180
Alto 20 40 30 90
Muy alto 15 40 25 80
ToraL, 170 170 160 500
Procedamos a introducir la tabla en el SPSS e indicarle que lo interprete como
tabla de contingencia, Esta opcién s6lo se encuentra disponible en la opci6n relativa
a los comandos. Para hacerlo deberemos en primer lugar introducir las variables
(renta y opinién sobre el sistema sanitario). Estas variables deberén introducirse
como numéricas asociando a una etiqueta a cada niimero por ejemplo en el nivel de
renta (1 = Bajo; 2 = Medio; 3 = Alto; 4 = Muy Alto). En el de opinién sobre el sis-
tema sanitario (1 = Bueno; 2 = Regular; 3 = Malo). Asimismo creamos otra variable
que recogerd el nimero de individuos asociados a cada nivel. A esta variable la he-
mos llamado cantidad.
Vous aimerez peut-être aussi
- Examen Final de Investigación-IIDocument3 pagesExamen Final de Investigación-IIangeldcristoPas encore d'évaluation
- Guía Turnitin DocentesDocument14 pagesGuía Turnitin DocentesangeldcristoPas encore d'évaluation
- Mario TerronesDocument4 pagesMario TerronesangeldcristoPas encore d'évaluation
- Examen Final IndustrialDocument4 pagesExamen Final IndustrialangeldcristoPas encore d'évaluation
- Examen Final EnfermeríaDocument3 pagesExamen Final EnfermeríaangeldcristoPas encore d'évaluation
- Examenparcial2 Industrial Fila ADocument4 pagesExamenparcial2 Industrial Fila AangeldcristoPas encore d'évaluation
- Examen Final - Fila BDocument2 pagesExamen Final - Fila BangeldcristoPas encore d'évaluation
- Práctica Dirigida N°02-IndustrialDocument4 pagesPráctica Dirigida N°02-IndustrialangeldcristoPas encore d'évaluation
- R StudioDocument42 pagesR Studioangeldcristo100% (6)
- Examen Final - Fila ADocument2 pagesExamen Final - Fila AangeldcristoPas encore d'évaluation
- Actividad N°03.1Document8 pagesActividad N°03.1angeldcristoPas encore d'évaluation
- Actividad N°02Document4 pagesActividad N°02angeldcristoPas encore d'évaluation
- Coeficiente de Correlación Por Rangos de SpearmanDocument1 pageCoeficiente de Correlación Por Rangos de SpearmanangeldcristoPas encore d'évaluation
- Examen Final de InvestigaciónDocument2 pagesExamen Final de InvestigaciónangeldcristoPas encore d'évaluation
- Actividad N°01Document2 pagesActividad N°01angeldcristoPas encore d'évaluation
- Los 50 Libros Que Todo Peruano Debe LeerDocument219 pagesLos 50 Libros Que Todo Peruano Debe LeerRolly Baldoceda Vela50% (2)
- Práctica de Hipótesis - Grupo TardeDocument2 pagesPráctica de Hipótesis - Grupo TardeangeldcristoPas encore d'évaluation
- Uso de Redes y Bases de Datos 2Document48 pagesUso de Redes y Bases de Datos 2angeldcristoPas encore d'évaluation
- Introduccion A La Psicometría: TCT e IRT. U Autonoma de Madrid (2006) - Abad Et AlDocument75 pagesIntroduccion A La Psicometría: TCT e IRT. U Autonoma de Madrid (2006) - Abad Et AlPablo Baumer100% (1)
- Ejercicios Resueltos N°01Document5 pagesEjercicios Resueltos N°01angeldcristoPas encore d'évaluation
- Biblioteca Virtual DiaposDocument14 pagesBiblioteca Virtual DiaposangeldcristoPas encore d'évaluation
- Calidad de ServicioDocument17 pagesCalidad de ServicioangeldcristoPas encore d'évaluation
- Sesión N°01 - Introducción e InstalaciónDocument9 pagesSesión N°01 - Introducción e InstalaciónangeldcristoPas encore d'évaluation
- IV Examen BioestadisticaDocument10 pagesIV Examen BioestadisticaangeldcristoPas encore d'évaluation
- Matriz de Validaci N Por Criterio de Experto.Document3 pagesMatriz de Validaci N Por Criterio de Experto.Teofilo TapiaPas encore d'évaluation
- S01-1-COMMA-NEG-2017-1-Números RealesDocument27 pagesS01-1-COMMA-NEG-2017-1-Números RealesangeldcristoPas encore d'évaluation
- S02 1 COMMA NEG 2016 1 Números RealesDocument22 pagesS02 1 COMMA NEG 2016 1 Números RealesEdinson ReynaPas encore d'évaluation
- Proceso de Estandarizaci N de Una PruebaDocument14 pagesProceso de Estandarizaci N de Una PruebaangeldcristoPas encore d'évaluation
- Escala Alfa de CronbachDocument12 pagesEscala Alfa de CronbachJhon Ruiz Vare100% (1)