Vous aimerez peut-être aussi
- Journal of Homeland Security and Emergency Management: A Social Vulnerability Index For Disaster ManagementDocument24 pagesJournal of Homeland Security and Emergency Management: A Social Vulnerability Index For Disaster ManagementDeden IstiawanPas encore d'évaluation
- CSPR Briefing: Ssessment of Ocial UlnerabilityDocument20 pagesCSPR Briefing: Ssessment of Ocial UlnerabilityDeden IstiawanPas encore d'évaluation
- Optimasi Support Vector Machine (SVM) Untuk Memprediksi Adanya Mutasi Pada DNA Hepatitis C Virus (HCV)Document8 pagesOptimasi Support Vector Machine (SVM) Untuk Memprediksi Adanya Mutasi Pada DNA Hepatitis C Virus (HCV)Deden IstiawanPas encore d'évaluation
- Optimasi Support Vector Machine (SVM) Untuk Memprediksi Adanya Mutasi Pada DNA Hepatitis C Virus (HCV)Document8 pagesOptimasi Support Vector Machine (SVM) Untuk Memprediksi Adanya Mutasi Pada DNA Hepatitis C Virus (HCV)Deden IstiawanPas encore d'évaluation
- The K-Modes Algorithm With Entropy Based Similarity CoefficientDocument6 pagesThe K-Modes Algorithm With Entropy Based Similarity CoefficientDeden IstiawanPas encore d'évaluation
- Short Introduction To Epidata ManagerDocument7 pagesShort Introduction To Epidata ManagerNelson JimenezPas encore d'évaluation
- Cluster ExampleDocument8 pagesCluster ExampleDeden IstiawanPas encore d'évaluation
- Real Statistics Resource Pack License AgreementDocument2 pagesReal Statistics Resource Pack License AgreementDeden IstiawanPas encore d'évaluation
- Forecast 2Document25 pagesForecast 2Deden IstiawanPas encore d'évaluation
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (120)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Solving Recurrence RelationsDocument10 pagesSolving Recurrence Relationscompiler&automataPas encore d'évaluation
- Digital Processing of Speech Signals (Rabiner & Schafer 1978) PDFDocument265 pagesDigital Processing of Speech Signals (Rabiner & Schafer 1978) PDFVaishnavi Subramanian100% (2)
- Question Bank - 1Document1 pageQuestion Bank - 1Sudhanwa KulkarniPas encore d'évaluation
- Data Structure AssignmentDocument12 pagesData Structure AssignmentAhmad SultanPas encore d'évaluation
- An Intelligent Knowledge Extraction Framework For Recognizing Identification Information From Real-World ID Card ImagesDocument10 pagesAn Intelligent Knowledge Extraction Framework For Recognizing Identification Information From Real-World ID Card ImagesJamesLimPas encore d'évaluation
- Binary Coded Decimal Codes (BCD Codes)Document8 pagesBinary Coded Decimal Codes (BCD Codes)Luka Lorenzo100% (1)
- cs301 Final Term PapersDocument9 pagescs301 Final Term PapersJibran HayatPas encore d'évaluation
- Probset 1Document2 pagesProbset 1soham1994Pas encore d'évaluation
- MM BSC Solns 2009Document14 pagesMM BSC Solns 2009Asheke ZinabPas encore d'évaluation
- 15CS73 Dec18-Jan19 PDFDocument2 pages15CS73 Dec18-Jan19 PDFPradyumna A KubearPas encore d'évaluation
- Determining Optimum Coefficients of IIR Digital Filter Using Analog To Digital MappingDocument5 pagesDetermining Optimum Coefficients of IIR Digital Filter Using Analog To Digital MappingDora TengPas encore d'évaluation
- Data Structures and Algorithms Made Easy With Java Learn Data Structure Using Java in 7 DaysDocument364 pagesData Structures and Algorithms Made Easy With Java Learn Data Structure Using Java in 7 DaysA A M Nazibul HaquePas encore d'évaluation
- Computers & Industrial Engineering: SciencedirectDocument16 pagesComputers & Industrial Engineering: SciencedirectitzgayaPas encore d'évaluation
- CD Unit2 New1Document93 pagesCD Unit2 New1gnana jothiPas encore d'évaluation
- Mining Association Rules in Large DatabasesDocument40 pagesMining Association Rules in Large Databasessigma70egPas encore d'évaluation
- Question Paper... Computer Oriented Numerical TechniquesDocument41 pagesQuestion Paper... Computer Oriented Numerical TechniquesLbb SrrPas encore d'évaluation
- Diagnostics 12 02472 v2Document15 pagesDiagnostics 12 02472 v2seyfu mogesPas encore d'évaluation
- A Novel Binary Division Algorithm Based On Vedic Mathematics and Applications To Polynomial DivisionDocument6 pagesA Novel Binary Division Algorithm Based On Vedic Mathematics and Applications To Polynomial DivisionDebopam DattaPas encore d'évaluation
- TuningBill AssignmentDocument5 pagesTuningBill AssignmentKaushal KumarPas encore d'évaluation
- ESD-Ch3 2018 P6 PDFDocument27 pagesESD-Ch3 2018 P6 PDFngoc an nguyenPas encore d'évaluation
- PSD 3Document34 pagesPSD 3Reza AdityaPas encore d'évaluation
- Paper of Linear ProgrammingDocument10 pagesPaper of Linear ProgrammingkhalishahPas encore d'évaluation
- Data Structures Viva QuestionsDocument8 pagesData Structures Viva QuestionslokiblazerPas encore d'évaluation
- Digital Image Processing QB 2017 - 18Document9 pagesDigital Image Processing QB 2017 - 18PrakherGuptaPas encore d'évaluation
- Laboratory Exercise 5: Digital Processing of Continuous-Time SignalsDocument24 pagesLaboratory Exercise 5: Digital Processing of Continuous-Time SignalsPabloMuñozAlbitesPas encore d'évaluation
- OCDM2223 Tutorial7solvedDocument5 pagesOCDM2223 Tutorial7solvedqq727783Pas encore d'évaluation
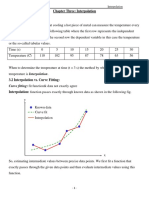
- Chapter Three: Interpolation: Curve Fitting: Fit Function& Data Not Exactly AgreeDocument21 pagesChapter Three: Interpolation: Curve Fitting: Fit Function& Data Not Exactly AgreeMohsan HasanPas encore d'évaluation
- This Study Resource Was: Quiz 3Document5 pagesThis Study Resource Was: Quiz 3Nagarajan Thandayutham100% (1)
- Divide-and-Conquer Technique:: Maximum Subarray ProblemDocument16 pagesDivide-and-Conquer Technique:: Maximum Subarray ProblemFaria Farhad MimPas encore d'évaluation
- Math373CO2016 2017Document2 pagesMath373CO2016 2017Asad AbubakerPas encore d'évaluation