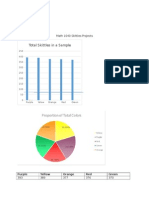
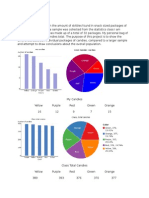
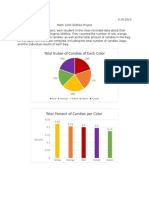
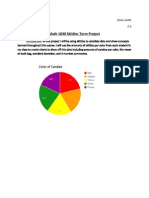
Vous aimerez peut-être aussi
- Skittles Statistics ProjectDocument9 pagesSkittles Statistics Projectapi-325825295Pas encore d'évaluation
- EportfolioDocument8 pagesEportfolioapi-242211470Pas encore d'évaluation
- Skittles Proyect Part 5Document7 pagesSkittles Proyect Part 5api-509398997Pas encore d'évaluation
- EportfolioDocument12 pagesEportfolioapi-251934892Pas encore d'évaluation
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081Pas encore d'évaluation
- Team Project Part 6 Final ReportDocument8 pagesTeam Project Part 6 Final Reportapi-316794103Pas encore d'évaluation
- Math 1040Document5 pagesMath 1040api-534403229Pas encore d'évaluation
- The Rainbow ReportDocument11 pagesThe Rainbow Reportapi-316991888Pas encore d'évaluation
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832Pas encore d'évaluation
- SkittleDocument6 pagesSkittleapi-378470372Pas encore d'évaluation
- Term Project SkittlesDocument4 pagesTerm Project Skittlesapi-356003029Pas encore d'évaluation
- Skittles Project Part 2 2019Document3 pagesSkittles Project Part 2 2019api-325020845Pas encore d'évaluation
- Skittles ProDocument9 pagesSkittles Proapi-241124972Pas encore d'évaluation
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218Pas encore d'évaluation
- Croot Part6 EportfolioDocument16 pagesCroot Part6 Eportfolioapi-276896975Pas encore d'évaluation
- Math 1040 Skittles Term ProjectDocument4 pagesMath 1040 Skittles Term Projectapi-253137548Pas encore d'évaluation
- Stats ProjectDocument14 pagesStats Projectapi-302666758Pas encore d'évaluation
- Final Math ProjectDocument7 pagesFinal Math Projectapi-316775963Pas encore d'évaluation
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-317626858Pas encore d'évaluation
- Math 1030 Skittles Term ProjectDocument8 pagesMath 1030 Skittles Term Projectapi-340538273Pas encore d'évaluation
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765Pas encore d'évaluation
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849Pas encore d'évaluation
- Skittles ReportDocument5 pagesSkittles Reportapi-242736484Pas encore d'évaluation
- Final ProjectDocument9 pagesFinal Projectapi-262329757Pas encore d'évaluation
- Skittles ProjectDocument5 pagesSkittles Projectapi-441660843Pas encore d'évaluation
- The Full Skittles ProjectDocument6 pagesThe Full Skittles Projectapi-340271527100% (1)
- Math ProfileDocument9 pagesMath Profileapi-454376679Pas encore d'évaluation
- Group Project Part 6-E PortfolioDocument10 pagesGroup Project Part 6-E Portfolioapi-253208467Pas encore d'évaluation
- Term Project - EportfolioDocument7 pagesTerm Project - Eportfolioapi-251981709Pas encore d'évaluation
- The Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer QuestionsDocument7 pagesThe Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer Questionsapi-438148756Pas encore d'évaluation
- Math 1040 Final ProjectDocument3 pagesMath 1040 Final Projectapi-285380759Pas encore d'évaluation
- StatsfinalprojectDocument7 pagesStatsfinalprojectapi-325102852Pas encore d'évaluation
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085Pas encore d'évaluation
- Math 1040 Term ProjectDocument7 pagesMath 1040 Term Projectapi-340188424Pas encore d'évaluation
- Skittles Project CompleteDocument8 pagesSkittles Project Completeapi-312645878Pas encore d'évaluation
- Final ProjectDocument6 pagesFinal Projectapi-283261340Pas encore d'évaluation
- Skittles ReportDocument9 pagesSkittles Reportapi-311878992Pas encore d'évaluation
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685Pas encore d'évaluation
- 1040 Skittles ProjectDocument4 pages1040 Skittles Projectapi-279941094Pas encore d'évaluation
- Math 1040 ProjectDocument8 pagesMath 1040 Projectapi-388517702Pas encore d'évaluation
- Skittles Project 1Document7 pagesSkittles Project 1api-299868669100% (2)
- SkittlesDocument7 pagesSkittlesapi-244615173Pas encore d'évaluation
- 1040 ProjectDocument4 pages1040 Projectapi-279808770Pas encore d'évaluation
- Skittles Project 2Document5 pagesSkittles Project 2api-355504623Pas encore d'évaluation
- Project FinalDocument10 pagesProject Finalapi-300399896Pas encore d'évaluation
- SkittlesDocument5 pagesSkittlesapi-249778667Pas encore d'évaluation
- Group Project #1 - SkittlesDocument9 pagesGroup Project #1 - Skittlesapi-245266056Pas encore d'évaluation
- Skittles Project 2Document10 pagesSkittles Project 2api-316655135Pas encore d'évaluation
- Skittles Project Part 7Document4 pagesSkittles Project Part 7api-454435360Pas encore d'évaluation
- Skittles Individual 2-DennisonDocument1 pageSkittles Individual 2-Dennisonapi-232854257Pas encore d'évaluation
- Skittles ProjectDocument17 pagesSkittles Projectapi-359548770Pas encore d'évaluation
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872Pas encore d'évaluation
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849Pas encore d'évaluation
- Math Skittles Term Project-1Document6 pagesMath Skittles Term Project-1api-241771020Pas encore d'évaluation
- Skittles ProjectDocument13 pagesSkittles Projectapi-306339227Pas encore d'évaluation
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278Pas encore d'évaluation
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396Pas encore d'évaluation
- Final Stats ProjectDocument8 pagesFinal Stats Projectapi-238717717100% (2)
- Skittles Final ProjectDocument5 pagesSkittles Final Projectapi-251571777Pas encore d'évaluation
- Venture Mathematics Worksheets: Bk. A: Algebra and Arithmetic: Blackline masters for higher ability classes aged 11-16D'EverandVenture Mathematics Worksheets: Bk. A: Algebra and Arithmetic: Blackline masters for higher ability classes aged 11-16Pas encore d'évaluation
- CinematographyDocument6 pagesCinematographyapi-457501806Pas encore d'évaluation
- Banned BooksDocument7 pagesBanned Booksapi-457501806Pas encore d'évaluation
- Report 3Document5 pagesReport 3api-457501806Pas encore d'évaluation
- Myth People With Ocd Are Very Organized 1 1Document5 pagesMyth People With Ocd Are Very Organized 1 1api-457501806Pas encore d'évaluation
- Final Reflection - Hlac 1025Document3 pagesFinal Reflection - Hlac 1025api-457501806Pas encore d'évaluation
- Decisional Balance Worksheet-3Document1 pageDecisional Balance Worksheet-3api-457501806Pas encore d'évaluation
- Myth People With Ocd Are Very OrganizedDocument11 pagesMyth People With Ocd Are Very Organizedapi-457501806Pas encore d'évaluation
- Hum 1100 e Portfolio Post Reflective Worksheet 1Document4 pagesHum 1100 e Portfolio Post Reflective Worksheet 1api-457501806Pas encore d'évaluation
- Art 1010 - Found Art Project 2Document7 pagesArt 1010 - Found Art Project 2api-457501806Pas encore d'évaluation
- Fictional Character 3Document4 pagesFictional Character 3api-457501806Pas encore d'évaluation
- Client Profile - Ryan and Lindsay Mcmullin-2Document3 pagesClient Profile - Ryan and Lindsay Mcmullin-2api-457501806Pas encore d'évaluation
- Document 27Document2 pagesDocument 27api-457501806Pas encore d'évaluation
- The Water CycleDocument6 pagesThe Water Cycleapi-457501806Pas encore d'évaluation
- Final Project - Reflection 1 1Document3 pagesFinal Project - Reflection 1 1api-457501806Pas encore d'évaluation
- Signature AssignmentDocument2 pagesSignature Assignmentapi-457501806Pas encore d'évaluation
- Report 3 3Document5 pagesReport 3 3api-457501806Pas encore d'évaluation
- Document20 1Document2 pagesDocument20 1api-457501806Pas encore d'évaluation
- Document21 1Document3 pagesDocument21 1api-457501806Pas encore d'évaluation
- Skittles Project Part 2Document3 pagesSkittles Project Part 2api-457501806Pas encore d'évaluation
- Document 19Document10 pagesDocument 19api-457501806Pas encore d'évaluation
- Untitled Document 3Document10 pagesUntitled Document 3api-457501806Pas encore d'évaluation
- Reflection 1Document2 pagesReflection 1api-457501806Pas encore d'évaluation
- Self Assessment 1 3Document3 pagesSelf Assessment 1 3api-457501806Pas encore d'évaluation
- CHM 556 Experiment 5Document12 pagesCHM 556 Experiment 5Amar Safwan100% (1)
- KUKA Sim 30 Installation enDocument49 pagesKUKA Sim 30 Installation enRégis Naydo0% (1)
- Lab 2 Centrifugal PumpsDocument29 pagesLab 2 Centrifugal PumpslalelaPas encore d'évaluation
- Timetable Saturday 31 Dec 2022Document1 pageTimetable Saturday 31 Dec 2022Khan AadiPas encore d'évaluation
- Insight: Mini C-Arm Imaging System Technical Reference ManualDocument21 pagesInsight: Mini C-Arm Imaging System Technical Reference ManualTyrone CoxPas encore d'évaluation
- Bandura Et Al.Document16 pagesBandura Et Al.Siddhant JhawarPas encore d'évaluation
- If This Paper Were in Chinese, Would Chinese People Understand the Title? An Exploration of Whorfian Claims About the Chinese Language If This Paper Were in Chinese, Would Chinese People Understand the Title? An Exploration of Whorfian Claims About the Chinese Language If This PaperDocument69 pagesIf This Paper Were in Chinese, Would Chinese People Understand the Title? An Exploration of Whorfian Claims About the Chinese Language If This Paper Were in Chinese, Would Chinese People Understand the Title? An Exploration of Whorfian Claims About the Chinese Language If This PaperDavid MoserPas encore d'évaluation
- Multistage Amplifier Frequency ResponseDocument29 pagesMultistage Amplifier Frequency ResponseMuhammad HafizPas encore d'évaluation
- HPLC CalculatorDocument13 pagesHPLC CalculatorRamy AzizPas encore d'évaluation
- Pipesim Model Management Program: For Reservoir, Production, and Process ModelingDocument2 pagesPipesim Model Management Program: For Reservoir, Production, and Process ModelingMauricio AlvaradoPas encore d'évaluation
- Mos PDFDocument194 pagesMos PDFChoon Ewe LimPas encore d'évaluation
- Elasticity and Its Applications: For Use With Mankiw and Taylor, Economics 4 Edition 9781473725331 © CENGAGE EMEA 2017Document39 pagesElasticity and Its Applications: For Use With Mankiw and Taylor, Economics 4 Edition 9781473725331 © CENGAGE EMEA 2017Joana AgraPas encore d'évaluation
- Install and Set Up Heavy Duty Plate Cutting MachineDocument14 pagesInstall and Set Up Heavy Duty Plate Cutting MachineJorn StejnPas encore d'évaluation
- Spreader BeamDocument7 pagesSpreader BeamAnonymous sfkedkymPas encore d'évaluation
- On Handwritten Digit RecognitionDocument15 pagesOn Handwritten Digit RecognitionAnkit Upadhyay100% (1)
- Experiment No 02Document5 pagesExperiment No 02Farhan AliPas encore d'évaluation
- MB Truck Explorer Manual GB PDFDocument117 pagesMB Truck Explorer Manual GB PDFاحمد ابو عبداللهPas encore d'évaluation
- TR01B - Muhammad Aditya Prana Yoga - Analisa Listrik Chapter8.3Document3 pagesTR01B - Muhammad Aditya Prana Yoga - Analisa Listrik Chapter8.3AzeedPas encore d'évaluation
- Vendor Information Vishay BLH Handbook TC0013 Solutions For Process Weighing and Force Measurement Electronic Weigh SystemsDocument59 pagesVendor Information Vishay BLH Handbook TC0013 Solutions For Process Weighing and Force Measurement Electronic Weigh SystemsAndrew JacksonPas encore d'évaluation
- Backing Up BitLocker and TPM Recovery Information To AD DSDocument14 pagesBacking Up BitLocker and TPM Recovery Information To AD DSnoPas encore d'évaluation
- F-500 Encapsulator TechnologyDocument6 pagesF-500 Encapsulator TechnologyBdSulianoPas encore d'évaluation
- 5-Unsymmetrical Fault AnalysisDocument5 pages5-Unsymmetrical Fault Analysisvirenpandya0% (1)
- Pages 296-298 Module 6 ReviewDocument4 pagesPages 296-298 Module 6 Reviewapi-332361871Pas encore d'évaluation
- Module 4Document24 pagesModule 4MARIE ANN DIAMAPas encore d'évaluation
- Materials and Techniques Used For The "Vienna Moamin": Multianalytical Investigation of A Book About Hunting With Falcons From The Thirteenth CenturyDocument17 pagesMaterials and Techniques Used For The "Vienna Moamin": Multianalytical Investigation of A Book About Hunting With Falcons From The Thirteenth CenturyAirish FPas encore d'évaluation
- Mathematical Induction, Peano Axioms, and Properties of Addition of Non-Negative IntegersDocument13 pagesMathematical Induction, Peano Axioms, and Properties of Addition of Non-Negative IntegersMarius PaunescuPas encore d'évaluation
- MPLS QAsDocument6 pagesMPLS QAsLaxman Shrestha100% (1)
- Quantitative Reasoning: Factors, HCF & LCM, FactorialsDocument2 pagesQuantitative Reasoning: Factors, HCF & LCM, FactorialsNaman JainPas encore d'évaluation
- Check List For Overall Piping Plot PlanDocument3 pagesCheck List For Overall Piping Plot PlankamleshyadavmoneyPas encore d'évaluation
- Touareg FL Dimensions PDFDocument2 pagesTouareg FL Dimensions PDFZeljko PekicPas encore d'évaluation