Vous aimerez peut-être aussi
- Monografia ModeloDocument62 pagesMonografia Modelocristina100% (1)
- La Economía Del Bien Común - Gemma Fajardo GarcíaDocument9 pagesLa Economía Del Bien Común - Gemma Fajardo GarcíaEconomía DigitalPas encore d'évaluation
- Prácticas Video KdenliveDocument7 pagesPrácticas Video KdenliveYoPas encore d'évaluation
- Manual Operador Burny PhantomDocument42 pagesManual Operador Burny PhantomKlaus Karner75% (4)
- Manual de s10Document41 pagesManual de s10Carlos Vivas33% (3)
- Estadistica Aplicada A La Investigacion Cientifica Pag. 59-76Document15 pagesEstadistica Aplicada A La Investigacion Cientifica Pag. 59-76Alicia Jimenez PradoPas encore d'évaluation
- 2008 Perdices de Blas - Diccionario de Historia Del Pensamiento Económico PDFDocument150 pages2008 Perdices de Blas - Diccionario de Historia Del Pensamiento Económico PDFEdgardo Morales90% (10)
- Calculo Diferencial e Integral Con Aplicaciones ActuarialesDocument142 pagesCalculo Diferencial e Integral Con Aplicaciones Actuarialesapolo45683% (6)
- Didáctica de las matemáticas: De preescolar a secundariaD'EverandDidáctica de las matemáticas: De preescolar a secundariaPas encore d'évaluation
- Mof Ugel HuariDocument81 pagesMof Ugel HuariFernando Joseph Asencios Villajuan50% (2)
- Matematicas Con ScilabDocument114 pagesMatematicas Con ScilabYairFloresPas encore d'évaluation
- Alessandro Roncaglia La Riqueza de Las Ideas. Una Historia Del Pensamiento EconomicoDocument781 pagesAlessandro Roncaglia La Riqueza de Las Ideas. Una Historia Del Pensamiento Economicoanarkike100% (4)
- Computacion Seccion Primaria PDFDocument103 pagesComputacion Seccion Primaria PDFLuis Alberto BellidoPas encore d'évaluation
- Trabajo Final PDFDocument2 pagesTrabajo Final PDFYann Clinton Gommez FernandezPas encore d'évaluation
- Programacion en EviewsDocument16 pagesProgramacion en EviewsJhon Ortega GarciaPas encore d'évaluation
- Aplicación de Modelos de Series de Tiempo para La Predicción A Corto Plazo de La Producción de Post - Larvas de Camarón en La Empresa Farallon Aquaculture S.A. Las Peñitas, Leon.Document41 pagesAplicación de Modelos de Series de Tiempo para La Predicción A Corto Plazo de La Producción de Post - Larvas de Camarón en La Empresa Farallon Aquaculture S.A. Las Peñitas, Leon.DAURIVAN JIMÉNEZ MOLINA100% (1)
- Práctica 2Document3 pagesPráctica 2Rodrigo ContrerasPas encore d'évaluation
- Manual Stata 11 PDFDocument365 pagesManual Stata 11 PDFShelly Stefhany Laban Seminario100% (3)
- Examen Final Modelos Económicos 2.016-2Document3 pagesExamen Final Modelos Económicos 2.016-2Marisol ArroyavePas encore d'évaluation
- Ejemplos de TesisDocument117 pagesEjemplos de TesisRolin Aliaga VarillasPas encore d'évaluation
- Balotario 04Document1 pageBalotario 04Hermanos Julcamoro CortezPas encore d'évaluation
- Panel Dinamico ArellanoDocument13 pagesPanel Dinamico ArellanoJoselyn Romero TamaraPas encore d'évaluation
- 1 Silabo Finanzas Avanzadas (E) (2021 B)Document5 pages1 Silabo Finanzas Avanzadas (E) (2021 B)ARNOLD ANIBAL RUIZ SUCAPUCAPas encore d'évaluation
- CEPLAN - Perú 2050 - Informe de Análisis Prospectivo (2021-2022) PDFDocument253 pagesCEPLAN - Perú 2050 - Informe de Análisis Prospectivo (2021-2022) PDFJOSE MIGUEL OJEDA PEREZPas encore d'évaluation
- Crisis y Liquidación de Bancos en El Perú. (PDJ)Document81 pagesCrisis y Liquidación de Bancos en El Perú. (PDJ)Angie RSPas encore d'évaluation
- ARIMADocument15 pagesARIMAjosue posadaPas encore d'évaluation
- Taller Operacionalización de VariablesDocument5 pagesTaller Operacionalización de VariablesKleber Yitzak Abarca TiconaPas encore d'évaluation
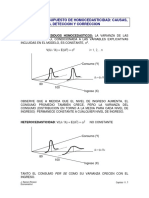
- Capitulo11 Violacion Del Supuesto de Homocedasticidad: Causas, Consecuencias, Deteccion y CorreccionDocument10 pagesCapitulo11 Violacion Del Supuesto de Homocedasticidad: Causas, Consecuencias, Deteccion y CorreccionFlor Chura YucraPas encore d'évaluation
- Aplicaciones en Economía y Ciencias Sociales Con Stata: January 2013Document17 pagesAplicaciones en Economía y Ciencias Sociales Con Stata: January 2013Toño FasanandoPas encore d'évaluation
- Trabajo Eviews Series de Tiempo EconometriaDocument16 pagesTrabajo Eviews Series de Tiempo EconometriaEsteban Paredes FuentesPas encore d'évaluation
- Ficha Ex PostDocument7 pagesFicha Ex PostMaribel Condori PacoPas encore d'évaluation
- FM-Esperanza de Vida EscolarDocument4 pagesFM-Esperanza de Vida EscolarVioleta Alvarez GuillenPas encore d'évaluation
- Demanda Habeas Corpus-Rojas 09-09-2010Document8 pagesDemanda Habeas Corpus-Rojas 09-09-2010Alex G.Pas encore d'évaluation
- Curso de Eviews GoretacnaDocument4 pagesCurso de Eviews GoretacnaJuan TonconiPas encore d'évaluation
- Manual Eviews IntermedioDocument75 pagesManual Eviews IntermedioRiskmetricoPas encore d'évaluation
- Caratula de Fisica 2 en LatexDocument2 pagesCaratula de Fisica 2 en LatexNoeQuispeGordilloPas encore d'évaluation
- Ejercicios y Problemas Resueltos de Matrices. Colección A. MasMates. Matemáticas de SecundariaDocument2 pagesEjercicios y Problemas Resueltos de Matrices. Colección A. MasMates. Matemáticas de SecundariaSebastian andres Argote gonzaLezPas encore d'évaluation
- Die-01-2004-Di-modelos Var y VCM para CosDocument32 pagesDie-01-2004-Di-modelos Var y VCM para CosCésar ChávezPas encore d'évaluation
- Clase de Econometría Parcial 2Document18 pagesClase de Econometría Parcial 2Luu BeHlPas encore d'évaluation
- Ruiz YdDocument140 pagesRuiz YdDoan Daniel Lopez HidalgoPas encore d'évaluation
- Datos de Panel - Un Enfoque PracticoDocument57 pagesDatos de Panel - Un Enfoque PracticoJosé Edwind Chapilliquen Carmen100% (2)
- PDC Fajardo 2016Document236 pagesPDC Fajardo 2016Anonymous 604vWmVPas encore d'évaluation
- Estadistica Inferencial - 2014 - Flores PDFDocument127 pagesEstadistica Inferencial - 2014 - Flores PDFdacsilPas encore d'évaluation
- Trabajo Final Ppi PDFDocument61 pagesTrabajo Final Ppi PDFRogerCarbajalIngaPas encore d'évaluation
- MSc. en Econometría Bancaria y Financiera UNIDocument7 pagesMSc. en Econometría Bancaria y Financiera UNIMarco AntonioPas encore d'évaluation
- UTPL Peñaherrera Aguilar Martha Alexandra 331X129Document84 pagesUTPL Peñaherrera Aguilar Martha Alexandra 331X129manullanesPas encore d'évaluation
- Solicitud de Aprobación de Tema de TesisDocument8 pagesSolicitud de Aprobación de Tema de TesisJose PerezPas encore d'évaluation
- Quien Es Gabriel Gallo OlmosDocument1 pageQuien Es Gabriel Gallo OlmosSonali Herreras PalominoPas encore d'évaluation
- Trabajo Final - Econometria IIDocument4 pagesTrabajo Final - Econometria IIOscar Soler100% (1)
- Formato Secretariado Tec. MedioDocument4 pagesFormato Secretariado Tec. MedioNicolas CostaleitePas encore d'évaluation
- 3 - TH y PR III - Dinamicos - PRINTDocument17 pages3 - TH y PR III - Dinamicos - PRINTRocio Cazorla ParedesPas encore d'évaluation
- Silabo. de Análisis de RegresiónDocument5 pagesSilabo. de Análisis de RegresiónAlejandro Llempen SolanoPas encore d'évaluation
- Syllabus Stata para Economistas Lambda GroupDocument3 pagesSyllabus Stata para Economistas Lambda GroupOsk ETPas encore d'évaluation
- Resumen Del Problema Del Empleo en Una Sociedad SigmaDocument6 pagesResumen Del Problema Del Empleo en Una Sociedad SigmaMery Jimenez RamirezPas encore d'évaluation
- Informe Comision Ampl. Hospital Vinto - Fase V (Anpe)Document4 pagesInforme Comision Ampl. Hospital Vinto - Fase V (Anpe)aruquipacallema5753Pas encore d'évaluation
- Modelos de Respuesta Discreta en R y AplicaciónDocument101 pagesModelos de Respuesta Discreta en R y AplicaciónCristianAlexisCabreraObrequePas encore d'évaluation
- 2019 - 2 Introduccion Regresion LinealDocument33 pages2019 - 2 Introduccion Regresion Linealdavid bellidoPas encore d'évaluation
- Guia de Universidades Privadas de BoliviaDocument82 pagesGuia de Universidades Privadas de Boliviacarlosjohnny100% (1)
- Miscelánea de EconomiaDocument4 pagesMiscelánea de EconomiaBrigithe Susan Cachicatari MolinaPas encore d'évaluation
- 9.analisis DiscriminanteDocument21 pages9.analisis DiscriminanteKatty MarisolPas encore d'évaluation
- Material Del CursoDocument128 pagesMaterial Del CursoFerlyUrdayLunaPas encore d'évaluation
- EconomiaEmpresa0708 PDFDocument312 pagesEconomiaEmpresa0708 PDFmanuelPas encore d'évaluation
- Evaluación de Impacto Del Programa de Textos y Uniformes Escolar - Juan Ponce y Maré - 2017n LópezDocument32 pagesEvaluación de Impacto Del Programa de Textos y Uniformes Escolar - Juan Ponce y Maré - 2017n LópezCindy ChiribogaPas encore d'évaluation
- Teoría de La Regulación Económica - Regulación Del Monopolio Natural MonoproductorDocument36 pagesTeoría de La Regulación Económica - Regulación Del Monopolio Natural MonoproductornekbadPas encore d'évaluation
- Silabo Comercio ExteriorDocument5 pagesSilabo Comercio ExteriorLesly Vasquez CuevaPas encore d'évaluation
- Manual Stata BasicoDocument79 pagesManual Stata BasicoLuis BautistaPas encore d'évaluation
- Trabajo MLGDocument36 pagesTrabajo MLGisidora.rusnighiPas encore d'évaluation
- Tesis PDFDocument72 pagesTesis PDFIliana VargasPas encore d'évaluation
- Analisis, Sintesis, y Construccion de Un Controlador Adaptable-Cenidet PDFDocument162 pagesAnalisis, Sintesis, y Construccion de Un Controlador Adaptable-Cenidet PDFbarPas encore d'évaluation
- Curso de R PDFDocument10 pagesCurso de R PDFEconomía DigitalPas encore d'évaluation
- Resultado Examen Admisión PDFDocument130 pagesResultado Examen Admisión PDFEtty Janampa33% (3)
- Operaciones Con Vectores - FacebookDocument6 pagesOperaciones Con Vectores - FacebookEconomía DigitalPas encore d'évaluation
- Manipulación de Caracteres - Primera ParteDocument9 pagesManipulación de Caracteres - Primera ParteEconomía DigitalPas encore d'évaluation
- Semana3 PDFDocument30 pagesSemana3 PDFEconomía DigitalPas encore d'évaluation
- Como Mantener Los Bancos Independientes - Project SyndicateDocument4 pagesComo Mantener Los Bancos Independientes - Project SyndicateEconomía DigitalPas encore d'évaluation
- Primeros Pasos R - ProjectDocument5 pagesPrimeros Pasos R - ProjectEconomía DigitalPas encore d'évaluation
- Horario de Clases 2018-II-economiaDocument3 pagesHorario de Clases 2018-II-economiaEconomía DigitalPas encore d'évaluation
- Seminar I o Bruno 2012 PDFDocument539 pagesSeminar I o Bruno 2012 PDFEconomía DigitalPas encore d'évaluation
- Comandos Útiles en StataDocument14 pagesComandos Útiles en Statapioter1104100% (1)
- Silabo - Progr. Nivelación - Python y RDocument6 pagesSilabo - Progr. Nivelación - Python y REconomía Digital100% (1)
- Revista de La Facultad de Economía de La UNIDocument18 pagesRevista de La Facultad de Economía de La UNIEconomía DigitalPas encore d'évaluation
- Proyecto de InversionDocument1 pageProyecto de InversionEconomía DigitalPas encore d'évaluation
- Desarrollo Matemático 5Document6 pagesDesarrollo Matemático 5Economía DigitalPas encore d'évaluation
- Gates Bill-Camino Al FuturoDocument241 pagesGates Bill-Camino Al FuturoAndres Vasquez100% (3)
- BasesDocument6 pagesBasesEconomía DigitalPas encore d'évaluation
- El Final de La Economia Politica Una CriDocument74 pagesEl Final de La Economia Politica Una CriAndrés AvilésPas encore d'évaluation
- Buchanan, J.MDocument13 pagesBuchanan, J.Mapi-3726523Pas encore d'évaluation
- Roca (2009) MacroeconomiaAvanzadaDocument126 pagesRoca (2009) MacroeconomiaAvanzadalizjor100% (1)
- Optimizacion - Programacion Lineal y No LinealDocument160 pagesOptimizacion - Programacion Lineal y No LinealMiguel AcbPas encore d'évaluation
- Estudios de Caso Sobre Regulación en Infraestructura y Servicios Públicos en El PeruDocument212 pagesEstudios de Caso Sobre Regulación en Infraestructura y Servicios Públicos en El PeruJuan AlayoPas encore d'évaluation
- Modulo4 EleccionesConsumidores - CompressedDocument21 pagesModulo4 EleccionesConsumidores - CompressedEconomía DigitalPas encore d'évaluation
- El Ciclo Economico Alan J CageDocument311 pagesEl Ciclo Economico Alan J CagealiagavPas encore d'évaluation
- Capitulo 3 PDFDocument25 pagesCapitulo 3 PDFEconomía DigitalPas encore d'évaluation
- Optimizacion - Programacion Lineal y No LinealDocument160 pagesOptimizacion - Programacion Lineal y No LinealMiguel AcbPas encore d'évaluation
- Unidad IV - Auditoría de SistemasDocument13 pagesUnidad IV - Auditoría de SistemasCristina Muñoz OrdoñezPas encore d'évaluation
- Como Crear Un PDF Con Varios PDF en MacDocument2 pagesComo Crear Un PDF Con Varios PDF en MacLaurenPas encore d'évaluation
- Ejercicios de Diseño de Base de DatosDocument5 pagesEjercicios de Diseño de Base de DatosPiereLuisAOPas encore d'évaluation
- D Conceptos Basicos en ElcadDocument18 pagesD Conceptos Basicos en Elcadjhadhiel ccora noaPas encore d'évaluation
- USB Flash Drive TesterDocument5 pagesUSB Flash Drive TesterFrancisco Del PuertoPas encore d'évaluation
- TEMA 1. Métodos de Captura de InformaciónDocument46 pagesTEMA 1. Métodos de Captura de InformaciónCarlos Suárez MenéndezPas encore d'évaluation
- Manual de Uso Del Gestor de Correo ElectrónicoDocument22 pagesManual de Uso Del Gestor de Correo ElectrónicoSergioPas encore d'évaluation
- Como DinescomoDocument4 pagesComo Dinescomomauricio901018Pas encore d'évaluation
- Manual de Linux y BlenderDocument55 pagesManual de Linux y BlenderAndrea PriegoPas encore d'évaluation
- Listar Archivos de Un Directorio en ASPDocument9 pagesListar Archivos de Un Directorio en ASPGregorioPas encore d'évaluation
- Hackig ÉticoDocument10 pagesHackig ÉticoCarlos Alberto Borda DonairePas encore d'évaluation
- Curso de Google DriveDocument45 pagesCurso de Google DriveGustavo Alberto Vargas RuizPas encore d'évaluation
- Manual Sisup 2013 PDFDocument48 pagesManual Sisup 2013 PDFMiguel ÁngelPas encore d'évaluation
- Lecturas Tema 6Document11 pagesLecturas Tema 6María José Hernández FaríasPas encore d'évaluation
- LeemeDocument123 pagesLeemeMateo Melgarejo SanchezPas encore d'évaluation
- Uso de Adove Reader XDocument15 pagesUso de Adove Reader XJosèyAlicia Chapman Y GrajedaPas encore d'évaluation
- Manual e 1000 1Document26 pagesManual e 1000 1Carlos AvendañoPas encore d'évaluation
- Como Crear Archivos Ejecutables en Instalables en JavaDocument16 pagesComo Crear Archivos Ejecutables en Instalables en JavaGerardo Rincón SaucedoPas encore d'évaluation
- Diferencia Shapefile - RasterDocument4 pagesDiferencia Shapefile - RasterRichard Icaro EsparzaPas encore d'évaluation
- Como Instalar eXeLearning en Ubuntu 10Document32 pagesComo Instalar eXeLearning en Ubuntu 10123cPas encore d'évaluation
- Evaluacion EscritaDocument2 pagesEvaluacion EscritaGustavo Rojas MendezPas encore d'évaluation
- Tarea Cinco Informe de Gestión Documental OrganizacionDocument5 pagesTarea Cinco Informe de Gestión Documental Organizacionantonio aguileraPas encore d'évaluation
- Manual Pce t390Document16 pagesManual Pce t390PaulaErikaMAPas encore d'évaluation
- Unidad 4 Tema 2 Plan de ContigenciaDocument44 pagesUnidad 4 Tema 2 Plan de ContigenciaAlbertoXavierPas encore d'évaluation