Vous aimerez peut-être aussi
- PianoDocument148 pagesPianoElisabeth Tölke100% (11)
- PianoDocument148 pagesPianoElisabeth Tölke100% (11)
- Rockschool Popular Music Theory Syllabus 2015 18Document33 pagesRockschool Popular Music Theory Syllabus 2015 18Archit AnandPas encore d'évaluation
- Vocal Warm-Up Practices and PerceptionsDocument10 pagesVocal Warm-Up Practices and PerceptionsLoreto SaavedraPas encore d'évaluation
- Cálice - Partitura PDFDocument5 pagesCálice - Partitura PDFzharboPas encore d'évaluation
- Anshel y Kipper - The Influence of Group Singing On Trust and Cooperation PDFDocument11 pagesAnshel y Kipper - The Influence of Group Singing On Trust and Cooperation PDFGomo RaPas encore d'évaluation
- Watson, K. E. (2010) - Charting Future Directions For Research in Jazz Pedagogy - Implications of The Literature. Music Education Research, 12 (4), 383-393.Document12 pagesWatson, K. E. (2010) - Charting Future Directions For Research in Jazz Pedagogy - Implications of The Literature. Music Education Research, 12 (4), 383-393.goni56509Pas encore d'évaluation
- Assessment in Music Education: Theory, Practice, and Policy: Selected Papers from the Eighth International Symposium on Assessment in Music EducationD'EverandAssessment in Music Education: Theory, Practice, and Policy: Selected Papers from the Eighth International Symposium on Assessment in Music EducationPas encore d'évaluation
- Science: Quarter 4 - Module 1: Locating Places Using Coordinate SystemDocument28 pagesScience: Quarter 4 - Module 1: Locating Places Using Coordinate SystemJaken Mack100% (5)
- Impact of Music To The Academic PerformanceDocument45 pagesImpact of Music To The Academic PerformanceKevin Dazo93% (14)
- Shaft Alignment: Your Photo HereDocument75 pagesShaft Alignment: Your Photo HereMahmoud Elghandour0% (1)
- Best Ia SampleDocument35 pagesBest Ia SampleKatja67% (3)
- From Navier Stokes To Black Scholes - Numerical Methods in Computational FinanceDocument13 pagesFrom Navier Stokes To Black Scholes - Numerical Methods in Computational FinanceTrader CatPas encore d'évaluation
- Grade9 Physics PDFDocument2 pagesGrade9 Physics PDFRajPas encore d'évaluation
- Principles of Gas Chromatography 2Document12 pagesPrinciples of Gas Chromatography 2Enanahmed EnanPas encore d'évaluation
- Johnson 2011Document29 pagesJohnson 2011danial rosliPas encore d'évaluation
- EX - NO:1a Data Definition Languages (DDL) Commands of Base Tables and ViewsDocument44 pagesEX - NO:1a Data Definition Languages (DDL) Commands of Base Tables and Viewslalit thakur100% (1)
- University of California Press: Info/about/policies/terms - JSPDocument23 pagesUniversity of California Press: Info/about/policies/terms - JSPdeleongabrielPas encore d'évaluation
- Boucher and Ryan - 2011 - Performance Stress and The Very Young MusicianDocument18 pagesBoucher and Ryan - 2011 - Performance Stress and The Very Young MusiciankehanPas encore d'évaluation
- Maynard 2006 The Role of Repetition in The Practice Sessions of Artist Teachers and Their StudentsDocument13 pagesMaynard 2006 The Role of Repetition in The Practice Sessions of Artist Teachers and Their StudentsTiago Teixeira Leal100% (1)
- Factors and Abilities Influencing Sightreading Skill in MusicDocument17 pagesFactors and Abilities Influencing Sightreading Skill in MusicTeresaPeraltaCalvilloPas encore d'évaluation
- The Development of A Guitar Performance Rating Scale Using A Facet-Factorial ApproachDocument15 pagesThe Development of A Guitar Performance Rating Scale Using A Facet-Factorial ApproachBrendan FrankPas encore d'évaluation
- Self-Efficacy As A Predictor of Musical Performance Quality: Laura Ritchie Aaron WilliamonDocument7 pagesSelf-Efficacy As A Predictor of Musical Performance Quality: Laura Ritchie Aaron WilliamonCatarina C.Pas encore d'évaluation
- Amerjpsyc 123 2 0199Document11 pagesAmerjpsyc 123 2 0199Gabriel LeónPas encore d'évaluation
- Cooksey 1977Document16 pagesCooksey 1977Sofia GatoPas encore d'évaluation
- Swanwick 00Document9 pagesSwanwick 00Sónia FerreiraPas encore d'évaluation
- Aspects of The High School Music Program and Their Relationship With The College Marching Band ExperienceDocument35 pagesAspects of The High School Music Program and Their Relationship With The College Marching Band ExperienceFlavia RstPas encore d'évaluation
- 5.GishVocal Warm-Up Practices and Perceptions.A Pilot SurveyDocument10 pages5.GishVocal Warm-Up Practices and Perceptions.A Pilot SurveyBartomeu GuiscafrePas encore d'évaluation
- Music Performance Anxiety DissertationDocument8 pagesMusic Performance Anxiety DissertationWhatShouldIWriteMyPaperAboutUK100% (1)
- MacPeherson Factors and Abilities Influencing SightrDocument16 pagesMacPeherson Factors and Abilities Influencing SightrLau_mdiPas encore d'évaluation
- Musicology Dissertation TopicsDocument5 pagesMusicology Dissertation TopicsPaperWriterServiceCanada100% (1)
- Gregory Springer - The Role of AccompanimentDocument19 pagesGregory Springer - The Role of AccompanimentPedroPas encore d'évaluation
- Literature Review About MusicDocument5 pagesLiterature Review About Musicc5t0jsyn100% (1)
- Article 3Document8 pagesArticle 3api-609434428Pas encore d'évaluation
- Kent 1291041505Document233 pagesKent 1291041505Bopit KhaohanPas encore d'évaluation
- The Whole Is Not Different From Its PartsDocument17 pagesThe Whole Is Not Different From Its PartsFarlley DerzePas encore d'évaluation
- This Content Downloaded From 85.244.160.80 On Fri, 03 Mar 2023 19:58:14 UTCDocument33 pagesThis Content Downloaded From 85.244.160.80 On Fri, 03 Mar 2023 19:58:14 UTCMariana VilafrancaPas encore d'évaluation
- T18 Gol00Document68 pagesT18 Gol00Daniel ColliPas encore d'évaluation
- Ritchie and Williamon 2010Document17 pagesRitchie and Williamon 2010Inês Sacadura100% (1)
- 2000 Butzlaff PDFDocument13 pages2000 Butzlaff PDFAdrian Christian LeePas encore d'évaluation
- Scandinavian J Psychology - 2003 - Colley - Gender Bias in The Evaluation of New Age MusicDocument7 pagesScandinavian J Psychology - 2003 - Colley - Gender Bias in The Evaluation of New Age MusicA WPas encore d'évaluation
- Garofalo and Whaley, COMPARISON OF THE UNIT STUDY AND TRADITIONAL APPROACHES FOR TEACHING MUSIC THROUGH SCHOOL BAND PERFORMANCEDocument7 pagesGarofalo and Whaley, COMPARISON OF THE UNIT STUDY AND TRADITIONAL APPROACHES FOR TEACHING MUSIC THROUGH SCHOOL BAND PERFORMANCEJamesPas encore d'évaluation
- Recruitment and Retention in The Applied Music Studio: A Critical Examination of Curricular and Institutional Demands - College Music SymposiumDocument27 pagesRecruitment and Retention in The Applied Music Studio: A Critical Examination of Curricular and Institutional Demands - College Music SymposiumDouglas MarkPas encore d'évaluation
- Gatien8 2Document26 pagesGatien8 2Owzic Music SchoolPas encore d'évaluation
- MT in School SettingsDocument23 pagesMT in School SettingsIsabella PestanaPas encore d'évaluation
- Effect of Audience On Music Performance AnxietyDocument18 pagesEffect of Audience On Music Performance AnxietyjaniceabbyPas encore d'évaluation
- Music As An Unconditioned Stimulus: Positive and Negative Effects of Country Music On Implicit Attitudes, Explicit Attitudes, and Brand ChoiceDocument17 pagesMusic As An Unconditioned Stimulus: Positive and Negative Effects of Country Music On Implicit Attitudes, Explicit Attitudes, and Brand ChoiceChris BurroughsPas encore d'évaluation
- The Effects of Listening To Music During QuizzesDocument19 pagesThe Effects of Listening To Music During QuizzesCaryll Mae MagnoPas encore d'évaluation
- Quinones - Response To Devaney Et AlDocument2 pagesQuinones - Response To Devaney Et AlJulio QuinonesPas encore d'évaluation
- ArticleDocument5 pagesArticleBIG DUCKPas encore d'évaluation
- Effect of Music On Cognitive TasksDocument9 pagesEffect of Music On Cognitive Tasksjaneypauig25Pas encore d'évaluation
- Music Reading MeasurementDocument8 pagesMusic Reading MeasurementMarina VlachakiPas encore d'évaluation
- Accompaniment EffectsDocument16 pagesAccompaniment EffectsPaolo FratelloPas encore d'évaluation
- Council For Research in Music Education, University of Illinois Press Bulletin of The Council For Research in Music EducationDocument5 pagesCouncil For Research in Music Education, University of Illinois Press Bulletin of The Council For Research in Music Education李依Pas encore d'évaluation
- Fisher ImpactsVoiceChange 2014Document15 pagesFisher ImpactsVoiceChange 2014stephenieleevos1Pas encore d'évaluation
- 005ISAME5 2016kang InstrumentSelection FinalDocument12 pages005ISAME5 2016kang InstrumentSelection FinalkehanPas encore d'évaluation
- A Comparison of The Ratings of Black, Hispanic, and White Childrens' Academic Performance, Amos N. WilsonDocument138 pagesA Comparison of The Ratings of Black, Hispanic, and White Childrens' Academic Performance, Amos N. WilsonMariDjata5Pas encore d'évaluation
- Julius OralHistoryMusic 1980Document10 pagesJulius OralHistoryMusic 1980shantanumajeePas encore d'évaluation
- Measuring Socioeconomic Status: Assessment July 2002Document13 pagesMeasuring Socioeconomic Status: Assessment July 2002MagalyfloresgPas encore d'évaluation
- Examining Sixth-Grade Students - Music Agency Through Rhythm CompDocument94 pagesExamining Sixth-Grade Students - Music Agency Through Rhythm CompSARA CHELLIPas encore d'évaluation
- Development and Validation of A Clarinet Performance AdjudicationDocument11 pagesDevelopment and Validation of A Clarinet Performance Adjudicationapi-199307272Pas encore d'évaluation
- Davis 1998Document14 pagesDavis 1998Sofia GatoPas encore d'évaluation
- A Conceptual Framework For Understanding Musical Performance AnxietyDocument26 pagesA Conceptual Framework For Understanding Musical Performance AnxietylauraPas encore d'évaluation
- TechnicalreportDocument4 pagesTechnicalreportapi-360875816Pas encore d'évaluation
- Mcpherson2006 Self-Efficacy and Music PerformanceDocument16 pagesMcpherson2006 Self-Efficacy and Music PerformanceInês Sacadura100% (1)
- Final Research ProjectDocument9 pagesFinal Research Projectapi-534592269Pas encore d'évaluation
- Effect of Music Genre To The Shor1 - Finale Paper For PanelDocument82 pagesEffect of Music Genre To The Shor1 - Finale Paper For PanelCrystalen MelanaPas encore d'évaluation
- Students' Attributions of Sources of Influence OnDocument17 pagesStudents' Attributions of Sources of Influence OnJohn david PeeblesPas encore d'évaluation
- Final ThesisDocument32 pagesFinal ThesisPetallana KeroPas encore d'évaluation
- Chapter 6Document26 pagesChapter 6api-59037670Pas encore d'évaluation
- Education Journal of Research in MusicDocument16 pagesEducation Journal of Research in MusiczharboPas encore d'évaluation
- Hojes CelsoCintra 2017Document6 pagesHojes CelsoCintra 2017zharboPas encore d'évaluation
- Cálice - PartituraDocument5 pagesCálice - PartiturazharboPas encore d'évaluation
- Verlagsverzeichnis 2008 English PDFDocument120 pagesVerlagsverzeichnis 2008 English PDFzharbo100% (1)
- Bipolar Junction Transistor ModelsDocument21 pagesBipolar Junction Transistor ModelsecedepttPas encore d'évaluation
- Effect of Salinity On Proteins in Some Wheat CultivarsDocument9 pagesEffect of Salinity On Proteins in Some Wheat Cultivarsray m deraniaPas encore d'évaluation
- Tutorial Book 0.4Document27 pagesTutorial Book 0.4TonyandAnthonyPas encore d'évaluation
- Iohexol USP42NF37Document5 pagesIohexol USP42NF37John Alejandro Restrepo GarciaPas encore d'évaluation
- Slides Prepared by John S. Loucks St. Edward's University: 1 Slide © 2003 Thomson/South-WesternDocument34 pagesSlides Prepared by John S. Loucks St. Edward's University: 1 Slide © 2003 Thomson/South-WesternHRish BhimberPas encore d'évaluation
- Computer Science Admissions Test: Avengers CollegeDocument4 pagesComputer Science Admissions Test: Avengers CollegeSaad Bin AzimPas encore d'évaluation
- Pure Component VLE in Terms of Fugacity: CHEE 311 1Document8 pagesPure Component VLE in Terms of Fugacity: CHEE 311 1scienziatoPas encore d'évaluation
- Astar - 23b.trace - XZ Bimodal Next - Line Next - Line Next - Line Next - Line Drrip 1coreDocument4 pagesAstar - 23b.trace - XZ Bimodal Next - Line Next - Line Next - Line Next - Line Drrip 1corevaibhav sonewanePas encore d'évaluation
- Enatel FlexiMAX24a500Kw PDFDocument2 pagesEnatel FlexiMAX24a500Kw PDFJosé Angel PinedaPas encore d'évaluation
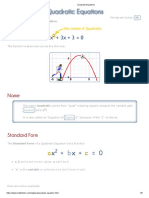
- Quadratic Equation - MATH IS FUNDocument8 pagesQuadratic Equation - MATH IS FUNChanchan LebumfacilPas encore d'évaluation
- The Natureofthe ElectronDocument18 pagesThe Natureofthe ElectronSidhant KumarPas encore d'évaluation
- Atmel 0038Document1 pageAtmel 0038namerPas encore d'évaluation
- Chapter 9 and 10Document18 pagesChapter 9 and 10billPas encore d'évaluation
- Seam Strength of Corrugated Plate With High Strength SteelDocument15 pagesSeam Strength of Corrugated Plate With High Strength SteelMariano SalcedoPas encore d'évaluation
- Pro ESEDocument2 pagesPro ESEquadhirababilPas encore d'évaluation
- Low Reynolds NumberDocument10 pagesLow Reynolds NumberMOHAMMEDPas encore d'évaluation
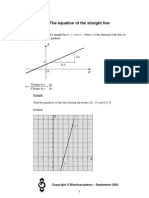
- The Equation of The Straight Line: y MX CDocument6 pagesThe Equation of The Straight Line: y MX CMarc SugruePas encore d'évaluation
- Data Sheet - enDocument2 pagesData Sheet - enrodriggoguedesPas encore d'évaluation
- Dw384 Spare Part ListDocument5 pagesDw384 Spare Part ListLuis Manuel Montoya RiveraPas encore d'évaluation
- SDS-PAGE PrincipleDocument2 pagesSDS-PAGE PrincipledhashrathPas encore d'évaluation
- Zipato MQTTCloudDocument34 pagesZipato MQTTClouddensasPas encore d'évaluation
- GGDocument8 pagesGGGaurav SharmaPas encore d'évaluation
- DSI - MPS® Transfer System Compact Trainer I4.0 - EN - DID1089 (Screen)Document2 pagesDSI - MPS® Transfer System Compact Trainer I4.0 - EN - DID1089 (Screen)mhafizanPas encore d'évaluation