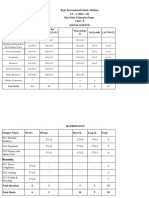
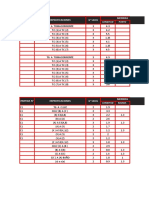
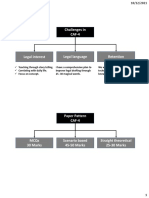
Vous aimerez peut-être aussi
- Year 5 Maths Practice Questions Answer Booklet PDFDocument60 pagesYear 5 Maths Practice Questions Answer Booklet PDFchristiana furaha50% (4)
- Work On Your Accent - OCRDocument155 pagesWork On Your Accent - OCRtmhoangvna100% (1)
- HomeLearning-Unit4Mod1 BDocument5 pagesHomeLearning-Unit4Mod1 BEleanor BurgerPas encore d'évaluation
- Session # 1: Comparing NumbersDocument24 pagesSession # 1: Comparing NumbersFelipe David Montenegro AlvitesPas encore d'évaluation
- Envision Math 3th GR Topic 2Document16 pagesEnvision Math 3th GR Topic 2Anna K. RiveraPas encore d'évaluation
- Avi LKGDocument13 pagesAvi LKGJay SinghPas encore d'évaluation
- PHA7/W: Physics (Specification A) PHA7/W Unit 7 Nuclear Instability: Applied Physics OptionDocument12 pagesPHA7/W: Physics (Specification A) PHA7/W Unit 7 Nuclear Instability: Applied Physics OptionAli WanPas encore d'évaluation
- Topic 1 GR 4 EMDocument20 pagesTopic 1 GR 4 EMVarshikaPas encore d'évaluation
- CoachingDocument59 pagesCoachingMark Anthony CasupangPas encore d'évaluation
- Guy 1989Document5 pagesGuy 1989osman_aiubPas encore d'évaluation
- Divisibility RulesDocument13 pagesDivisibility RulesJeffrey Catacutan FloresPas encore d'évaluation
- The Ambiguity of HeletDocument488 pagesThe Ambiguity of HeletalecacostaPas encore d'évaluation
- Quadro 1Document2 pagesQuadro 1Graziano TrainiPas encore d'évaluation
- Afiq Haikal (Lab Test)Document4 pagesAfiq Haikal (Lab Test)MOHAMAD AFIQ HAIKAL BIN NOR HISHAM / UPMPas encore d'évaluation
- Self-Similar Pitch StructuresDocument26 pagesSelf-Similar Pitch StructuresSergey Vilka100% (1)
- PHA6/W: Physics (Specification A) PHA6/W Unit 6 Nuclear Instability: Medical Physics OptionDocument10 pagesPHA6/W: Physics (Specification A) PHA6/W Unit 6 Nuclear Instability: Medical Physics OptionAli WanPas encore d'évaluation
- MathsDocument10 pagesMathsKhine Cho LattPas encore d'évaluation
- Year 4 Maths Sample Test: Time Allowed: 45 MinutesDocument10 pagesYear 4 Maths Sample Test: Time Allowed: 45 Minutesemmanuel richardPas encore d'évaluation
- Y 4 Entrance Test Part 1Document8 pagesY 4 Entrance Test Part 1Yee MeiPas encore d'évaluation
- Theory:: Figure: Verification of Voltages and Currents in Different Branches in A Ladder NetworkDocument4 pagesTheory:: Figure: Verification of Voltages and Currents in Different Branches in A Ladder NetworkAhmed Nesar Tahsin ChoudhuryPas encore d'évaluation
- (Dwibahasa) Modul Latihan Asas Matematik Tahun 6Document46 pages(Dwibahasa) Modul Latihan Asas Matematik Tahun 6Rosnita Azila AZ100% (4)
- Horario JumDocument2 pagesHorario JumZeida Rojas BastidasPas encore d'évaluation
- 8 Blue PrintDocument7 pages8 Blue PrintShubham ThakurPas encore d'évaluation
- Form Perhit Keb Air DisawahDocument7 pagesForm Perhit Keb Air DisawahachmadPas encore d'évaluation
- Envision Math 3rd GR Topic 1Document18 pagesEnvision Math 3rd GR Topic 1Anna K. RiveraPas encore d'évaluation
- Ecelec4 - Communications Engineering Design: de La Salle Lipa College of Information Technology and EngineeringDocument8 pagesEcelec4 - Communications Engineering Design: de La Salle Lipa College of Information Technology and EngineeringmimiPas encore d'évaluation
- Objective: Practice The Methods of Hydrological Statisctics (Normal Distribution), Using Mean Annual Discharge DataDocument8 pagesObjective: Practice The Methods of Hydrological Statisctics (Normal Distribution), Using Mean Annual Discharge DataRamon VerdugaPas encore d'évaluation
- Partida #Especificaciones Medidas: #Veces Longitud PuntoDocument3 pagesPartida #Especificaciones Medidas: #Veces Longitud PuntoEder Aroon Capcha JuradoPas encore d'évaluation
- UntitledDocument15 pagesUntitledLucy EFPas encore d'évaluation
- Follow The Instructions.: Team Rower 1 Rower 2 TotalDocument3 pagesFollow The Instructions.: Team Rower 1 Rower 2 TotalPUTRIPas encore d'évaluation
- BG Map Reading SkillsDocument25 pagesBG Map Reading SkillsMairtingriffinPas encore d'évaluation
- Senator in Congress: Democratic PCT TotalsDocument4 pagesSenator in Congress: Democratic PCT TotalsRobert FucciPas encore d'évaluation
- Light Assessment Readings GMPDocument2 pagesLight Assessment Readings GMPloveson glariyansPas encore d'évaluation
- Human Resource Management ProjectDocument16 pagesHuman Resource Management Projectksmk651Pas encore d'évaluation
- Department of Computer Science and Engineering: Class Time Table of 7cse-1 For Odd Semester (2021-22)Document6 pagesDepartment of Computer Science and Engineering: Class Time Table of 7cse-1 For Odd Semester (2021-22)Sai AmbatiPas encore d'évaluation
- 10th English Guide - Unit 1 by Loyola PublicationsDocument89 pages10th English Guide - Unit 1 by Loyola PublicationsGopinathan M67% (3)
- Gann Ttta-2Document48 pagesGann Ttta-2sUPRAKASH75% (4)
- Ducu Sep Dec CatDocument5 pagesDucu Sep Dec Catkelvin jakesPas encore d'évaluation
- Sri Chaitanya IIT Academy., India.: Key SheetDocument17 pagesSri Chaitanya IIT Academy., India.: Key SheetGaurav GamerPas encore d'évaluation
- Q Factor in Forest ManagementDocument4 pagesQ Factor in Forest ManagementBidya NathPas encore d'évaluation
- Class 5 Final WorkbookDocument142 pagesClass 5 Final Workbookhardik trivedi100% (1)
- Class 5 Final WorkbookDocument142 pagesClass 5 Final Workbookhardik trivediPas encore d'évaluation
- 2015 MST GRADE 2 Mathematics Objective-TypeTestDocument11 pages2015 MST GRADE 2 Mathematics Objective-TypeTestDesmond Dujon HenryPas encore d'évaluation
- Internal Combustion Engine - Assignment 1Document10 pagesInternal Combustion Engine - Assignment 1Azeem ZulqaharPas encore d'évaluation
- Modul PBD Mate THN 5 DLPDocument74 pagesModul PBD Mate THN 5 DLPNathan AravinPas encore d'évaluation
- MCA Stability BookletDocument19 pagesMCA Stability BookletBharatiyulam0% (1)
- Standalone Financial Results, Limited Review Report For December 31, 2016 (Result)Document4 pagesStandalone Financial Results, Limited Review Report For December 31, 2016 (Result)Shyam SunderPas encore d'évaluation
- (Linguisticae Investigationes. Supplementa - 6.) Theodore M. Lightner - Introduction To English Derivational Morphology-John BenjaminsDocument574 pages(Linguisticae Investigationes. Supplementa - 6.) Theodore M. Lightner - Introduction To English Derivational Morphology-John BenjaminsResearch methodology K18Pas encore d'évaluation
- Reasoning 7Document1 pageReasoning 7Venkat RamPas encore d'évaluation
- Supo Ys5Document38 pagesSupo Ys5saninnnaPas encore d'évaluation
- Dimension Hook113Document1 pageDimension Hook113SAMUEL PANDAPOTAN MARBUNPas encore d'évaluation
- Physics U5 Turning QP Jan 2004Document14 pagesPhysics U5 Turning QP Jan 2004Ali WanPas encore d'évaluation
- 3find: or NDXDocument3 pages3find: or NDXMuskan MangarajPas encore d'évaluation
- Make Sure Read: REAI) "Tffi:E'Of, (lOWINGDocument24 pagesMake Sure Read: REAI) "Tffi:E'Of, (lOWINGAnna Del Rey ValtersenPas encore d'évaluation
- Kalajdzievski, Sasho An Illustrated Introduction To Topology andDocument481 pagesKalajdzievski, Sasho An Illustrated Introduction To Topology andMa Em AcPas encore d'évaluation
- AS 4.1.2 AlkanesDocument14 pagesAS 4.1.2 AlkanesLexy Lawton-BoweringPas encore d'évaluation
- Crack DI-LRDocument41 pagesCrack DI-LRabhishek pathakPas encore d'évaluation
- Assignment 8 ISE 500: Groups CountDocument22 pagesAssignment 8 ISE 500: Groups CountAnanth RameshPas encore d'évaluation
- Practice Questions Lecture 11-15Document13 pagesPractice Questions Lecture 11-15Umer HafeezPas encore d'évaluation
- Pin Joint en PDFDocument1 pagePin Joint en PDFCicPas encore d'évaluation
- CH 2 PDFDocument85 pagesCH 2 PDFSajidPas encore d'évaluation
- M4110 Leakage Reactance InterfaceDocument2 pagesM4110 Leakage Reactance InterfaceGuru MishraPas encore d'évaluation
- Detailed Lesson Plan (Lit)Document19 pagesDetailed Lesson Plan (Lit)Shan QueentalPas encore d'évaluation
- Birth Trauma and Post Traumatic Stress Disorder The Importance of Risk and ResilienceDocument5 pagesBirth Trauma and Post Traumatic Stress Disorder The Importance of Risk and ResilienceMsRockPhantomPas encore d'évaluation
- OMN-TRA-SSR-OETC-Course Workbook 2daysDocument55 pagesOMN-TRA-SSR-OETC-Course Workbook 2daysMANIKANDAN NARAYANASAMYPas encore d'évaluation
- IELTS Letter Writing TipsDocument7 pagesIELTS Letter Writing Tipsarif salmanPas encore d'évaluation
- Medha Servo Drives Written Exam Pattern Given by KV Sai KIshore (BVRIT-2005-09-ECE)Document2 pagesMedha Servo Drives Written Exam Pattern Given by KV Sai KIshore (BVRIT-2005-09-ECE)Varaprasad KanugulaPas encore d'évaluation
- Highway Journal Feb 2023Document52 pagesHighway Journal Feb 2023ShaileshRastogiPas encore d'évaluation
- Basic Concept of ProbabilityDocument12 pagesBasic Concept of Probability8wc9sncvpwPas encore d'évaluation
- Read The Dialogue Below and Answer The Following QuestionDocument5 pagesRead The Dialogue Below and Answer The Following QuestionDavid GainesPas encore d'évaluation
- 3Document76 pages3Uday ShankarPas encore d'évaluation
- Ojt Evaluation Forms (Supervised Industry Training) SampleDocument5 pagesOjt Evaluation Forms (Supervised Industry Training) SampleJayJay Jimenez100% (3)
- Oss Kpi SummaryDocument7 pagesOss Kpi SummaryMohd FaizPas encore d'évaluation
- Agriculture Vision 2020Document10 pagesAgriculture Vision 20202113713 PRIYANKAPas encore d'évaluation
- Philippine Rural Development Project: South Luzon Cluster C Ommunication Resourc ES Management WorkshopDocument45 pagesPhilippine Rural Development Project: South Luzon Cluster C Ommunication Resourc ES Management WorkshopAlorn CatibogPas encore d'évaluation
- CNC Manuel de Maintenance 15i 150i ModelADocument526 pagesCNC Manuel de Maintenance 15i 150i ModelASebautomatismePas encore d'évaluation
- Analog Electronics-2 PDFDocument20 pagesAnalog Electronics-2 PDFAbhinav JangraPas encore d'évaluation
- History of JavaDocument3 pagesHistory of JavaKyra ParaisoPas encore d'évaluation
- Case StudyDocument15 pagesCase StudyChaitali moreyPas encore d'évaluation
- Tournament Rules and MechanicsDocument2 pagesTournament Rules and MechanicsMarkAllenPascualPas encore d'évaluation
- Successful School LeadershipDocument132 pagesSuccessful School LeadershipDabney90100% (2)
- Technical Textile and SustainabilityDocument5 pagesTechnical Textile and SustainabilityNaimul HasanPas encore d'évaluation
- CBLM - Interpreting Technical DrawingDocument18 pagesCBLM - Interpreting Technical DrawingGlenn F. Salandanan89% (45)
- Michael Ungar - Working With Children and Youth With Complex Needs - 20 Skills To Build Resilience-Routledge (2014)Document222 pagesMichael Ungar - Working With Children and Youth With Complex Needs - 20 Skills To Build Resilience-Routledge (2014)Sølve StoknesPas encore d'évaluation
- Muhammad Firdaus - A Review of Personal Data Protection Law in IndonesiaDocument7 pagesMuhammad Firdaus - A Review of Personal Data Protection Law in IndonesiaJordan Amadeus SoetowidjojoPas encore d'évaluation
- Revised PARA Element2 Radio LawsDocument81 pagesRevised PARA Element2 Radio LawsAurora Pelagio Vallejos100% (4)
- 009 Attached-1 NAVFAC P-445 Construction Quality Management PDFDocument194 pages009 Attached-1 NAVFAC P-445 Construction Quality Management PDFSor sopanharithPas encore d'évaluation
- American J of Comm Psychol - 2023 - Palmer - Looted Artifacts and Museums Perpetuation of Imperialism and RacismDocument9 pagesAmerican J of Comm Psychol - 2023 - Palmer - Looted Artifacts and Museums Perpetuation of Imperialism and RacismeyeohneeduhPas encore d'évaluation
- Iot Based Garbage and Street Light Monitoring SystemDocument3 pagesIot Based Garbage and Street Light Monitoring SystemHarini VenkatPas encore d'évaluation