Vous aimerez peut-être aussi
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- AsaaaDocument17 pagesAsaaakristina sipayungPas encore d'évaluation
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- 1Document1 page1kristina sipayungPas encore d'évaluation
- Daftar Nilai OlahragaDocument6 pagesDaftar Nilai Olahragakristina sipayungPas encore d'évaluation
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Abstrak TranslateDocument1 pageAbstrak Translatekristina sipayungPas encore d'évaluation
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
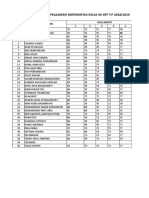
- Rata-Rata Rapot Kelas XiiDocument6 pagesRata-Rata Rapot Kelas Xiikristina sipayungPas encore d'évaluation
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Kristina Sipayung: Teknologi Industri PertanianDocument1 pageKristina Sipayung: Teknologi Industri Pertaniankristina sipayungPas encore d'évaluation
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Traditional Plants As Source of Functional FoodsSDocument8 pagesTraditional Plants As Source of Functional FoodsSkristina sipayungPas encore d'évaluation
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Biographical: Home AddressDocument3 pagesBiographical: Home Addresskristina sipayungPas encore d'évaluation
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Menerima Sertifikat Hibah Pengembangan Kreativitas Mahasiswa Bidang Kewirausahaan Dari DiktiDocument1 pageMenerima Sertifikat Hibah Pengembangan Kreativitas Mahasiswa Bidang Kewirausahaan Dari Diktikristina sipayungPas encore d'évaluation
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- Nilai Raport 2018-2019Document1 pageNilai Raport 2018-2019kristina sipayungPas encore d'évaluation
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Nilai Raport 2018-2019Document1 pageNilai Raport 2018-2019kristina sipayungPas encore d'évaluation
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- 111Document2 pages111kristina sipayungPas encore d'évaluation
- Menerima Sertifikat Hibah Pengembangan Kreativitas Mahasiswa Bidang Kewirausahaan Dari DiktiDocument1 pageMenerima Sertifikat Hibah Pengembangan Kreativitas Mahasiswa Bidang Kewirausahaan Dari Diktikristina sipayungPas encore d'évaluation
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- 111Document2 pages111kristina sipayungPas encore d'évaluation
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Impact of 16S RRNA Gene Sequence Analysis For Identification of Bacteria On Clinical Microbiology and Infectious DiseaseDocument20 pagesImpact of 16S RRNA Gene Sequence Analysis For Identification of Bacteria On Clinical Microbiology and Infectious Diseasekristina sipayungPas encore d'évaluation
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Chinma2016 PDFDocument6 pagesChinma2016 PDFArnettaPas encore d'évaluation
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- Effect of Acha and Bambara Nut Sourdough Flour Addition On The Quality of BreadDocument7 pagesEffect of Acha and Bambara Nut Sourdough Flour Addition On The Quality of Breadkristina sipayungPas encore d'évaluation
- Kelas 3 SDDocument1 pageKelas 3 SDkristina sipayungPas encore d'évaluation
- Kelas 6 SDDocument1 pageKelas 6 SDkristina sipayungPas encore d'évaluation
- Chestnut Flour Addition in Commercial GlutenDocument8 pagesChestnut Flour Addition in Commercial Glutenkristina sipayungPas encore d'évaluation
- The Technological Value of Trans Isomers Formed by Hydrogenation Has Been Illustrated in A Range of ProductsDocument2 pagesThe Technological Value of Trans Isomers Formed by Hydrogenation Has Been Illustrated in A Range of Productskristina sipayungPas encore d'évaluation
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Makalah Pi Pangan Kelompok 3Document4 pagesMakalah Pi Pangan Kelompok 3kristina sipayungPas encore d'évaluation
- Study On Knowledge, Attitude and Practice of Tuberculosis Among Rural Population of Tamil NaduDocument8 pagesStudy On Knowledge, Attitude and Practice of Tuberculosis Among Rural Population of Tamil Nadukristina sipayungPas encore d'évaluation
- Bread Enriched With Flour From Cinereous CockroachDocument7 pagesBread Enriched With Flour From Cinereous Cockroachkristina sipayungPas encore d'évaluation
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Palmoil PDFDocument10 pagesPalmoil PDFkristina sipayungPas encore d'évaluation
- Presentasi Metode Analisis SensoriDocument4 pagesPresentasi Metode Analisis Sensorikristina sipayungPas encore d'évaluation
- From Deterministic To Probabilistic Way of Thinking in Structural EngineeringDocument5 pagesFrom Deterministic To Probabilistic Way of Thinking in Structural EngineeringswapnilPas encore d'évaluation
- Garlic and Cancer PreventionDocument7 pagesGarlic and Cancer Preventionkristina sipayungPas encore d'évaluation
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Studies On The Effect of AllicinDocument1 pageStudies On The Effect of Allicinkristina sipayungPas encore d'évaluation
- Tamesol - TM Series Limited WarrantyDocument9 pagesTamesol - TM Series Limited WarrantyJason G AbalajenPas encore d'évaluation
- Ch19 Profit MaximizationDocument86 pagesCh19 Profit MaximizationUyên MiPas encore d'évaluation
- HSBC Sector AnalysisDocument342 pagesHSBC Sector AnalysisvinaymathewPas encore d'évaluation
- Littlefield Game 2 OverviewDocument3 pagesLittlefield Game 2 OverviewRichard Joshua SPas encore d'évaluation
- ECON1Document5 pagesECON1Meetanshi GabaPas encore d'évaluation
- Latest ACI 3I0-012 Exam Training Materials Free TryDocument5 pagesLatest ACI 3I0-012 Exam Training Materials Free TryGonzalezoesPas encore d'évaluation
- PalengkeDocument15 pagesPalengkeJose Louie Quilos FalsisPas encore d'évaluation
- Credit & Borrowing - Cambridge PDFDocument28 pagesCredit & Borrowing - Cambridge PDFdiana_kalinskaPas encore d'évaluation
- Extra Practice QuestionsDocument4 pagesExtra Practice QuestionsJedPas encore d'évaluation
- L'Oreal - A Case of Global BrandDocument16 pagesL'Oreal - A Case of Global Brandptvu1990100% (1)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Cost Segregation IllustrationDocument4 pagesCost Segregation IllustrationJessica Aningat50% (4)
- David Wessels - Corporate Strategy and ValuationDocument26 pagesDavid Wessels - Corporate Strategy and Valuationesjacobsen100% (1)
- Advacc 1 Answer Key Set ADocument3 pagesAdvacc 1 Answer Key Set AA BPas encore d'évaluation
- Jeffrey Kennedy - The Trader's Classroom Collection - Volume 3 (2009, Elliott Wave International)Document46 pagesJeffrey Kennedy - The Trader's Classroom Collection - Volume 3 (2009, Elliott Wave International)Charlie Sheen88% (8)
- Material Management Study Material - MCQDocument15 pagesMaterial Management Study Material - MCQsudipta maity100% (3)
- Befa Unit 1Document17 pagesBefa Unit 1ManikantaPas encore d'évaluation
- Preliminary Estimate Unit Valuation MethodDocument12 pagesPreliminary Estimate Unit Valuation MethodEspada KnightPas encore d'évaluation
- Sample Chapter PDFDocument36 pagesSample Chapter PDFDinesh KumarPas encore d'évaluation
- Industry AnalysisDocument24 pagesIndustry AnalysisSaurabh Krishna SinghPas encore d'évaluation
- Me Late Chocolate DraftDocument29 pagesMe Late Chocolate DraftNatalia OchoaPas encore d'évaluation
- Money & Banking DallasDocument16 pagesMoney & Banking DallasBZ Riger100% (1)
- Kpis: Improving Supply Chain Performance ManagementDocument33 pagesKpis: Improving Supply Chain Performance Managementgaumzy091985Pas encore d'évaluation
- Acc 205 Ca1Document11 pagesAcc 205 Ca1Nidhi SharmaPas encore d'évaluation
- Smart Money ConceptDocument5 pagesSmart Money ConceptweeleePas encore d'évaluation
- Wrigley Case FinalDocument9 pagesWrigley Case FinalhnooyPas encore d'évaluation
- B.S Studies Pack BookDocument225 pagesB.S Studies Pack Bookjungleman marandaPas encore d'évaluation
- MACROECONOMICS Test (Finals)Document76 pagesMACROECONOMICS Test (Finals)Merry Juannie U. PatosaPas encore d'évaluation
- National Stock Exchange of India Limited: Financial Markets, Products & InstitutionsDocument3 pagesNational Stock Exchange of India Limited: Financial Markets, Products & InstitutionsBasith BaderiPas encore d'évaluation
- Making Good ChoicesDocument6 pagesMaking Good ChoicesdrgPas encore d'évaluation
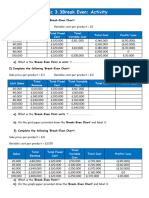
- 3.3 Break Even Charts and Break Even Analysis ActivityDocument2 pages3.3 Break Even Charts and Break Even Analysis ActivityZARWAREEN FAISALPas encore d'évaluation