Vous aimerez peut-être aussi
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Network Engineer Interview QuestionsDocument35 pagesNetwork Engineer Interview QuestionsOsama Munir100% (8)
- Passking: Reliable Test Question & New Testking PDF & Wonderful Pass ScoreDocument27 pagesPassking: Reliable Test Question & New Testking PDF & Wonderful Pass ScoreSasha UlizkoPas encore d'évaluation
- K.O King by Zint PDFDocument52 pagesK.O King by Zint PDFH-S93% (14)
- IV9000 Hardware GuideDocument44 pagesIV9000 Hardware GuideOrlando BarretoPas encore d'évaluation
- Seo Proposal TemplateDocument10 pagesSeo Proposal TemplateasinPas encore d'évaluation
- ADVT - No - CRPD - 08 Fo 2022-23Document6 pagesADVT - No - CRPD - 08 Fo 2022-23Harshaditya Singh ChauhanPas encore d'évaluation
- A Letter From Borneo - James Brooke PDFDocument51 pagesA Letter From Borneo - James Brooke PDFBebaju WanitaPas encore d'évaluation
- Quick Guide For Activating eSIM On Motorola DevicesDocument13 pagesQuick Guide For Activating eSIM On Motorola Devicessud rewaniPas encore d'évaluation
- Documents - Pub - Web Dynpro Abap scn3 PDFDocument32 pagesDocuments - Pub - Web Dynpro Abap scn3 PDFTamilan TamilPas encore d'évaluation
- Digital Literacy An OverviewDocument8 pagesDigital Literacy An OverviewEditor IJTSRDPas encore d'évaluation
- Collabora Online Installation GuideDocument22 pagesCollabora Online Installation GuideMiguel Angel Dorado GomezPas encore d'évaluation
- How To Use Social Media ResponsiblyDocument1 pageHow To Use Social Media ResponsiblyDhanne Jhaye LaboredaPas encore d'évaluation
- Telnet FTPDocument18 pagesTelnet FTPAaruni GoelPas encore d'évaluation
- Janitza-Especificaciones Técnicas-UMG604Document18 pagesJanitza-Especificaciones Técnicas-UMG604Pablo RodaPas encore d'évaluation
- Introduction To HTMLDocument45 pagesIntroduction To HTMLgeetanjaliPas encore d'évaluation
- VPS - Cloud Comparision SheetDocument4 pagesVPS - Cloud Comparision SheetJagdish EmmehattiPas encore d'évaluation
- Cryptography: Aim of WorkshopDocument11 pagesCryptography: Aim of WorkshopWiwiPas encore d'évaluation
- CnPilot Enterprise Wi Fi Access Points 4.2 User Guide Meltec CambiumDocument263 pagesCnPilot Enterprise Wi Fi Access Points 4.2 User Guide Meltec CambiumCamilo CruzPas encore d'évaluation
- Karel ProgDocument71 pagesKarel Progyogeshkumar050792Pas encore d'évaluation
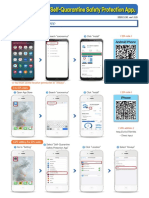
- User Manual (Self Quarantine App)Document2 pagesUser Manual (Self Quarantine App)Zaira KimPas encore d'évaluation
- Orchestration 2: Writing Techniques For Full Orchestra - RequirementsDocument2 pagesOrchestration 2: Writing Techniques For Full Orchestra - RequirementsGamal AsaadPas encore d'évaluation
- Virtual Class ManagementDocument10 pagesVirtual Class ManagementGaurang MakwanaPas encore d'évaluation
- Kalel CV Updated PDFDocument3 pagesKalel CV Updated PDFShir SharPas encore d'évaluation
- Privacy Policy Template: Up To Our Mailing List or When Completing The New Enquiry Form On The Website)Document2 pagesPrivacy Policy Template: Up To Our Mailing List or When Completing The New Enquiry Form On The Website)kalinovskayaPas encore d'évaluation
- 5331 Proje Wep PDF 1Document5 pages5331 Proje Wep PDF 1api-550118247Pas encore d'évaluation
- Bootstrap Mock TestDocument7 pagesBootstrap Mock TestMahesh VPPas encore d'évaluation
- CodeIgniter JQuery Ajax Post Data - FormGetDocument16 pagesCodeIgniter JQuery Ajax Post Data - FormGetBarnabas GuloPas encore d'évaluation
- Liber8 Configurations v6Document175 pagesLiber8 Configurations v6Patrick DugganPas encore d'évaluation
- BT-P8108H 8 PON GPON OLT Datasheet v2Document4 pagesBT-P8108H 8 PON GPON OLT Datasheet v2nayux ruizPas encore d'évaluation
- DH-XVR5116HS-X Datasheet: Quick SpecDocument5 pagesDH-XVR5116HS-X Datasheet: Quick SpecZoumana KaridioulaPas encore d'évaluation