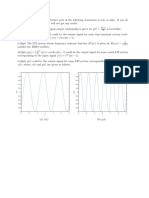
Vous aimerez peut-être aussi
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Dual Channel FFT Analysis - Part1Document60 pagesDual Channel FFT Analysis - Part1Won-young SeoPas encore d'évaluation
- Digital Signal Processing Lab ManualDocument58 pagesDigital Signal Processing Lab ManualKarthick Subramaniam100% (1)
- Principles - of .Quantum - Artificial.Intelligence PDFDocument277 pagesPrinciples - of .Quantum - Artificial.Intelligence PDFPrashant Gupta100% (4)
- dSPACE CLP1104 Manual 201663013420Document172 pagesdSPACE CLP1104 Manual 201663013420meghraj01Pas encore d'évaluation
- Exact Ray Tracing in MATLABDocument9 pagesExact Ray Tracing in MATLABslysoft.20009951Pas encore d'évaluation
- Exact Ray Tracing in MATLABDocument9 pagesExact Ray Tracing in MATLABslysoft.20009951Pas encore d'évaluation
- EE-232 Lab Manual Signals and SystemsDocument57 pagesEE-232 Lab Manual Signals and SystemsMuhammad YousafPas encore d'évaluation
- Atex Eng PDFDocument1 pageAtex Eng PDFEPas encore d'évaluation
- Fourier Transform and SeriesDocument2 pagesFourier Transform and SeriesAbhidudePas encore d'évaluation
- Calculating Variance and Standard DeviationDocument16 pagesCalculating Variance and Standard DeviationAi Jeni (AI)Pas encore d'évaluation
- SA Solutions Autumn 2016Document8 pagesSA Solutions Autumn 2016Miguel RosalesPas encore d'évaluation
- Lab.8. DFT and FFT TransformsDocument16 pagesLab.8. DFT and FFT TransformsTsega TeklewoldPas encore d'évaluation
- University of Palestine Gaza Strip Civil Engineering College Numerical Analysis CIVL 3309 Dr. Suhail LubbadDocument17 pagesUniversity of Palestine Gaza Strip Civil Engineering College Numerical Analysis CIVL 3309 Dr. Suhail LubbadHazem AlmasryPas encore d'évaluation
- 3.08 Binomial Distribution - Examples Moments PDFDocument4 pages3.08 Binomial Distribution - Examples Moments PDFDeepak ChaudharyPas encore d'évaluation
- Fundamentals of Communication Systems Solution Manual Chapter 2 HighlightsDocument966 pagesFundamentals of Communication Systems Solution Manual Chapter 2 HighlightsbrooksPas encore d'évaluation
- Sampling and Reconstruction: Hanhdn@hcmut - Edu.vnDocument48 pagesSampling and Reconstruction: Hanhdn@hcmut - Edu.vnThành Vinh PhạmPas encore d'évaluation
- 300 Continuous Time Markov ChainsDocument78 pages300 Continuous Time Markov ChainsAli SarfrazPas encore d'évaluation
- Qdoc - Tips Ece633f09hw2solutionsDocument13 pagesQdoc - Tips Ece633f09hw2solutionsTrần Trọng TiếnPas encore d'évaluation
- Trigonometric Fourier Series: ECE 350 - Linear Systems I MATLAB Tutorial #6Document7 pagesTrigonometric Fourier Series: ECE 350 - Linear Systems I MATLAB Tutorial #6CatPas encore d'évaluation
- The FFT Via Matrix Factorizations: A Key To Designing High Performance ImplementationsDocument42 pagesThe FFT Via Matrix Factorizations: A Key To Designing High Performance Implementationsdangtung.dttPas encore d'évaluation
- University of Ottawa Midterm Signals and SystemsDocument7 pagesUniversity of Ottawa Midterm Signals and SystemsYaseenPas encore d'évaluation
- What Is Dispersion?: Mixing On Several Length ScalesDocument14 pagesWhat Is Dispersion?: Mixing On Several Length ScalesRahul MorePas encore d'évaluation
- Gamma FunctionDocument14 pagesGamma FunctionmohammedalielkhamissiPas encore d'évaluation
- SMA 2271 - Lec 7b PDFDocument9 pagesSMA 2271 - Lec 7b PDFStanley MwangiPas encore d'évaluation
- Chapter Four: Curve FittingDocument58 pagesChapter Four: Curve FittingGirmole WorkuPas encore d'évaluation
- MuPAD Graphics M. Majewski 2004 - TabsDocument81 pagesMuPAD Graphics M. Majewski 2004 - TabsJanusz SiodaPas encore d'évaluation
- Understanding Variance and Standard Deviation of Ungrouped DataDocument5 pagesUnderstanding Variance and Standard Deviation of Ungrouped DataDINA CANDELARIAPas encore d'évaluation
- Pages by Bose-DigitalDocument15 pagesPages by Bose-DigitalJenny VarelaPas encore d'évaluation
- Week5Document30 pagesWeek5zyy.krys0123Pas encore d'évaluation
- DSP Exp 7Document9 pagesDSP Exp 7eishasingh369Pas encore d'évaluation
- MTE-03 Dec 2007Document12 pagesMTE-03 Dec 2007cooooool1927Pas encore d'évaluation
- Week 4-6 Convolution CorrelationDocument64 pagesWeek 4-6 Convolution CorrelationSOHAG ALAMPas encore d'évaluation
- Notes No. 3 Solvinmg For Mean Variance Standard DeviationDocument7 pagesNotes No. 3 Solvinmg For Mean Variance Standard Deviationnikkigabanto.24Pas encore d'évaluation
- QuestionsDocument4 pagesQuestionsYoussef Abdel-Rahman Mohamed ZakiPas encore d'évaluation
- Lect 7Document16 pagesLect 7Ashan ShamikaPas encore d'évaluation
- DSP-Lec 4Document32 pagesDSP-Lec 4Ahmed FarhoudPas encore d'évaluation
- Solucionario Examen Final de Algebra Lineal II-2011Document7 pagesSolucionario Examen Final de Algebra Lineal II-2011Walter VelásquezPas encore d'évaluation
- Chapter 0 Solutions Manual Chaparro PDFDocument31 pagesChapter 0 Solutions Manual Chaparro PDFderghalPas encore d'évaluation
- Tarea 1 Unidad 3: Instituto Tecnológico de TijuanaDocument5 pagesTarea 1 Unidad 3: Instituto Tecnológico de TijuanayeseniaPas encore d'évaluation
- System Reliability EvaluationDocument47 pagesSystem Reliability EvaluationOgik Parmana100% (1)
- انظمة واشاراتDocument4 pagesانظمة واشاراتhamzeh basemPas encore d'évaluation
- Introducción A Las Telecomunicaciones: Unmsm - Fiee E.P. Ingenieria de TelecomunicacionesDocument23 pagesIntroducción A Las Telecomunicaciones: Unmsm - Fiee E.P. Ingenieria de TelecomunicacionesThony HAPas encore d'évaluation
- Laplace Transforms: Ajith S KurupDocument16 pagesLaplace Transforms: Ajith S KuruprashidtajarPas encore d'évaluation
- MathDocument18 pagesMathdasawPas encore d'évaluation
- EE 473 HW 3 (Fall 2019) frequency sampling filter designDocument2 pagesEE 473 HW 3 (Fall 2019) frequency sampling filter designHakan UlucanPas encore d'évaluation
- The Fourier Transform PDFDocument10 pagesThe Fourier Transform PDFVincent KiptanuiPas encore d'évaluation
- Chapter 8 Discrete-Time Signals and Systems 8-1 IntroductionDocument43 pagesChapter 8 Discrete-Time Signals and Systems 8-1 IntroductionAnonymous WkbmWCa8MPas encore d'évaluation
- 2018midterm1 SolutionDocument7 pages2018midterm1 Solution김명주Pas encore d'évaluation
- Fourier Representation of Signals: Tutorial ProblemsDocument62 pagesFourier Representation of Signals: Tutorial ProblemsMarcel HuberPas encore d'évaluation
- Unit Iii Laplace TransformDocument86 pagesUnit Iii Laplace TransformArihant DebnathPas encore d'évaluation
- Basis Functions (3 Lectures) : Concept of Basis Functions. Fourier Transform and Its PropertiesDocument16 pagesBasis Functions (3 Lectures) : Concept of Basis Functions. Fourier Transform and Its PropertiesSatya NarayanaPas encore d'évaluation
- Fluid FlowDocument30 pagesFluid FlowudayakumarPas encore d'évaluation
- Fourier Series Representation of Periodic FunctionsDocument27 pagesFourier Series Representation of Periodic FunctionsnokuphilaPas encore d'évaluation
- Sample RegressionDocument4 pagesSample RegressionMiko ArniñoPas encore d'évaluation
- Dwnload Full Fundamentals of Communication Systems 2nd Edition Proakis Solutions Manual PDFDocument36 pagesDwnload Full Fundamentals of Communication Systems 2nd Edition Proakis Solutions Manual PDFbecurl.poitrel56ls100% (9)
- DTFT From FTDocument4 pagesDTFT From FTGodwinPas encore d'évaluation
- 2250 Matrix ExponentialDocument7 pages2250 Matrix Exponentialkanet17Pas encore d'évaluation
- Demand Estimation and ForecastingDocument64 pagesDemand Estimation and ForecastingPrashant GuptaPas encore d'évaluation
- Ariysha SHAHEEN - Inverse FunctionsDocument8 pagesAriysha SHAHEEN - Inverse FunctionsAriysha SHAHEENPas encore d'évaluation
- Guia 9 Transf LaplaceDocument2 pagesGuia 9 Transf LaplaceLucas Campos MontesPas encore d'évaluation
- Solving Systems of Linear EquationsDocument5 pagesSolving Systems of Linear EquationsmahiruserPas encore d'évaluation
- Full Download Fundamentals of Communication Systems 2nd Edition Proakis Solutions ManualDocument36 pagesFull Download Fundamentals of Communication Systems 2nd Edition Proakis Solutions Manualgiaourgaolbi23a100% (37)
- EECE 2602 Week 5 Fourier Series Part 2Document7 pagesEECE 2602 Week 5 Fourier Series Part 2siarwafaPas encore d'évaluation
- Elementary SignalsDocument17 pagesElementary SignalsTuan LePas encore d'évaluation
- The Spectral Theory of Toeplitz Operators. (AM-99), Volume 99D'EverandThe Spectral Theory of Toeplitz Operators. (AM-99), Volume 99Pas encore d'évaluation
- Transmutation and Operator Differential EquationsD'EverandTransmutation and Operator Differential EquationsPas encore d'évaluation
- A Simple Approach To Induction Machine Parameter Estimation: IMECS Maria - INCZE Ioan IovDocument8 pagesA Simple Approach To Induction Machine Parameter Estimation: IMECS Maria - INCZE Ioan IovOlimpiu StoicutaPas encore d'évaluation
- Specification Guide: Electric MotorsDocument68 pagesSpecification Guide: Electric Motorskiki270977Pas encore d'évaluation
- Recursive LMS Method Identifies DC Motor Parameters OnlineDocument12 pagesRecursive LMS Method Identifies DC Motor Parameters OnlineOlimpiu StoicutaPas encore d'évaluation
- Infineon IGBT ModulesDocument16 pagesInfineon IGBT Modulesqlx4Pas encore d'évaluation
- DusaA Etall2015rcuaplicatiiinstatisticaDocument253 pagesDusaA Etall2015rcuaplicatiiinstatisticaAdriana PadurePas encore d'évaluation
- Isolated Current and Voltage Transducers Characteristics - 1Document48 pagesIsolated Current and Voltage Transducers Characteristics - 1akhilPas encore d'évaluation
- Igbt - Note - e MITSUBISHI PDFDocument76 pagesIgbt - Note - e MITSUBISHI PDFDoDuyBacPas encore d'évaluation
- Air Ultrasonic Ceramic Transducer Specs & PerformanceDocument49 pagesAir Ultrasonic Ceramic Transducer Specs & PerformanceOlimpiu StoicutaPas encore d'évaluation
- Curent 1Document3 pagesCurent 1Olimpiu StoicutaPas encore d'évaluation
- Current Meas in Driving CKT PDFDocument123 pagesCurrent Meas in Driving CKT PDF雪乃 奈々加Pas encore d'évaluation
- Voltage Source Inverter Drive: Ece 504 - Experiment 2Document17 pagesVoltage Source Inverter Drive: Ece 504 - Experiment 2Olimpiu StoicutaPas encore d'évaluation
- Current Transducer LTSR 25-NP I 25 atDocument3 pagesCurrent Transducer LTSR 25-NP I 25 atOlimpiu StoicutaPas encore d'évaluation
- Current Transducer CKSR Series DatasheetDocument18 pagesCurrent Transducer CKSR Series DatasheetOlimpiu StoicutaPas encore d'évaluation
- dSPACE Tutorial PDFDocument22 pagesdSPACE Tutorial PDFHichem HamdiPas encore d'évaluation
- Underground Mine Communications Infrastructure III GMG UM v01 r01Document54 pagesUnderground Mine Communications Infrastructure III GMG UM v01 r01Olimpiu StoicutaPas encore d'évaluation
- ECE 170 Lab #1 Basic MeasurementsDocument13 pagesECE 170 Lab #1 Basic MeasurementsOlimpiu StoicutaPas encore d'évaluation
- Required HW 9 Field Orientation in Induction MachinesDocument2 pagesRequired HW 9 Field Orientation in Induction MachinesOlimpiu StoicutaPas encore d'évaluation
- Ind Mach Dyn ResponseDocument58 pagesInd Mach Dyn ResponseOlimpiu StoicutaPas encore d'évaluation
- ALTAIR 5X W PID Instruction Manual - EN PDFDocument91 pagesALTAIR 5X W PID Instruction Manual - EN PDFSalvatore DuartePas encore d'évaluation
- Rima 08Document4 pagesRima 08Olimpiu StoicutaPas encore d'évaluation
- ALTAIR-5X-PID - Wireless Solution Bulletin - GBDocument4 pagesALTAIR-5X-PID - Wireless Solution Bulletin - GBOlimpiu StoicutaPas encore d'évaluation
- WS-E10 / WSD-E11: Intrinsically Safe Wireless AnemometerDocument4 pagesWS-E10 / WSD-E11: Intrinsically Safe Wireless AnemometerOlimpiu StoicutaPas encore d'évaluation
- Microtector III G888: 4-7-Gas Detection Device With Optional Wireless ModuleDocument8 pagesMicrotector III G888: 4-7-Gas Detection Device With Optional Wireless ModuleOlimpiu StoicutaPas encore d'évaluation
- 0800-71-MC XCell Sensors - ENDocument12 pages0800-71-MC XCell Sensors - ENafdan sanjayaPas encore d'évaluation
- Tutorial 1 Report: Digital Signal Processing LabDocument13 pagesTutorial 1 Report: Digital Signal Processing LabTuấnMinhNguyễnPas encore d'évaluation
- Channel Estimation For Intelligent Reflecting Surface Assisted Multiuser Communications Framework Algorithms and AnalysisDocument14 pagesChannel Estimation For Intelligent Reflecting Surface Assisted Multiuser Communications Framework Algorithms and AnalysisPillala MuraliPas encore d'évaluation
- DFS DTFT DFTDocument37 pagesDFS DTFT DFTravigwlPas encore d'évaluation
- Data Compression Using Adaptive Coding and Partial String MatchingDocument7 pagesData Compression Using Adaptive Coding and Partial String MatchingSagteSaidPas encore d'évaluation
- FUNDAMENTALS OF DIGITAL SIGNAL PROCESSINGDocument4 pagesFUNDAMENTALS OF DIGITAL SIGNAL PROCESSINGanita_anu12Pas encore d'évaluation
- DFT Using Vedic Math KulkarniDocument19 pagesDFT Using Vedic Math KulkarniSwanand RaikarPas encore d'évaluation
- SyllabusDocument107 pagesSyllabusKonda SumanayanaPas encore d'évaluation
- Matlab QuestionsDocument9 pagesMatlab QuestionsNimal_V_Anil_2526100% (2)
- Oscillation Detection in Process Industries by A Machine Learning-Based ApproachDocument13 pagesOscillation Detection in Process Industries by A Machine Learning-Based ApproachNukman TsaqibPas encore d'évaluation
- EC8553 DTSP Notes PDFDocument95 pagesEC8553 DTSP Notes PDFsakthirsivarajan100% (4)
- EECE 301 Signals & Systems Prof. Mark Fowler: Note Set #18Document10 pagesEECE 301 Signals & Systems Prof. Mark Fowler: Note Set #18ahmdPas encore d'évaluation
- FPGA Implementation of FFT for Embedded SystemsDocument16 pagesFPGA Implementation of FFT for Embedded SystemsgalaxystarPas encore d'évaluation
- Exp 7Document3 pagesExp 7Simi JainPas encore d'évaluation
- 5G Network Using Li-FiDocument33 pages5G Network Using Li-Fibyama jessyPas encore d'évaluation
- Lec 958975Document19 pagesLec 958975Rajasekar PichaimuthuPas encore d'évaluation
- Efficient FFT Algorithm and Programming TricksDocument5 pagesEfficient FFT Algorithm and Programming TricksChoirul ImamPas encore d'évaluation
- Digital Signal Processing Laboratory (Sub., Code: 06ECL57)Document48 pagesDigital Signal Processing Laboratory (Sub., Code: 06ECL57)msbhimaPas encore d'évaluation
- Properties of the DFT and circular convolutionDocument5 pagesProperties of the DFT and circular convolutionIstiaque AhmedPas encore d'évaluation
- VHDL code for 8 point FFT algorithmDocument5 pagesVHDL code for 8 point FFT algorithmGaurav BansalPas encore d'évaluation
- Engineering Applications of Artificial Intelligence: Tak-Chung FuDocument18 pagesEngineering Applications of Artificial Intelligence: Tak-Chung FuTori RodriguezPas encore d'évaluation
- NANDHA ENGINEERING COLLEGE ECE DSP QUESTION BANKDocument8 pagesNANDHA ENGINEERING COLLEGE ECE DSP QUESTION BANKNithya VijayaPas encore d'évaluation
- Dip Notes 17ec72 Lecture Notes 1 5Document204 pagesDip Notes 17ec72 Lecture Notes 1 5Aamish PriyamPas encore d'évaluation
- Dsplabmanual-By 22Document64 pagesDsplabmanual-By 22debasnan singh100% (1)
- Exam 2018 DSP ReleaseDocument17 pagesExam 2018 DSP Releasesupun wanasundaraPas encore d'évaluation
- EC8553-DISCRETE TIME SIGNAL PROCESSING-1996352284-Unit 1-NotesDocument38 pagesEC8553-DISCRETE TIME SIGNAL PROCESSING-1996352284-Unit 1-NotesSaanvi KapoorPas encore d'évaluation
- A Memory-Based FFT Processor Design With Generalized Efficient Conflict-Free Address SchemesDocument11 pagesA Memory-Based FFT Processor Design With Generalized Efficient Conflict-Free Address Schemessai haritha kavuluruPas encore d'évaluation