Vous aimerez peut-être aussi
- ECE 565a: Information Theory Instructor: Prof. Salman AvestimehrDocument49 pagesECE 565a: Information Theory Instructor: Prof. Salman AvestimehrAthira NathPas encore d'évaluation
- EE-317: Information Theory: Fall 2008Document38 pagesEE-317: Information Theory: Fall 2008logu_thalirPas encore d'évaluation
- Information CodingDocument9 pagesInformation CodingExtc EngPas encore d'évaluation
- Data CommunicationsDocument94 pagesData Communicationsmyatheinkhant119Pas encore d'évaluation
- Computer Science E-1 Spring 2010 Scribe Notes Lecture 1: January 25, 2010 Andrew SellergrenDocument7 pagesComputer Science E-1 Spring 2010 Scribe Notes Lecture 1: January 25, 2010 Andrew SellergrenGaurav SinghPas encore d'évaluation
- Lec3 Source Coding Annotated Day4Document75 pagesLec3 Source Coding Annotated Day4Paras VekariyaPas encore d'évaluation
- Introduction To Information Theory: Hsiao-Feng Francis Lu Dept. of Comm Eng. National Chung-Cheng UnivDocument45 pagesIntroduction To Information Theory: Hsiao-Feng Francis Lu Dept. of Comm Eng. National Chung-Cheng UnivdonweenaPas encore d'évaluation
- Introduction To ITCDocument39 pagesIntroduction To ITCAshok kumarPas encore d'évaluation
- Lecture 5Document29 pagesLecture 5Ale MorenoPas encore d'évaluation
- Lecture 1Document35 pagesLecture 1anushkaPas encore d'évaluation
- Quantum ComputersDocument86 pagesQuantum ComputerspeeyushPas encore d'évaluation
- Data TransmissionDocument23 pagesData TransmissiontierSargePas encore d'évaluation
- Error Detection and Correction: Parity Check Code Bounds Based On Hamming DistanceDocument10 pagesError Detection and Correction: Parity Check Code Bounds Based On Hamming Distancecodename1011Pas encore d'évaluation
- PhysicalDocument10 pagesPhysicalSureshkumar AlagarsamyPas encore d'évaluation
- P2week1 Digital ModulationDocument49 pagesP2week1 Digital ModulationAbdulrahman AlsomaliPas encore d'évaluation
- سلايد ٢Document10 pagesسلايد ٢العامري العدنانيPas encore d'évaluation
- Ankon Gopal Banik: According To The Syllabus of Department of CSE, Gono BishwabidiyalayDocument36 pagesAnkon Gopal Banik: According To The Syllabus of Department of CSE, Gono BishwabidiyalayAnkon Gopal BanikPas encore d'évaluation
- Reliability and Channel CodingDocument38 pagesReliability and Channel CodingTuyên Đặng LêPas encore d'évaluation
- Inter Symbol InterferenceDocument29 pagesInter Symbol Interferencepriya123_kolusuPas encore d'évaluation
- Decoy State Quantum Key Distribution (QKD) : Hoi-Kwong LoDocument44 pagesDecoy State Quantum Key Distribution (QKD) : Hoi-Kwong Loamitom_pandey4974Pas encore d'évaluation
- Chapter 1Document75 pagesChapter 1Funda KayatürkPas encore d'évaluation
- 02 QKD - Qcrypto Activity StudentDocument18 pages02 QKD - Qcrypto Activity Studentsai420Pas encore d'évaluation
- Sampling PDFDocument27 pagesSampling PDFArifandhi Nur MPas encore d'évaluation
- Error Detection and CorrectionDocument37 pagesError Detection and CorrectionMikiyas AbebePas encore d'évaluation
- The Internet, Wires, Cables and WifiDocument4 pagesThe Internet, Wires, Cables and WifiSidiPas encore d'évaluation
- Note3 PDFDocument16 pagesNote3 PDFSimon SiuPas encore d'évaluation
- Introduction To Error CorrectionDocument38 pagesIntroduction To Error CorrectionYaseen MoPas encore d'évaluation
- Error Detection and CorrectionDocument27 pagesError Detection and CorrectioniolePas encore d'évaluation
- Midterm I Review - FinalDocument25 pagesMidterm I Review - FinalFarah TarekPas encore d'évaluation
- Crocotta Research & Development LTD: "Be Ambitious of Climbing Up To The Difficult, in A Manner Inaccessible... "Document24 pagesCrocotta Research & Development LTD: "Be Ambitious of Climbing Up To The Difficult, in A Manner Inaccessible... "Robert SugarPas encore d'évaluation
- ReportsssssDocument24 pagesReportsssssNikky Mari100% (1)
- Computer Fundamentals: Lecture 2 Reading: Positive Integers and BasesDocument2 pagesComputer Fundamentals: Lecture 2 Reading: Positive Integers and BasesMa LouPas encore d'évaluation
- 5-Data Representation - Part 2Document26 pages5-Data Representation - Part 2mariainspanishclassPas encore d'évaluation
- Quantum Cryptography: Presented By: Sarika.K II Sem M.Tech, DECDocument32 pagesQuantum Cryptography: Presented By: Sarika.K II Sem M.Tech, DECDivil JainPas encore d'évaluation
- Chapter 5 Artificial Neural NetworksDocument50 pagesChapter 5 Artificial Neural NetworksKenneth Kibet NgenoPas encore d'évaluation
- Recon2015 07 Travis Goodspeed Sergey Bratus Polyglots and Chimeras in Digital Radio ModesDocument65 pagesRecon2015 07 Travis Goodspeed Sergey Bratus Polyglots and Chimeras in Digital Radio Modesjames wrightPas encore d'évaluation
- Uncg Csc100 f17 Lectl Limitsandfuture 3upDocument7 pagesUncg Csc100 f17 Lectl Limitsandfuture 3upSenthil VelanPas encore d'évaluation
- Introduction To Convolutional Neural NetworksDocument41 pagesIntroduction To Convolutional Neural NetworksRashiPas encore d'évaluation
- Sic Hotnets TalkDocument41 pagesSic Hotnets Talknirajmodi20985Pas encore d'évaluation
- CH 1Document33 pagesCH 1Hamze Ordawi1084Pas encore d'évaluation
- 02 Qcrypto Activity AnswersDocument20 pages02 Qcrypto Activity AnswersTty SmithPas encore d'évaluation
- Mining Data StreamsDocument67 pagesMining Data StreamsushaPas encore d'évaluation
- Basic Terminologies: From CriptwikiDocument23 pagesBasic Terminologies: From Criptwikimyra_on_youPas encore d'évaluation
- Praktikum - DACOM 03Document3 pagesPraktikum - DACOM 03Risna Elisa SihalohoPas encore d'évaluation
- Institut Teknologi Del: TeoriDocument3 pagesInstitut Teknologi Del: TeoriRisna Elisa SihalohoPas encore d'évaluation
- Praktikum - DACOM 03Document3 pagesPraktikum - DACOM 03Eva LelitaPas encore d'évaluation
- Praktikum - DACOM 03Document3 pagesPraktikum - DACOM 03Risna Elisa SihalohoPas encore d'évaluation
- Praktikum - DACOM 03Document3 pagesPraktikum - DACOM 03Risna Elisa SihalohoPas encore d'évaluation
- Lec 9Document25 pagesLec 9shubhamPas encore d'évaluation
- Modern World KCLDocument33 pagesModern World KCLDen NisPas encore d'évaluation
- CSEP 590 Data Compression: Course Policies Introduction To Data Compression Entropy Variable Length CodesDocument93 pagesCSEP 590 Data Compression: Course Policies Introduction To Data Compression Entropy Variable Length CodesRohan BorgalliPas encore d'évaluation
- CHAPTER 01 - Basics of Coding TheoryDocument36 pagesCHAPTER 01 - Basics of Coding TheorySundui BatbayarPas encore d'évaluation
- Binary Numbers and Gates: External Representation Is The Way We, As Humans, Generally RepresentDocument14 pagesBinary Numbers and Gates: External Representation Is The Way We, As Humans, Generally Representkristi5683Pas encore d'évaluation
- Lecture 7Document60 pagesLecture 7Akash 21MAE0001Pas encore d'évaluation
- Uninformed-Search Fall 2015Document34 pagesUninformed-Search Fall 2015ghulamishaqPas encore d'évaluation
- Asynchronous Data Transfer: Serial Transmission ModesDocument9 pagesAsynchronous Data Transfer: Serial Transmission ModesAslam PervaizPas encore d'évaluation
- Lecture 1 - Data Communications - Basic Concepts, Terminology and Theoretical FoundationsDocument62 pagesLecture 1 - Data Communications - Basic Concepts, Terminology and Theoretical Foundations김건정Pas encore d'évaluation
- Lec 10Document27 pagesLec 10shubhamPas encore d'évaluation
- Elizabeth Skousen Supplemental 2: The Imperial Courier NetworkD'EverandElizabeth Skousen Supplemental 2: The Imperial Courier NetworkPas encore d'évaluation
- Chapter 1 Power Electronic Systems: by John Wiley & Sons, Inc. Chapter 1 Introduction 1-1Document12 pagesChapter 1 Power Electronic Systems: by John Wiley & Sons, Inc. Chapter 1 Introduction 1-1eserimPas encore d'évaluation
- Value Added Services Provided by Telecom Service Providers Name: Aditya PandeyDocument2 pagesValue Added Services Provided by Telecom Service Providers Name: Aditya Pandeybits_who_am_iPas encore d'évaluation
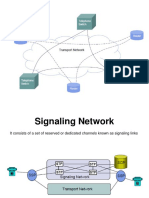
- Transport Networks Signaling ISDNDocument27 pagesTransport Networks Signaling ISDNbits_who_am_iPas encore d'évaluation
- Basic Electrical ConceptsDocument25 pagesBasic Electrical ConceptsAhdab ElmorshedyPas encore d'évaluation
- Department of Chemistry, BITS-Pilani, K K Birla Goa Campus, Goa 403 726, IndiaDocument1 pageDepartment of Chemistry, BITS-Pilani, K K Birla Goa Campus, Goa 403 726, Indiabits_who_am_iPas encore d'évaluation
- Inverter - Lecture 5 PDFDocument8 pagesInverter - Lecture 5 PDFbits_who_am_iPas encore d'évaluation
- Synchronous MultiplexingDocument18 pagesSynchronous Multiplexingbits_who_am_iPas encore d'évaluation
- QuestionsDocument9 pagesQuestionsbits_who_am_iPas encore d'évaluation
- QuestionsDocument9 pagesQuestionsbits_who_am_iPas encore d'évaluation
- Transport Networks Signaling ISDNDocument27 pagesTransport Networks Signaling ISDNbits_who_am_iPas encore d'évaluation
- Traffic (Compatibility Mode)Document78 pagesTraffic (Compatibility Mode)bits_who_am_iPas encore d'évaluation
- Ch5 Angle ModulationDocument67 pagesCh5 Angle ModulationSrikarPolasanapalliPas encore d'évaluation
- PSPICE Evaluation 2Document1 pagePSPICE Evaluation 2bits_who_am_iPas encore d'évaluation
- SUNSETv2.0 GuidelinesDocument118 pagesSUNSETv2.0 Guidelinesbits_who_am_iPas encore d'évaluation
- Quiz WilpDocument4 pagesQuiz Wilpbits_who_am_iPas encore d'évaluation
- HandoutDocument3 pagesHandoutbits_who_am_iPas encore d'évaluation
- Joint Admission Control, Mode Selection and Power Allocation in D2D Communication SystemsDocument12 pagesJoint Admission Control, Mode Selection and Power Allocation in D2D Communication SystemsMuhammad AzamPas encore d'évaluation
- Matlab Session 1Document2 pagesMatlab Session 1bits_who_am_iPas encore d'évaluation
- Value Added Services Provided by Telecom Service Providers Name: Aditya PandeyDocument2 pagesValue Added Services Provided by Telecom Service Providers Name: Aditya Pandeybits_who_am_iPas encore d'évaluation
- Device ScalingDocument19 pagesDevice Scalingbits_who_am_iPas encore d'évaluation
- Big-M Two Phase MethodsDocument51 pagesBig-M Two Phase Methodsbits_who_am_iPas encore d'évaluation
- Non Linear Programming ProblemsDocument66 pagesNon Linear Programming Problemsbits_who_am_iPas encore d'évaluation
- How Fluorite A and B Type Unit Cells Can Be Related?: Fig. Source: WWW - Metafysica.nlDocument1 pageHow Fluorite A and B Type Unit Cells Can Be Related?: Fig. Source: WWW - Metafysica.nlbits_who_am_iPas encore d'évaluation
- Handout MATH F212Document2 pagesHandout MATH F212bits_who_am_iPas encore d'évaluation
- Handout of EEE F 313 (Analog Digital VLSI Design)Document3 pagesHandout of EEE F 313 (Analog Digital VLSI Design)bits_who_am_iPas encore d'évaluation
- Nanochem Handout 2015Document2 pagesNanochem Handout 2015bits_who_am_i100% (1)
- Dept of Electrical, Electronics & Instrumentation Engineering KK Birla Goa CampusDocument36 pagesDept of Electrical, Electronics & Instrumentation Engineering KK Birla Goa Campusbits_who_am_iPas encore d'évaluation
- DSP 1Document21 pagesDSP 1bits_who_am_iPas encore d'évaluation
- Avigilon - Product Brochure - enDocument36 pagesAvigilon - Product Brochure - enPedro JesusPas encore d'évaluation
- Cloud Data Security: University College of Engineering, RTU, Kota (Rajasthan)Document26 pagesCloud Data Security: University College of Engineering, RTU, Kota (Rajasthan)arpita patidarPas encore d'évaluation
- H.261 VideoDocument12 pagesH.261 VideoVenkat ReddyPas encore d'évaluation
- Q3 Empowerment Technologies Final RevalDocument40 pagesQ3 Empowerment Technologies Final RevalKimberly Raymundo100% (1)
- Thomson Vibe Cp6000 EnglDocument2 pagesThomson Vibe Cp6000 Englmouhamadou moustapha gayePas encore d'évaluation
- Summer ReportDocument20 pagesSummer Reportdolar singhPas encore d'évaluation
- Analysis of Various Image Processing TechniquesDocument4 pagesAnalysis of Various Image Processing TechniquesJeremiah SabastinePas encore d'évaluation
- Manual 831 952 959Document776 pagesManual 831 952 959carlos56dbPas encore d'évaluation
- EC8002 Multimedia Compression and Communication Notes 1Document52 pagesEC8002 Multimedia Compression and Communication Notes 1Anbazhagan SelvanathanPas encore d'évaluation
- CG Unit-4 NotesDocument19 pagesCG Unit-4 Notessathyaaaaa1Pas encore d'évaluation
- Digital AudioDocument9 pagesDigital AudioNiki WandanaPas encore d'évaluation
- The Discrete Cosine TransformDocument15 pagesThe Discrete Cosine TransformShilpaMohananPas encore d'évaluation
- Atc20 VisheratinDocument14 pagesAtc20 VisheratinazizPas encore d'évaluation
- Ece-V-Information Theory & Coding (10ec55) - NotesDocument217 pagesEce-V-Information Theory & Coding (10ec55) - NotesRaghu N GowdaPas encore d'évaluation
- Hadoop Map Reduce Performance Evaluation and Improvement Using Compression Algorithms On Single ClusterDocument12 pagesHadoop Map Reduce Performance Evaluation and Improvement Using Compression Algorithms On Single ClusterEditor IJRITCCPas encore d'évaluation
- Dynamic Data Technologies Patent SuitDocument68 pagesDynamic Data Technologies Patent SuitMikey CampbellPas encore d'évaluation
- CIP3 PluginDocument18 pagesCIP3 PluginNVK CTPPas encore d'évaluation
- Interview QuestionsDocument26 pagesInterview Questionsapi-3757838Pas encore d'évaluation
- NTA UGC NET Computer Science SyllabusDocument9 pagesNTA UGC NET Computer Science SyllabusBet workPas encore d'évaluation
- American CinematographerDocument96 pagesAmerican CinematographerNoir NiorPas encore d'évaluation
- BulSU3 Est PartDocument61 pagesBulSU3 Est PartMark Anthony RagayPas encore d'évaluation
- BW Calculator r4Document23 pagesBW Calculator r4skanshahPas encore d'évaluation
- DH-NVR2116HS-4KS2 Datasheet 20171212 PDFDocument3 pagesDH-NVR2116HS-4KS2 Datasheet 20171212 PDFRen RenPas encore d'évaluation
- Hfe0609 LiuDocument16 pagesHfe0609 LiuAnonymous BkmsKXzwyKPas encore d'évaluation
- Bebras Solutions Guide 2021 R1 SecondaryDocument89 pagesBebras Solutions Guide 2021 R1 Secondaryaditya.padi4Pas encore d'évaluation
- T2-iDDR - Sales Manual v1.4Document13 pagesT2-iDDR - Sales Manual v1.4mkPas encore d'évaluation
- Eplan ManualDocument27 pagesEplan ManualChu Văn AnPas encore d'évaluation
- An Improved Stacked Auto Encoder Based Data Compression Technique For WSNsDocument11 pagesAn Improved Stacked Auto Encoder Based Data Compression Technique For WSNsIJRASETPublicationsPas encore d'évaluation
- 4CP0 01 Que 20210429Document28 pages4CP0 01 Que 20210429linluci224Pas encore d'évaluation
- UNIT-III Data Warehouse and Minig Notes MDUDocument42 pagesUNIT-III Data Warehouse and Minig Notes MDUneha srivastavaPas encore d'évaluation