Vous aimerez peut-être aussi
- Computer Architecture - tutorial 2 TUTOR COPYDocument5 pagesComputer Architecture - tutorial 2 TUTOR COPYHalim KorogluPas encore d'évaluation
- Numerical: Central Processing UnitDocument28 pagesNumerical: Central Processing UnityounisPas encore d'évaluation
- Tute SampleDocument4 pagesTute SamplePrateek KharePas encore d'évaluation
- Computer Architecture - 09 - Review For MidtermDocument13 pagesComputer Architecture - 09 - Review For Midtermdlwodbs031Pas encore d'évaluation
- Commentaries and Answers Exercises: New FE TextbookDocument71 pagesCommentaries and Answers Exercises: New FE Textbookwadah biz50% (2)
- B I T & S, P - K. K. B G C: Irla Nstitute of Echnology Cience Ilani Irla OA AmpusDocument13 pagesB I T & S, P - K. K. B G C: Irla Nstitute of Echnology Cience Ilani Irla OA Ampusnasa stickPas encore d'évaluation
- Compsci Explanations PDFDocument24 pagesCompsci Explanations PDFs3ct0r 10Pas encore d'évaluation
- L09 - Floating-Point & LogicDocument59 pagesL09 - Floating-Point & Logicitheachtholly1227Pas encore d'évaluation
- ES Unit 3 Solutions for 8051 Microcontroller QuestionsDocument11 pagesES Unit 3 Solutions for 8051 Microcontroller QuestionsNiraj UpadhayayaPas encore d'évaluation
- Exam Computer Systems/Computer Architecture and OrganisationDocument10 pagesExam Computer Systems/Computer Architecture and OrganisationTanawut WatthanapreechagidPas encore d'évaluation
- MATLAB programs for filters and additionDocument6 pagesMATLAB programs for filters and additionVinit GoyalPas encore d'évaluation
- HDL Design Laboratory Report 1Document19 pagesHDL Design Laboratory Report 1Dhruva ShrivastavaPas encore d'évaluation
- Solution Dseclzg524 05-07-2020 Ec3rDocument7 pagesSolution Dseclzg524 05-07-2020 Ec3rsrirams007Pas encore d'évaluation
- Computer Application AssignmentDocument5 pagesComputer Application AssignmentPrayas SarkarPas encore d'évaluation
- Mic CT-2Document11 pagesMic CT-2manaskadganchi2006kPas encore d'évaluation
- Cse3666 MT1S F12Document5 pagesCse3666 MT1S F12dimpal_3221Pas encore d'évaluation
- Activity No. 1 Adc and Dac Iii. Practice Problems: Ece 515 FL Digital Signal Processing LaboratoryDocument5 pagesActivity No. 1 Adc and Dac Iii. Practice Problems: Ece 515 FL Digital Signal Processing LaboratoryVernadine DulayPas encore d'évaluation
- 10-27-Noted-Practice Midterm With SolutionDocument5 pages10-27-Noted-Practice Midterm With SolutionK163726 Syed Ashar AliPas encore d'évaluation
- COE301 Final Solution 162Document10 pagesCOE301 Final Solution 162Karim IbrahimPas encore d'évaluation
- Simplex Method - 18BCN7125Document21 pagesSimplex Method - 18BCN7125vamsi krishPas encore d'évaluation
- Zoom/Online Final - question Q1TITLE: Online Final Q1 PipeliningDocument3 pagesZoom/Online Final - question Q1TITLE: Online Final Q1 PipeliningMuhammad Zahid iqbalPas encore d'évaluation
- IIR FILTERING EXPERIMENTSDocument13 pagesIIR FILTERING EXPERIMENTSPhuong PhamPas encore d'évaluation
- Final Lecture Chapter 3 Part 2 3 Additional Notes For Assembly LanguageDocument31 pagesFinal Lecture Chapter 3 Part 2 3 Additional Notes For Assembly LanguageAman BazePas encore d'évaluation
- Chebyshev LC Filter Design: R 1 G G GDocument7 pagesChebyshev LC Filter Design: R 1 G G GSudipta GhoshPas encore d'évaluation
- Computer Arch TestDocument8 pagesComputer Arch TestCricket Live StreamingPas encore d'évaluation
- Practice Final SolnDocument17 pagesPractice Final SolnJimmie J MshumbusiPas encore d'évaluation
- UntitledDocument5 pagesUntitlediijjgwelPas encore d'évaluation
- Size and optimization of "Hello worldDocument7 pagesSize and optimization of "Hello worldThivin AnandhPas encore d'évaluation
- 60-265-01 Computer Architecture and Digital Design: Midterm Examination # 2Document9 pages60-265-01 Computer Architecture and Digital Design: Midterm Examination # 2Akhil SinghPas encore d'évaluation
- CA Question PaperDocument9 pagesCA Question PaperVaibhav BajpaiPas encore d'évaluation
- Lab 5Document11 pagesLab 5Waleed Bashir KotlaPas encore d'évaluation
- CsaDocument8 pagesCsaMANOJ KUMAWATPas encore d'évaluation
- Computer Organization and Architecture Solutions ExplainedDocument20 pagesComputer Organization and Architecture Solutions Explainedkitana_sect100% (1)
- Solutions To Chapter 1 Exercises: Table 1: Performance Growth RatesDocument5 pagesSolutions To Chapter 1 Exercises: Table 1: Performance Growth RatesKanaan BhissyPas encore d'évaluation
- Architecture 2020Document10 pagesArchitecture 2020honey arguellesPas encore d'évaluation
- 15IF11 Multicore E PDFDocument14 pages15IF11 Multicore E PDFRakesh VenkatesanPas encore d'évaluation
- COA SolutionsDocument81 pagesCOA SolutionsHARSHDEEP TELANGPas encore d'évaluation
- Be - Computer Engineering - Semester 4 - 2018 - May - Computer Organization and Architecture CbcgsDocument22 pagesBe - Computer Engineering - Semester 4 - 2018 - May - Computer Organization and Architecture CbcgsYash RajPas encore d'évaluation
- CST131 Tutorial2Document7 pagesCST131 Tutorial2Lim ScPas encore d'évaluation
- VLSI & ASIC Digital Design Interview QuestionsDocument6 pagesVLSI & ASIC Digital Design Interview QuestionsRupesh Kumar DuttaPas encore d'évaluation
- Wavelet Supplemental: Xiaojun QiDocument16 pagesWavelet Supplemental: Xiaojun QidivasagarPas encore d'évaluation
- COA - Practice SetDocument3 pagesCOA - Practice SetArJitYaDavPas encore d'évaluation
- Expt 3 Transfer FunctionDocument4 pagesExpt 3 Transfer FunctionAngelo Legarda De CastroPas encore d'évaluation
- Lecture Notes WorkingsDocument135 pagesLecture Notes WorkingschanduPas encore d'évaluation
- Chapter 10 Arithmetic Ckts Presentation.VDocument109 pagesChapter 10 Arithmetic Ckts Presentation.VsirishaPas encore d'évaluation
- EE 483 Digital Control HomeworkDocument1 pageEE 483 Digital Control Homeworkరవితేజ నంబూరుPas encore d'évaluation
- MPHS EXAM 13/06/16 - Prof. Luca Benini Name: Nmat:: Load 4'b1000Document7 pagesMPHS EXAM 13/06/16 - Prof. Luca Benini Name: Nmat:: Load 4'b1000Sudhir Borra100% (1)
- COE301 T232 Midterm Exam Key LatestDocument15 pagesCOE301 T232 Midterm Exam Key Latestb9lah10Pas encore d'évaluation
- Chapter 5 - CO - BIM - IIIDocument7 pagesChapter 5 - CO - BIM - IIIAnkit ShresthaPas encore d'évaluation
- Cs CheatDocument2 pagesCs Cheatpushpitasaha2025Pas encore d'évaluation
- CEG 2131 - Fall 2003 - FinalDocument14 pagesCEG 2131 - Fall 2003 - FinalAmin DhouibPas encore d'évaluation
- Computational Lab in Physics: Monte Carlo IntegrationDocument13 pagesComputational Lab in Physics: Monte Carlo Integrationbenefit187Pas encore d'évaluation
- Practical Set 2 Code Solutions and OutputDocument4 pagesPractical Set 2 Code Solutions and Outputnency ahirPas encore d'évaluation
- Pgtrbcomputerscience 2Document100 pagesPgtrbcomputerscience 2Desperado Manogaran MPas encore d'évaluation
- ANSWER: A/D Converter Explanation:: No Explanation Is Available For This Question!Document26 pagesANSWER: A/D Converter Explanation:: No Explanation Is Available For This Question!Numan KhanPas encore d'évaluation
- PgtrbcomputerscienceIN PART 3Document91 pagesPgtrbcomputerscienceIN PART 3jothimanicsePas encore d'évaluation
- Educational Resources for Technical AssistanceDocument11 pagesEducational Resources for Technical AssistanceTHE PAINKILLERSPas encore d'évaluation
- Os MCQDocument21 pagesOs MCQgurusodhiiPas encore d'évaluation
- Binary Arithmetic Sign RepresentationDocument29 pagesBinary Arithmetic Sign RepresentationUriti Venkata Naga KishorePas encore d'évaluation
- Ce 23456789753Document8 pagesCe 23456789753Uriti Venkata Naga KishorePas encore d'évaluation
- GATE 2019 General Aptitude (GA) Set-9 QuestionsDocument19 pagesGATE 2019 General Aptitude (GA) Set-9 QuestionsStructure departmentPas encore d'évaluation
- Bits g553 Real Time SystemsDocument2 pagesBits g553 Real Time SystemsUriti Venkata Naga KishorePas encore d'évaluation
- CS 2019Document16 pagesCS 2019S M Shamim শামীমPas encore d'évaluation
- GATE 2019 General Aptitude (GA) Set-9 QuestionsDocument19 pagesGATE 2019 General Aptitude (GA) Set-9 QuestionsStructure departmentPas encore d'évaluation
- Rel AlgDocument4 pagesRel AlgVinod VinuPas encore d'évaluation
- Q. 1 - Q. 5 Carry One Mark Each.: GATE 2019 General Aptitude (GA) Set-7Document19 pagesQ. 1 - Q. 5 Carry One Mark Each.: GATE 2019 General Aptitude (GA) Set-7InduSaran AttadaPas encore d'évaluation
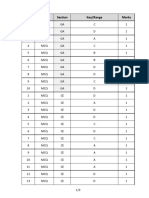
- Q.No. Type Section Key/Range MarksDocument3 pagesQ.No. Type Section Key/Range MarksUriti Venkata Naga KishorePas encore d'évaluation
- Bits g553 Real Time SystemsDocument2 pagesBits g553 Real Time SystemsUriti Venkata Naga KishorePas encore d'évaluation
- Binary Arithmetic Sign RepresentationDocument29 pagesBinary Arithmetic Sign RepresentationUriti Venkata Naga KishorePas encore d'évaluation
- CE2 Key PublishedDocument3 pagesCE2 Key PublishedUriti Venkata Naga KishorePas encore d'évaluation
- CS Key PublishedDocument3 pagesCS Key PublishedUriti Venkata Naga KishorePas encore d'évaluation
- CG QP MRDocument2 pagesCG QP MRUriti Venkata Naga KishorePas encore d'évaluation
- Consider The Following NFA. Produce The Equivalent DFA. There Is No Need To Reduce The DFA Size. (2 + 5 7 Marks)Document2 pagesConsider The Following NFA. Produce The Equivalent DFA. There Is No Need To Reduce The DFA Size. (2 + 5 7 Marks)Uriti Venkata Naga KishorePas encore d'évaluation
- 2013 Coa CMDocument5 pages2013 Coa CMUriti Venkata Naga KishorePas encore d'évaluation
- Multiple Nomination Form CSDL NSDLDocument2 pagesMultiple Nomination Form CSDL NSDLarif420_999Pas encore d'évaluation
- Expanbar PVC: Centrally and Externally Placed PVC Waterstops. UsesDocument5 pagesExpanbar PVC: Centrally and Externally Placed PVC Waterstops. UsesZaid AhmedPas encore d'évaluation
- Thermodynamic Properties of Lithium Bromide Water Solutions at High TemperaturesDocument17 pagesThermodynamic Properties of Lithium Bromide Water Solutions at High TemperaturesAnonymous 7IKdlmPas encore d'évaluation
- Air Liquide BS 50-3-2,5Document1 pageAir Liquide BS 50-3-2,5kuraimundPas encore d'évaluation
- Victor Canete PDFDocument2 pagesVictor Canete PDFMelvi PeñasPas encore d'évaluation
- OS X ShortcutsDocument19 pagesOS X Shortcutsia_moheetPas encore d'évaluation
- ROR coding standards guide for clean codeDocument2 pagesROR coding standards guide for clean codeHarish KashyapPas encore d'évaluation
- Amman Master PlanDocument205 pagesAmman Master Planomaroyoun100% (9)
- Vlsi DesignDocument2 pagesVlsi DesignXXXPas encore d'évaluation
- Toggle Ram - CSS Ram Valve SetupDocument6 pagesToggle Ram - CSS Ram Valve Setupsassine khouryPas encore d'évaluation
- Curva TD12F - 1000GPM@130PSI - 2950RPMDocument2 pagesCurva TD12F - 1000GPM@130PSI - 2950RPMHenry Hurtado ZeladaPas encore d'évaluation
- CNH-FIAT-NEW HOLLAND Tractor Components CatalogueDocument523 pagesCNH-FIAT-NEW HOLLAND Tractor Components Catalogueomni_parts100% (2)
- Design and Fabrication of Pedal Powered HacksawDocument22 pagesDesign and Fabrication of Pedal Powered HacksawAshish Jindal100% (3)
- Amines Plant PresentationDocument22 pagesAmines Plant Presentationirsanti dewiPas encore d'évaluation
- NFL NANGAL Urea Plant Process & SpecsDocument35 pagesNFL NANGAL Urea Plant Process & SpecsAkhil AklPas encore d'évaluation
- 5 Things To Know About DB2 Native EncryptionDocument4 pages5 Things To Know About DB2 Native EncryptionAnup MukhopadhyayPas encore d'évaluation
- Mini Esplit LGDocument76 pagesMini Esplit LGLEASUCPas encore d'évaluation
- ResistanceDocument72 pagesResistanceParisDelaCruzPas encore d'évaluation
- Sirena Policial AmericanaDocument9 pagesSirena Policial AmericanaromarioPas encore d'évaluation
- Model 3260 Constant Speed Mixer ManualDocument31 pagesModel 3260 Constant Speed Mixer ManualNi MaPas encore d'évaluation
- Reasons For Using Star Connected Armature Winding in AlternatorDocument13 pagesReasons For Using Star Connected Armature Winding in AlternatorAdisu ZinabuPas encore d'évaluation
- Computer Mcqs1'Document34 pagesComputer Mcqs1'Imran SheikhPas encore d'évaluation
- UDN6118ADocument8 pagesUDN6118AkizonzPas encore d'évaluation
- Power King Tractor Owners ManualDocument54 pagesPower King Tractor Owners ManualBryan Potter100% (2)
- Root Mean Square ValueDocument2 pagesRoot Mean Square ValueProximo DvPas encore d'évaluation
- En 10270 1 2001 Filo Per MolleDocument26 pagesEn 10270 1 2001 Filo Per MolleGizem AkelPas encore d'évaluation
- Aluminide and Silicide Diffusion Coatings by Pack Cementation For Nb-Ti-AlalloyDocument12 pagesAluminide and Silicide Diffusion Coatings by Pack Cementation For Nb-Ti-Alalloybrunoab89Pas encore d'évaluation
- Age of Empires 2Document1 pageAge of Empires 2tulsiPas encore d'évaluation
- Low Pass Filter ActiveDocument8 pagesLow Pass Filter ActiveTioRamadhanPas encore d'évaluation
- Blastmax 50 EngDocument96 pagesBlastmax 50 EngIslenaGarciaPas encore d'évaluation
- Trantech BrochureDocument4 pagesTrantech BrochureOmar Reinoso TigrePas encore d'évaluation