Vous aimerez peut-être aussi
- How to a Developers Guide to 4k: Developer edition, #3D'EverandHow to a Developers Guide to 4k: Developer edition, #3Pas encore d'évaluation
- Https Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Natural Language ProcessingDocument5 pagesHttps Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Natural Language ProcessinggprasadatvuPas encore d'évaluation
- Python Crash Course by Ehmatthes 17Document1 pagePython Crash Course by Ehmatthes 17alfonsofdezPas encore d'évaluation
- Python Lab ALL 10 PrgmsDocument16 pagesPython Lab ALL 10 PrgmsdvyvmsfcdwzbxpmymtPas encore d'évaluation
- Sahil Malhotra 16 BCE 0113 Web Mining L51+L52: 1. Universal Crawling 1.1. CODEDocument11 pagesSahil Malhotra 16 BCE 0113 Web Mining L51+L52: 1. Universal Crawling 1.1. CODEsahilPas encore d'évaluation
- Library Management System ProjectDocument27 pagesLibrary Management System ProjectNiketan Bhatt0% (1)
- Assistant Code BackupDocument10 pagesAssistant Code BackupPranav KPas encore d'évaluation
- 03.python & Computer VisionDocument17 pages03.python & Computer Visionrino tri a.pPas encore d'évaluation
- 25 Awesome Python ScriptsDocument26 pages25 Awesome Python Scriptsmoises tintePas encore d'évaluation
- 01 Python 02 Data SourcingDocument9 pages01 Python 02 Data SourcingAyoubENSATPas encore d'évaluation
- Ads Final Assignment No 11Document18 pagesAds Final Assignment No 11ertPas encore d'évaluation
- CodeDocument13 pagesCodeBryan BagleyPas encore d'évaluation
- Twittermining: 1 Twitter Text Mining - Required LibrariesDocument4 pagesTwittermining: 1 Twitter Text Mining - Required LibrariesSamuel PeoplesPas encore d'évaluation
- Cs Aditya WorkDocument31 pagesCs Aditya WorkNonu RajputPas encore d'évaluation
- Python .13 18Document15 pagesPython .13 18makanijenshi2409Pas encore d'évaluation
- Introduction To Using Apis With Python: Nalette BrodnaxDocument42 pagesIntroduction To Using Apis With Python: Nalette BrodnaxOla APas encore d'évaluation
- Python 13-18Document9 pagesPython 13-18makanijenshi2409Pas encore d'évaluation
- Python ImpDocument29 pagesPython ImpRuturaj DhotrePas encore d'évaluation
- Scalable Data Processing in RDocument8 pagesScalable Data Processing in ROctavio FloresPas encore d'évaluation
- 1 Password 2 JohnDocument6 pages1 Password 2 Johnubaid chohanPas encore d'évaluation
- Basic Performance Optimization in Django by Ryley Sill MediumDocument30 pagesBasic Performance Optimization in Django by Ryley Sill MediumMario Colosso V.Pas encore d'évaluation
- CS ProjectDocument13 pagesCS ProjectKevin ShalomPas encore d'évaluation
- Xii Cs Practical RecordDocument20 pagesXii Cs Practical RecordOm TankPas encore d'évaluation
- MongoDB Berlin Schema DesignDocument61 pagesMongoDB Berlin Schema DesignAlvin John RichardsPas encore d'évaluation
- PythonDocument31 pagesPythonRimjhim KymariPas encore d'évaluation
- Bookstore AbDocument54 pagesBookstore AbAryan BakshiPas encore d'évaluation
- Binary File HandlingDocument8 pagesBinary File Handlingakshar.sharma94Pas encore d'évaluation
- Accessing Internet DataDocument3 pagesAccessing Internet DataJean-Claude Bruce LeePas encore d'évaluation
- Point Query & Tiles Over Kerla: Manish Modani: Ts Timeslice Fts Forecasted Time SliceDocument8 pagesPoint Query & Tiles Over Kerla: Manish Modani: Ts Timeslice Fts Forecasted Time Sliceuser0xPas encore d'évaluation
- Real EstateDocument10 pagesReal EstateMuskaanPas encore d'évaluation
- 10-Visualization of Streaming Data and Class R Code-10!03!2023Document19 pages10-Visualization of Streaming Data and Class R Code-10!03!2023G Krishna VamsiPas encore d'évaluation
- Computer Science-CLASS-12-RECORD PROGRAMSDocument10 pagesComputer Science-CLASS-12-RECORD PROGRAMSnitheeshchowdary2007Pas encore d'évaluation
- Python 2 Lab EsyDocument34 pagesPython 2 Lab EsySharukh HussainPas encore d'évaluation
- 6-10 Python Lab ProgramDocument16 pages6-10 Python Lab Programabcd12341109Pas encore d'évaluation
- LibraryMgmt XII IP ProjectReportFinalDocument19 pagesLibraryMgmt XII IP ProjectReportFinalushavalsaPas encore d'évaluation
- MongoBoulder - Schema DesignDocument59 pagesMongoBoulder - Schema DesignAlvin John RichardsPas encore d'évaluation
- Kendriya Vidyalaya Uttarkashi: Computer Project Report Topic:-Library Management SystemDocument15 pagesKendriya Vidyalaya Uttarkashi: Computer Project Report Topic:-Library Management SystemAjay ChauhanPas encore d'évaluation
- Binary FileDocument8 pagesBinary FileV.R. MuruganPas encore d'évaluation
- Library Management System ProjectDocument19 pagesLibrary Management System ProjectNiketan Bhatt100% (1)
- YouTube DownLoaderDocument20 pagesYouTube DownLoaderMackos-GnuPas encore d'évaluation
- 2013 - Notes - R Trinker'S - NotesDocument274 pages2013 - Notes - R Trinker'S - NotesCody WrightPas encore d'évaluation
- 6 - Text Vectorization-CSC688-SP22Document5 pages6 - Text Vectorization-CSC688-SP22Crypto GeniusPas encore d'évaluation
- Functions in PythonDocument19 pagesFunctions in Pythonsonali karkiPas encore d'évaluation
- Time Series BasicsDocument21 pagesTime Series BasicsChopra Shubham100% (1)
- 12 Experiment Info and Project InfoDocument12 pages12 Experiment Info and Project Infoaditisingh71810Pas encore d'évaluation
- Hands On Artificial Intelligence For IoT Prefinal1 PDFDocument48 pagesHands On Artificial Intelligence For IoT Prefinal1 PDFaaaaPas encore d'évaluation
- Association R: AppendixDocument5 pagesAssociation R: AppendixElPas encore d'évaluation
- Write A Python Code To Print The Sum of Natural Numbers Using Recursive FunctionsDocument21 pagesWrite A Python Code To Print The Sum of Natural Numbers Using Recursive FunctionsRAHUL UPADHYAYPas encore d'évaluation
- Weather ForecastingDocument5 pagesWeather Forecastingahmed salemPas encore d'évaluation
- Apostila de Formulas, Funções e Macros PDFDocument227 pagesApostila de Formulas, Funções e Macros PDFeduardomarceloPas encore d'évaluation
- Financial Analytics With PythonDocument40 pagesFinancial Analytics With PythonHarshit Singh100% (1)
- DLP, PyDocument4 pagesDLP, PyZurich MateoPas encore d'évaluation
- Test SqsDocument8 pagesTest Sqssamir silwalPas encore d'évaluation
- WSMA Lab Manual 2Document8 pagesWSMA Lab Manual 2Ashish KurapathiPas encore d'évaluation
- File Handling Full NotesDocument15 pagesFile Handling Full Notespantheanandal23Pas encore d'évaluation
- Python PartBDocument29 pagesPython PartBJai MalharPas encore d'évaluation
- Alm Co-2 PDFDocument11 pagesAlm Co-2 PDFThota DeepPas encore d'évaluation
- Aryan Cs ProjectDocument28 pagesAryan Cs Projectaryan12gautam12Pas encore d'évaluation
- Hall Ticket Cum Test Fee Receipt: Important InstructionsDocument1 pageHall Ticket Cum Test Fee Receipt: Important InstructionsgprasadatvuPas encore d'évaluation
- Human Resource Planning IGNOU All in OneDocument202 pagesHuman Resource Planning IGNOU All in OnegprasadatvuPas encore d'évaluation
- Cheat Sheets of Python Libraries TensorflowDocument3 pagesCheat Sheets of Python Libraries TensorflowgprasadatvuPas encore d'évaluation
- RPubs - Text-Mining With Rvest and QdapDocument17 pagesRPubs - Text-Mining With Rvest and QdapgprasadatvuPas encore d'évaluation
- Regex - Extract Pattern From String, Strip Text, Convert To Numeric and Sum in R DataDocument2 pagesRegex - Extract Pattern From String, Strip Text, Convert To Numeric and Sum in R DatagprasadatvuPas encore d'évaluation
- Https Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Working With DataDocument7 pagesHttps Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Working With DatagprasadatvuPas encore d'évaluation
- List of Machine Learning Certifications and Best Data Science BootcampsDocument23 pagesList of Machine Learning Certifications and Best Data Science BootcampsgprasadatvuPas encore d'évaluation
- MSC in Applied Data Science & Big Data - Data ScienceTech InstituteDocument8 pagesMSC in Applied Data Science & Big Data - Data ScienceTech InstitutegprasadatvuPas encore d'évaluation
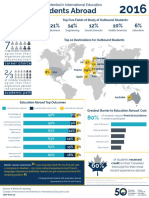
- Infographic Study Abroad enDocument1 pageInfographic Study Abroad engprasadatvuPas encore d'évaluation
- Course Outline: SC EnceDocument1 pageCourse Outline: SC EncegprasadatvuPas encore d'évaluation
- E19t5w 19 LCD MonitorDocument56 pagesE19t5w 19 LCD MonitorJames BrianPas encore d'évaluation
- Paul LaughlinDocument5 pagesPaul LaughlinSiddharth TiwariPas encore d'évaluation
- DB2 9 PureXML Guide For BeginnersDocument410 pagesDB2 9 PureXML Guide For BeginnersPratik JoshtePas encore d'évaluation
- 990dsl Manu Copper Loop TesterDocument218 pages990dsl Manu Copper Loop TesteruvsubhadraPas encore d'évaluation
- Convolution of Probability Distributions PDFDocument3 pagesConvolution of Probability Distributions PDFJosé María Medina VillaverdePas encore d'évaluation
- CodeCompass - An Open Software Comprehension Framework For Industrial UsageDocument9 pagesCodeCompass - An Open Software Comprehension Framework For Industrial UsageJexiaPas encore d'évaluation
- HP LaserJet P SeriesDocument31 pagesHP LaserJet P SeriesPopescu Viorel-MihaiPas encore d'évaluation
- Manual IQ Plus 355Document54 pagesManual IQ Plus 355willycifuentesPas encore d'évaluation
- Logic Circuit & Switching Theory Midterm Quiz 2Document10 pagesLogic Circuit & Switching Theory Midterm Quiz 2Russel Mendoza100% (1)
- 8 Solving Linear Equations BLM Answer KeysDocument3 pages8 Solving Linear Equations BLM Answer Keysapi-349184429Pas encore d'évaluation
- Reprojecting A Shapefile Using QGISDocument5 pagesReprojecting A Shapefile Using QGISPhat NguyenPas encore d'évaluation
- Top Ten Problems in Siebel Projects and How To Avoid ThemDocument4 pagesTop Ten Problems in Siebel Projects and How To Avoid Themapi-19477595Pas encore d'évaluation
- Daily Time Record Daily Time RecordDocument2 pagesDaily Time Record Daily Time RecordJasmine Rose Cole CamosPas encore d'évaluation
- Audit in Computerized EnvironmentDocument2 pagesAudit in Computerized Environmentrajahmati_280% (1)
- Tugas Setelah Tutorial Operational Research Ii: Jurusan Teknik IndustriDocument2 pagesTugas Setelah Tutorial Operational Research Ii: Jurusan Teknik IndustriRosiana RahmaPas encore d'évaluation
- HiPath ProCenter V7-0 Call DirectorDocument24 pagesHiPath ProCenter V7-0 Call Directorapi-3852468Pas encore d'évaluation
- HSDP Tutorial 1 Prototyping Analytic SolutionDocument7 pagesHSDP Tutorial 1 Prototyping Analytic SolutionDinesh ZinoPas encore d'évaluation
- Pre-Requisite Form SSPC Protective Coatings Inspector (PCI) Program & Certification - Level 3Document6 pagesPre-Requisite Form SSPC Protective Coatings Inspector (PCI) Program & Certification - Level 3Prakash RajPas encore d'évaluation
- Best Practice in Project, Programme & Portfolio Management - MoP, MoV, P3ODocument2 pagesBest Practice in Project, Programme & Portfolio Management - MoP, MoV, P3Ospm9062Pas encore d'évaluation
- Dollar GeneralDocument3 pagesDollar GeneralLaurenLechner2750% (2)
- Resume of Mominul IslamDocument2 pagesResume of Mominul IslamMomin_khan1981Pas encore d'évaluation
- Vacon NXP Advanced Safety Options Quick Guide DPD01919A UKDocument18 pagesVacon NXP Advanced Safety Options Quick Guide DPD01919A UKeduardoluque69Pas encore d'évaluation
- Construction DrawingsDocument17 pagesConstruction Drawingsjacksondcpl50% (2)
- Software Architecture Two Mark With Answer 2013 RegulationDocument20 pagesSoftware Architecture Two Mark With Answer 2013 RegulationPRIYA RAJI100% (5)
- STL PDFDocument22 pagesSTL PDFUtkarsh GuptaPas encore d'évaluation
- S4hana-Launch Mena Aborchert - FinalDocument48 pagesS4hana-Launch Mena Aborchert - FinalpilloleonPas encore d'évaluation
- Simplified DESDocument12 pagesSimplified DESSameh Elnemais100% (1)
- How To Run Sap Code Inspector To Do Static Abap Performance CheckDocument20 pagesHow To Run Sap Code Inspector To Do Static Abap Performance CheckHuseyn IsmayilovPas encore d'évaluation
- Confluence 4.3 User GuideDocument727 pagesConfluence 4.3 User GuideArpith NayakPas encore d'évaluation
- Skill 6Document8 pagesSkill 6Anggraini VionitaPas encore d'évaluation