Vous aimerez peut-être aussi
- Emp - Id Emp - Name Emp - Address Emp - Dept 101 Rick Delhi D001 101 Rick Delhi D002Document15 pagesEmp - Id Emp - Name Emp - Address Emp - Dept 101 Rick Delhi D001 101 Rick Delhi D002sharmilaPas encore d'évaluation
- DBMS Chap 3Document17 pagesDBMS Chap 3Harsh OjhaPas encore d'évaluation
- Swami Vivekanand College of EngineeringDocument11 pagesSwami Vivekanand College of EngineeringKunal UpadhyayPas encore d'évaluation
- NormalisationDocument18 pagesNormalisationNeelesh BhattacharjeePas encore d'évaluation
- Database Normalization: 1NF, 2NF, 3NF and BCNF Explained with ExamplesDocument18 pagesDatabase Normalization: 1NF, 2NF, 3NF and BCNF Explained with ExamplesJeevitha BandiPas encore d'évaluation
- Unit 3 DBMS - 1596870407Document16 pagesUnit 3 DBMS - 1596870407Yadu Patidar100% (1)
- Lecture Week2Document27 pagesLecture Week2A DanPas encore d'évaluation
- Normalization in DBMSDocument17 pagesNormalization in DBMShemacrcPas encore d'évaluation
- Concurrency Control in DBMS GeeksforGeeksDocument6 pagesConcurrency Control in DBMS GeeksforGeeksRajan GuptaPas encore d'évaluation
- UNIT-5: Read (X) : Performs The Reading Operation of Data Item X From The DatabaseDocument37 pagesUNIT-5: Read (X) : Performs The Reading Operation of Data Item X From The DatabaseChandu SekharPas encore d'évaluation
- Rdbms Unit IIDocument68 pagesRdbms Unit IIrogithaPas encore d'évaluation
- What Is Lock - Type of Lock in DBMSDocument7 pagesWhat Is Lock - Type of Lock in DBMScompiler&automataPas encore d'évaluation
- Introduction To RDBMSDocument9 pagesIntroduction To RDBMSBhola ThPas encore d'évaluation
- RDBMS ConceptsDocument54 pagesRDBMS ConceptsRajkumar RahkumarPas encore d'évaluation
- DBMS Concurrency Control TutorialspointDocument3 pagesDBMS Concurrency Control TutorialspointSrinivasarao SrinivasaraoPas encore d'évaluation
- Two Phase Locking 2PL Concurrency Control Protocol - Set 3 GeeksforGeeksDocument6 pagesTwo Phase Locking 2PL Concurrency Control Protocol - Set 3 GeeksforGeeksRohit RathorPas encore d'évaluation
- Normalization AssignmentDocument9 pagesNormalization AssignmentHaniya ChPas encore d'évaluation
- BrainKart - All Department - ANNA UNIVERSITY Important Question and Answers - Regulation 2013,2017 - STUDY MATERIAL, NotesDocument25 pagesBrainKart - All Department - ANNA UNIVERSITY Important Question and Answers - Regulation 2013,2017 - STUDY MATERIAL, NotesKali Thaash100% (1)
- Unit-4 DBMS NotesDocument32 pagesUnit-4 DBMS NotesAmrith MadhiraPas encore d'évaluation
- DBMS4Document23 pagesDBMS4rocketgamer054Pas encore d'évaluation
- DBMS Topics Covering Database Design, Normalization, Transactions, RecoveryDocument1 pageDBMS Topics Covering Database Design, Normalization, Transactions, RecoveryDayakar Chalamcharla100% (1)
- DBMS DeadlockDocument10 pagesDBMS DeadlockRehman HazratPas encore d'évaluation
- Normalization of Database: First Normal Form (1NF)Document10 pagesNormalization of Database: First Normal Form (1NF)Piyush JainPas encore d'évaluation
- Single-User vs. Multi-User System: Dbms - Module - 5 - NotesDocument19 pagesSingle-User vs. Multi-User System: Dbms - Module - 5 - NotesGoutam SachiPas encore d'évaluation
- AI Problem SolvingDocument55 pagesAI Problem SolvingRakeshPas encore d'évaluation
- Deadlock HandlingDocument3 pagesDeadlock HandlingAnjali Ganesh Jivani100% (3)
- Exercise Part B Unit 4Document5 pagesExercise Part B Unit 4vansh bhardwajPas encore d'évaluation
- Mca Dbms Notes Unit 1Document36 pagesMca Dbms Notes Unit 1Keshava VarmaPas encore d'évaluation
- Database NotesDocument122 pagesDatabase NotesAtul TodePas encore d'évaluation
- Teradata Bteq, Mload, Fload, Fexport, Tpump and SamplingDocument49 pagesTeradata Bteq, Mload, Fload, Fexport, Tpump and SamplingPrashanth GupthaPas encore d'évaluation
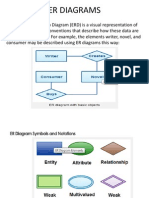
- Er DiagramsDocument20 pagesEr DiagramsUddiptta Ujjawal100% (1)
- SQL Interview Questions For Software TestersDocument9 pagesSQL Interview Questions For Software TestersDudi Kumar100% (1)
- ACID Properties in DBMSDocument11 pagesACID Properties in DBMSmother theressaPas encore d'évaluation
- Reasons For NormalizationDocument15 pagesReasons For NormalizationKIRANPas encore d'évaluation
- Use Advanced Structured Query LanguageDocument91 pagesUse Advanced Structured Query LanguageGetasilPas encore d'évaluation
- DBMS Unit 5Document12 pagesDBMS Unit 5Naresh BabuPas encore d'évaluation
- Cse Department - ANNA UNIVERSITY Important Question and Answers - Regulation 2013,2017 - STUDY MATERIAL, NotesDocument5 pagesCse Department - ANNA UNIVERSITY Important Question and Answers - Regulation 2013,2017 - STUDY MATERIAL, NotesKali ThaashPas encore d'évaluation
- Dbms Viva QuestionsDocument39 pagesDbms Viva QuestionsonrreddyPas encore d'évaluation
- Different Types of SQL JoinsDocument12 pagesDifferent Types of SQL JoinsKarla Hernández AburtoPas encore d'évaluation
- SQL Queries Table Name:-Employee: Empi D Empnam E Departmen T Contactno Emailid Empheadi DDocument4 pagesSQL Queries Table Name:-Employee: Empi D Empnam E Departmen T Contactno Emailid Empheadi DJesin John LMC19MCA003Pas encore d'évaluation
- Nested Queries and Join QueriesDocument6 pagesNested Queries and Join QueriesRevathimuthusamy100% (1)
- DBMS Unit VDocument17 pagesDBMS Unit VKeshava VarmaPas encore d'évaluation
- DBMS Question Bank SOCET CE DepartmentDocument6 pagesDBMS Question Bank SOCET CE DepartmentSingh BhiPas encore d'évaluation
- Introduction To Teradata Utilities: MultiloadDocument36 pagesIntroduction To Teradata Utilities: MultiloadkishoreparasaPas encore d'évaluation
- Relational ModelDocument20 pagesRelational ModelMag CreationPas encore d'évaluation
- Join Index and Hash Index in Teradata 14Document20 pagesJoin Index and Hash Index in Teradata 14Rajesh RaiPas encore d'évaluation
- Given Table NormalizationDocument3 pagesGiven Table NormalizationPraful MathurPas encore d'évaluation
- The Relational Data Model Concepts and ConstraintsDocument28 pagesThe Relational Data Model Concepts and ConstraintsSiddhartha ShetyPas encore d'évaluation
- Algorithm Complexity AnalysisDocument236 pagesAlgorithm Complexity Analysisvarsha thakurPas encore d'évaluation
- Duplicate rows caught after sorting data during FLOAD restartDocument1 pageDuplicate rows caught after sorting data during FLOAD restartSeshu VenkatPas encore d'évaluation
- CS8792-Cryptography and Network SecurityDocument10 pagesCS8792-Cryptography and Network SecurityKishan KumarPas encore d'évaluation
- Unit 5: TransactionsDocument23 pagesUnit 5: TransactionsYesudas100% (1)
- Ambo University MSc IT Database TechnologyDocument28 pagesAmbo University MSc IT Database Technologymikeyas meseret100% (1)
- Convert 2NF Table to 3NF by Removing Transitive DependencyDocument1 pageConvert 2NF Table to 3NF by Removing Transitive Dependencyken linPas encore d'évaluation
- SQL QuestionsDocument28 pagesSQL Questionssanket@iiit100% (1)
- UNIT 4 Normalization & DenormalizationDocument10 pagesUNIT 4 Normalization & Denormalization23mca006Pas encore d'évaluation
- Normalization in DBMSDocument9 pagesNormalization in DBMSAnonymous DFpzhrRPas encore d'évaluation
- Normalization in DBMSDocument12 pagesNormalization in DBMSAnkush SharmaPas encore d'évaluation
- Employee Management SystemDocument19 pagesEmployee Management Systemhackers earthPas encore d'évaluation
- Normalization For Relational DatabaseDocument12 pagesNormalization For Relational DatabaseJester FFPas encore d'évaluation
- Presentation 1Document4 pagesPresentation 1Ashu JainPas encore d'évaluation
- CS106B Handout 08 StringsDocument9 pagesCS106B Handout 08 StringsAsutosh SahooPas encore d'évaluation
- SMART Birth and Death Registration IntegrationDocument4 pagesSMART Birth and Death Registration IntegrationAshu JainPas encore d'évaluation
- Unit 5 Cyber SecurityDocument27 pagesUnit 5 Cyber SecurityAshu JainPas encore d'évaluation
- Unit - 1 Introduction To Computer Graphics Unit-01/Lecture-01Document30 pagesUnit - 1 Introduction To Computer Graphics Unit-01/Lecture-01Ashu JainPas encore d'évaluation
- IotDocument1 pageIotAshu JainPas encore d'évaluation
- CS106B Handout 08 StringsDocument9 pagesCS106B Handout 08 StringsAsutosh SahooPas encore d'évaluation
- Explaining the basic architecture of a database management system (DBMSDocument34 pagesExplaining the basic architecture of a database management system (DBMSAshu JainPas encore d'évaluation
- Hello SdjflkjasdfDocument1 pageHello SdjflkjasdfAshu JainPas encore d'évaluation
- Database Resource KitDocument136 pagesDatabase Resource KitaalesundPas encore d'évaluation
- Analyze Aggregate Row FunctionsDocument19 pagesAnalyze Aggregate Row Functionsdevang100% (1)
- AplicationdatabaseDocument25 pagesAplicationdatabaseapi-26355935Pas encore d'évaluation
- MS Word and PowerPoint Quiz: Test your knowledge of popular Microsoft Office appsDocument55 pagesMS Word and PowerPoint Quiz: Test your knowledge of popular Microsoft Office appsDharmendra KumarPas encore d'évaluation
- Sap Bods TutorialDocument26 pagesSap Bods TutorialPavan Sandeep V V0% (1)
- Firebird 4.0.0 RC1 ReleaseNotesDocument168 pagesFirebird 4.0.0 RC1 ReleaseNotesjmaster54Pas encore d'évaluation
- JdbcquestionsDocument73 pagesJdbcquestionssubhabirajdarPas encore d'évaluation
- Database System Concepts-2023Document27 pagesDatabase System Concepts-2023張育安Pas encore d'évaluation
- ADO and SQL SERVERDocument493 pagesADO and SQL SERVERKristian CevallosPas encore d'évaluation
- Relational Database and SQL WorksheetDocument9 pagesRelational Database and SQL WorksheetLorena FajardoPas encore d'évaluation
- ProjectDocument5 pagesProjectAsahajit DaluiPas encore d'évaluation
- HCM Subject AreasDocument163 pagesHCM Subject AreasVineet Shukla0% (1)
- Jpa Slides LabDocument45 pagesJpa Slides LabSara HamdaouiPas encore d'évaluation
- Hana Certification PreparationDocument7 pagesHana Certification PreparationSoumabha Chatterjee100% (1)
- Chapter 8 - Introduction To Structured Query Language (SQL)Document7 pagesChapter 8 - Introduction To Structured Query Language (SQL)Anooj ShetePas encore d'évaluation
- Script To Copy Table Data From One Schema To Another SchemaDocument2 pagesScript To Copy Table Data From One Schema To Another Schemaleonard1971Pas encore d'évaluation
- ViewsDocument88 pagesViewsSudheer NaiduPas encore d'évaluation
- Lecture 2 - Database System Concepts and ArchitectureDocument36 pagesLecture 2 - Database System Concepts and ArchitectureRaiyan AhmedPas encore d'évaluation
- DBMS MCQDocument45 pagesDBMS MCQTushar SharmaPas encore d'évaluation
- Android SQLite CRUD and ListView - Android Studio TutorialDocument15 pagesAndroid SQLite CRUD and ListView - Android Studio Tutorialalexander biofröstPas encore d'évaluation
- IBM 000-730 questions and answers practice test with 127 Q&AsDocument6 pagesIBM 000-730 questions and answers practice test with 127 Q&AsrsrnareddyPas encore d'évaluation
- Rails MigrationsDocument1 pageRails Migrationskhuonglh100% (3)
- Lab Book: F. Y. B. B. A. (C.A.) Semester IDocument47 pagesLab Book: F. Y. B. B. A. (C.A.) Semester I3427 Sohana JoglekarPas encore d'évaluation
- JSS Academy of Technical Education: Visvesvaraya Technological UniversityDocument36 pagesJSS Academy of Technical Education: Visvesvaraya Technological Universitysushmitha .s100% (1)
- DBMS Cep 6Document11 pagesDBMS Cep 6GEM FOR GAMESPas encore d'évaluation
- Lab Sheet 08 (ICT.005)Document10 pagesLab Sheet 08 (ICT.005)sewmini hewagePas encore d'évaluation
- Basic Siebel Query Tunning GuideDocument6 pagesBasic Siebel Query Tunning GuideMRWANKADEPas encore d'évaluation
- Week 18 10 ICTDocument55 pagesWeek 18 10 ICTGhadeer AlkhayatPas encore d'évaluation
- Cadastro PneuDocument95 pagesCadastro PneubobgramaPas encore d'évaluation
- Problem with column type on sql server prevents dcm4chee from startingDocument1 pageProblem with column type on sql server prevents dcm4chee from startingutility2 sgPas encore d'évaluation