Vous aimerez peut-être aussi
- No More ProcrastinationDocument1 pageNo More ProcrastinationMA W.Pas encore d'évaluation
- Agatha Christie and The Golden Age of Detective Fiction PrintableDocument23 pagesAgatha Christie and The Golden Age of Detective Fiction PrintableMA W.100% (1)
- The Unbearable Lightness of Being SynopsisDocument2 pagesThe Unbearable Lightness of Being SynopsisMA W.Pas encore d'évaluation
- How To Use AiDocument1 pageHow To Use AiMA W.Pas encore d'évaluation
- Are You Happy With Your Body?Document2 pagesAre You Happy With Your Body?MA W.Pas encore d'évaluation
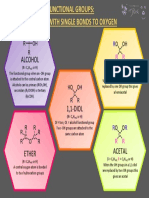
- Organic Chemistry Functional GroupsDocument1 pageOrganic Chemistry Functional GroupsMA W.Pas encore d'évaluation
- 6 Types of Ielts Tasks 1 and 2Document9 pages6 Types of Ielts Tasks 1 and 2MA W.Pas encore d'évaluation
- What Did You Do This SummerDocument1 pageWhat Did You Do This SummerMA W.Pas encore d'évaluation
- Street Haunting Virginia WoolfDocument10 pagesStreet Haunting Virginia WoolfMA W.100% (1)
- Feeling Words Worksheet GDocument2 pagesFeeling Words Worksheet GMA W.Pas encore d'évaluation
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- How To Avoid Common Errors in Writing Scientific ManuscriptsDocument6 pagesHow To Avoid Common Errors in Writing Scientific ManuscriptssoulimanPas encore d'évaluation
- Bright Futures Guidelines For Health Supervision of Infants, Children, and Adolescents 4TH PDFDocument890 pagesBright Futures Guidelines For Health Supervision of Infants, Children, and Adolescents 4TH PDFEssa Smj100% (12)
- IHI Patient Family Experience of Hospital Care White Paper 2011Document34 pagesIHI Patient Family Experience of Hospital Care White Paper 2011Sorina VoicuPas encore d'évaluation
- Establishing Therapeutic RelationshipsDocument62 pagesEstablishing Therapeutic RelationshipsDavid FuenzalidaPas encore d'évaluation
- An Evidence-Based Reference: Diseases and Conditions in DentistryDocument1 pageAn Evidence-Based Reference: Diseases and Conditions in DentistryGabriel LazarPas encore d'évaluation
- M2 - Social Responsibility and Decision MakingDocument6 pagesM2 - Social Responsibility and Decision MakingHONEY LYN GUTIERREZPas encore d'évaluation
- ჟურნალი სრულიDocument113 pagesჟურნალი სრულიTengiz VerulavaPas encore d'évaluation
- CFMHN Standards 1Document19 pagesCFMHN Standards 1Aliyah Adek RahmahPas encore d'évaluation
- Diana M. Bailey - Research For The Health Professional-F. A. Davis Company (2014)Document304 pagesDiana M. Bailey - Research For The Health Professional-F. A. Davis Company (2014)jorge torres50% (2)
- Health Information SystemDocument14 pagesHealth Information SystemRoberto MendozaPas encore d'évaluation
- Essentials of Organizational Behavior Stephen P. Robbins & Timothy A. Judge 17 EditionDocument26 pagesEssentials of Organizational Behavior Stephen P. Robbins & Timothy A. Judge 17 EditionAnikaPas encore d'évaluation
- History Patient - Co.ukDocument14 pagesHistory Patient - Co.ukiuytrerPas encore d'évaluation
- Peny Jantung PDFDocument18 pagesPeny Jantung PDFErna Jovem GluberryPas encore d'évaluation
- Knowledge and Innovation Action Plan 2014-2018Document7 pagesKnowledge and Innovation Action Plan 2014-2018Mohamed IrshaPas encore d'évaluation
- Agricultural Water ManagementDocument13 pagesAgricultural Water ManagementMuletaPas encore d'évaluation
- Effectiveness of Antimicrobial Photodynamic Therapy in The Periodontis Systematic ReviewDocument42 pagesEffectiveness of Antimicrobial Photodynamic Therapy in The Periodontis Systematic ReviewreizkayPas encore d'évaluation
- Test Bank Professional Issues in Nursing Challenges and Opportunities 3rd Edition HustonDocument36 pagesTest Bank Professional Issues in Nursing Challenges and Opportunities 3rd Edition Hustonnayword.mermaidnr1v0a100% (34)
- Work Base Assessment in Anesthesia For Postgraduate ResidentsDocument4 pagesWork Base Assessment in Anesthesia For Postgraduate ResidentsMJSPPas encore d'évaluation
- Notification & IMM SGR (2019)Document49 pagesNotification & IMM SGR (2019)QandeelPas encore d'évaluation
- Action Research in HealthcareDocument13 pagesAction Research in HealthcareIan HughesPas encore d'évaluation
- Ati RN 2016 Mental HealthDocument6 pagesAti RN 2016 Mental HealthStan Tan0% (1)
- Book Review: Social Marketing: Improving The Quality of Life. Philip KotlerDocument1 pageBook Review: Social Marketing: Improving The Quality of Life. Philip Kotlerbentarigan77Pas encore d'évaluation
- Dementia Core Skills Education and Training FrameworkDocument95 pagesDementia Core Skills Education and Training FrameworkMirela Georgiana SchiopuPas encore d'évaluation
- SumberDocument15 pagesSumberWildaPas encore d'évaluation
- Character Count Limit: 350: AOTA Evidence-Based Practice Project CAP Worksheet Evidence Exchange Last Updated: April 2018Document4 pagesCharacter Count Limit: 350: AOTA Evidence-Based Practice Project CAP Worksheet Evidence Exchange Last Updated: April 2018Marina EPas encore d'évaluation
- Ati RN 2016 FundamentalsDocument6 pagesAti RN 2016 FundamentalsStan TanPas encore d'évaluation
- Shoulder Guidelines AdhesiveCapsulitis JOSPT May 2013 PDFDocument31 pagesShoulder Guidelines AdhesiveCapsulitis JOSPT May 2013 PDFElliya RosyidaPas encore d'évaluation
- 10 1001@jama 2019 0554 PDFDocument15 pages10 1001@jama 2019 0554 PDFFaisal Reza AdiebPas encore d'évaluation
- Empowering Communities: Unveiling The Impact of Community Health Nurses Workload and Contributions To Public Well-BeingDocument9 pagesEmpowering Communities: Unveiling The Impact of Community Health Nurses Workload and Contributions To Public Well-BeingeditorbijnrPas encore d'évaluation