Vous aimerez peut-être aussi
- How to Find Inter-Groups Differences Using Spss/Excel/Web Tools in Common Experimental Designs: Book TwoD'EverandHow to Find Inter-Groups Differences Using Spss/Excel/Web Tools in Common Experimental Designs: Book TwoPas encore d'évaluation
- Post Hoc TestsDocument18 pagesPost Hoc TestsDean GoldenbbPas encore d'évaluation
- 1.5.3 Orth Contrasts and Means Sep Tests (Hale) - Supp Reading 2Document18 pages1.5.3 Orth Contrasts and Means Sep Tests (Hale) - Supp Reading 2Teflon SlimPas encore d'évaluation
- Mean Separation StatisticsDocument15 pagesMean Separation StatisticsIsaias Prestes100% (1)
- Sample Sizes for Clinical, Laboratory and Epidemiology StudiesD'EverandSample Sizes for Clinical, Laboratory and Epidemiology StudiesPas encore d'évaluation
- Chapter 9. Multiple Comparisons and Trends Among Treatment MeansDocument21 pagesChapter 9. Multiple Comparisons and Trends Among Treatment MeanskassuPas encore d'évaluation
- Lesson 3.5: Post Hoc AnalysisDocument24 pagesLesson 3.5: Post Hoc AnalysisMar Joseph MarañonPas encore d'évaluation
- Unit 8 Infrential Statistics AnovaDocument10 pagesUnit 8 Infrential Statistics AnovaHafizAhmadPas encore d'évaluation
- Paired T Test PDFDocument22 pagesPaired T Test PDFHimanshu SharmaPas encore d'évaluation
- One-Way Analysis of Variance in SPSSDocument27 pagesOne-Way Analysis of Variance in SPSSMichail100% (4)
- Chapter 13: Introduction To Analysis of VarianceDocument26 pagesChapter 13: Introduction To Analysis of VarianceAlia Al ZghoulPas encore d'évaluation
- Topic 10. ANOVA Models For Random and Mixed Effects References: ST&DT: Topic 7.5 p.152-153, Topic 9.9 P. 225-227, Topic 15.5 379-384Document16 pagesTopic 10. ANOVA Models For Random and Mixed Effects References: ST&DT: Topic 7.5 p.152-153, Topic 9.9 P. 225-227, Topic 15.5 379-384maleticjPas encore d'évaluation
- Chapter 5Document75 pagesChapter 5gebreslassie gereziherPas encore d'évaluation
- Post HocDocument5 pagesPost HocTracy NadinePas encore d'évaluation
- One-way ANOVA tutorial: Analyze arthritis pain relief dataDocument7 pagesOne-way ANOVA tutorial: Analyze arthritis pain relief dataraden hilmi100% (1)
- STAT 700 Homework 5Document10 pagesSTAT 700 Homework 5ngyncloudPas encore d'évaluation
- Chapter 12 ANOVADocument25 pagesChapter 12 ANOVAMadison HartfieldPas encore d'évaluation
- Imeko WC 2012 TC21 O10Document5 pagesImeko WC 2012 TC21 O10mcastillogzPas encore d'évaluation
- ANALYSIS OF VARIANCE: TESTING MEAN AND VARIANCE DIFFERENCESDocument4 pagesANALYSIS OF VARIANCE: TESTING MEAN AND VARIANCE DIFFERENCESPoonam NaiduPas encore d'évaluation
- Cai, Sun - Unknown - Part I Large-Scale Multiple Testing Chapter 1 A Compound Decision-Theoretic Approach To Large-Scale Multiple TesDocument43 pagesCai, Sun - Unknown - Part I Large-Scale Multiple Testing Chapter 1 A Compound Decision-Theoretic Approach To Large-Scale Multiple TesYoungHee GoPas encore d'évaluation
- Newsom Psy 521 Post Hoc TestsDocument4 pagesNewsom Psy 521 Post Hoc Testsinayati fitriyahPas encore d'évaluation
- Paired T-Test: A Project Report OnDocument19 pagesPaired T-Test: A Project Report OnTarun kumarPas encore d'évaluation
- Anova Figures PDFDocument9 pagesAnova Figures PDFEva Ruth MedilloPas encore d'évaluation
- Data TransfermationDocument16 pagesData TransfermationBhuvanaPas encore d'évaluation
- 2012 Mean ComparisonDocument35 pages2012 Mean Comparison3rlangPas encore d'évaluation
- Minitab One-way ANOVA TutorialDocument11 pagesMinitab One-way ANOVA TutorialAzri ZanuriPas encore d'évaluation
- 04 Simple AnovaDocument9 pages04 Simple AnovaShashi KapoorPas encore d'évaluation
- 11 BS201 Prob and Stat - Ch5Document17 pages11 BS201 Prob and Stat - Ch5knmounika2395Pas encore d'évaluation
- Glossary StatisticsDocument6 pagesGlossary Statisticssilviac.microsysPas encore d'évaluation
- Student's T TestDocument7 pagesStudent's T TestLedesma Ray100% (1)
- Superiority, Equivalence, and Non-Inferiority TrialsDocument5 pagesSuperiority, Equivalence, and Non-Inferiority TrialscrystalmodelPas encore d'évaluation
- DsagfDocument5 pagesDsagf53melmelPas encore d'évaluation
- 4 Multiple ComparisonDocument11 pages4 Multiple Comparisonluis dPas encore d'évaluation
- Session 10Document10 pagesSession 10Osman Gani TalukderPas encore d'évaluation
- Do Not Use The Rules For Expected MS On ST&D Page 381Document18 pagesDo Not Use The Rules For Expected MS On ST&D Page 381Teflon SlimPas encore d'évaluation
- DATA SCIENCE INTERVIEW PREPARATIONDocument27 pagesDATA SCIENCE INTERVIEW PREPARATIONSatyavaraprasad BallaPas encore d'évaluation
- Mb0050 SLM Unit12Document22 pagesMb0050 SLM Unit12Margabandhu NarasimhanPas encore d'évaluation
- ANOVA Guide for ResearchersDocument16 pagesANOVA Guide for ResearchersTanvi GuptaPas encore d'évaluation
- T Test ExpamlesDocument7 pagesT Test ExpamlesSaleh Muhammed BareachPas encore d'évaluation
- Multiple Comparisons in ANOVA - (Howitt-Kramer)Document9 pagesMultiple Comparisons in ANOVA - (Howitt-Kramer)Simone MontuoriPas encore d'évaluation
- 12-Multiple Comparison ProcedureDocument12 pages12-Multiple Comparison ProcedurerahadianakbarPas encore d'évaluation
- Benjamini y Yekutieli 2001 The Control of The False Discovery Rate in Multiple Testing Under DependencyDocument24 pagesBenjamini y Yekutieli 2001 The Control of The False Discovery Rate in Multiple Testing Under DependencyCarlos AndradePas encore d'évaluation
- Module 3Document98 pagesModule 3mesfinPas encore d'évaluation
- Handout 1 Experiment DesignDocument15 pagesHandout 1 Experiment DesignFleming MwijukyePas encore d'évaluation
- Controlling The False Discovery RateDocument13 pagesControlling The False Discovery RateCassia LmtPas encore d'évaluation
- Application of Least Significance DifferenceDocument4 pagesApplication of Least Significance DifferenceBoobalan BalaPas encore d'évaluation
- Experimental DesignDocument15 pagesExperimental DesignElson Antony PaulPas encore d'évaluation
- ANOVA AND T-TESTS EXPLAINEDDocument29 pagesANOVA AND T-TESTS EXPLAINEDmounika kPas encore d'évaluation
- Research Methodology StatisticsDocument36 pagesResearch Methodology StatisticsRajashekar GatlaPas encore d'évaluation
- Statistical analysis conclusions interpretationDocument3 pagesStatistical analysis conclusions interpretationErrol de los SantosPas encore d'évaluation
- Multiple T Tests or ANOVA (Analysis of Variance) ?: Nural Bekiro LuDocument2 pagesMultiple T Tests or ANOVA (Analysis of Variance) ?: Nural Bekiro LuMohamed NaeimPas encore d'évaluation
- Pilot-Pivotal Trials For Average BioequivalenceDocument11 pagesPilot-Pivotal Trials For Average BioequivalenceIoana AntonesiPas encore d'évaluation
- Pseudoreplication - Part 1Document6 pagesPseudoreplication - Part 1CINDY NATHALIA GARCIA AGUDELOPas encore d'évaluation
- Common Statistical TestsDocument12 pagesCommon Statistical TestsshanumanuranuPas encore d'évaluation
- Warrens2016 Article AComparisonOfReliabilityCoeffi PDFDocument14 pagesWarrens2016 Article AComparisonOfReliabilityCoeffi PDFLanaBecPas encore d'évaluation
- Warrens2016 Article AComparisonOfReliabilityCoeffi PDFDocument14 pagesWarrens2016 Article AComparisonOfReliabilityCoeffi PDFLanaBecPas encore d'évaluation
- Chi Square ReportDocument35 pagesChi Square ReportJohn Henry ValenciaPas encore d'évaluation
- AnnovaDocument4 pagesAnnovabharticPas encore d'évaluation
- Interploidy Hybridization in Sympatric Zones The FormationDocument14 pagesInterploidy Hybridization in Sympatric Zones The FormationTeflon SlimPas encore d'évaluation
- Table 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Document1 pageTable 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Teflon SlimPas encore d'évaluation
- Gen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableDocument5 pagesGen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableTeflon SlimPas encore d'évaluation
- R Codes Germinate Seed Data AnalysisDocument1 pageR Codes Germinate Seed Data AnalysisTeflon SlimPas encore d'évaluation
- Table 2Document1 pageTable 2Teflon SlimPas encore d'évaluation
- Combining Ability of Extra-Early White Inbreds Final DraftDocument57 pagesCombining Ability of Extra-Early White Inbreds Final DraftTeflon SlimPas encore d'évaluation
- Ideal Tester STR-BA1057Document7 pagesIdeal Tester STR-BA1057Teflon SlimPas encore d'évaluation
- Regional Hybrid TrialDocument8 pagesRegional Hybrid TrialTeflon SlimPas encore d'évaluation
- File Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunDocument48 pagesFile Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunTeflon SlimPas encore d'évaluation
- Combined Diallel-W DataDocument703 pagesCombined Diallel-W DataTeflon SlimPas encore d'évaluation
- Results FileDocument159 pagesResults FileTeflon SlimPas encore d'évaluation
- Inbred Lines Evaluated in Nigeria, 2011.: MaizeDocument1 pageInbred Lines Evaluated in Nigeria, 2011.: MaizeTeflon SlimPas encore d'évaluation
- Hybrid Maize Yield and Trait DataDocument46 pagesHybrid Maize Yield and Trait DataTeflon SlimPas encore d'évaluation
- GGE Biplot of GCA Stability AnalysisDocument24 pagesGGE Biplot of GCA Stability AnalysisTeflon SlimPas encore d'évaluation
- Obs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldDocument292 pagesObs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldTeflon SlimPas encore d'évaluation
- Additive NonadditiveDocument1 pageAdditive NonadditiveTeflon SlimPas encore d'évaluation
- Figure 5Document1 pageFigure 5Teflon SlimPas encore d'évaluation
- SCA Effects of Grain Yield in Maize HybridsDocument1 pageSCA Effects of Grain Yield in Maize HybridsTeflon SlimPas encore d'évaluation
- Figure 2Document1 pageFigure 2Teflon SlimPas encore d'évaluation
- Figure 4Document1 pageFigure 4Teflon SlimPas encore d'évaluation
- Responses To Reviewers' Comments CommentDocument4 pagesResponses To Reviewers' Comments CommentTeflon SlimPas encore d'évaluation
- Table 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationDocument1 pageTable 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationTeflon SlimPas encore d'évaluation
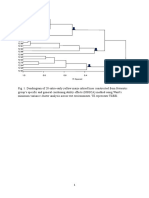
- Dendrogram of 20 extra-early yellow maize inbred lines constructed from HSGCA methodDocument1 pageDendrogram of 20 extra-early yellow maize inbred lines constructed from HSGCA methodTeflon SlimPas encore d'évaluation
- Figure 1Document1 pageFigure 1Teflon SlimPas encore d'évaluation
- Correlation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitDocument23 pagesCorrelation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitTeflon SlimPas encore d'évaluation
- Ba0727ik DataDocument12 pagesBa0727ik DataTeflon SlimPas encore d'évaluation
- Practical Session - Sample DataDocument21 pagesPractical Session - Sample DataTeflon SlimPas encore d'évaluation
- Mathews Paul G. Design of Experiments With MINITAB PDFDocument521 pagesMathews Paul G. Design of Experiments With MINITAB PDFFernando Chavarria100% (2)
- Data Analysis - Practical SessionDocument12 pagesData Analysis - Practical SessionTeflon SlimPas encore d'évaluation
- Anhu 12083Document8 pagesAnhu 12083Teflon SlimPas encore d'évaluation
- Scaling Data - Data Informed To Data Driven To Data Led - ReforgeDocument16 pagesScaling Data - Data Informed To Data Driven To Data Led - ReforgeEka PonkratovaPas encore d'évaluation
- Sanet - ST Hands On - Data.visualization - Wit. .Kevin - JollyDocument204 pagesSanet - ST Hands On - Data.visualization - Wit. .Kevin - JollyJohnny Rodrigues PereiraPas encore d'évaluation
- R Markdown Academic Manuscript TemplateDocument9 pagesR Markdown Academic Manuscript TemplatealbertopianoflautaPas encore d'évaluation
- One Sample ProceduresDocument5 pagesOne Sample Procedures张伟文Pas encore d'évaluation
- Research ProposalDocument34 pagesResearch ProposalSuchendra Dixit50% (2)
- Pendugaan Model Peramalan Harga Cabai Merah - OKE2Document12 pagesPendugaan Model Peramalan Harga Cabai Merah - OKE2Miftahul JanahPas encore d'évaluation
- Borehole Water and Sachet Water Production in Southeast NigeriaDocument105 pagesBorehole Water and Sachet Water Production in Southeast NigeriaFavour AtanePas encore d'évaluation
- Multiple Regression in Marketing Mix ModelsDocument10 pagesMultiple Regression in Marketing Mix ModelsJe Rome100% (1)
- Industrial Branding in Digital AgeDocument10 pagesIndustrial Branding in Digital AgeRichaPas encore d'évaluation
- Comparing Two Regression Slopes by Means of An ANCOVADocument4 pagesComparing Two Regression Slopes by Means of An ANCOVACatarina FerreiraPas encore d'évaluation
- Pls-Sem PDocument32 pagesPls-Sem PKwabena Owusu-AgyemangPas encore d'évaluation
- Dawn Wright: Dawn Wright:: T T T T T T T T T T TDocument3 pagesDawn Wright: Dawn Wright:: T T T T T T T T T T TRaine PiliinPas encore d'évaluation
- Yugantar Thakkur Resume 08 - 19 NPDocument2 pagesYugantar Thakkur Resume 08 - 19 NPpareekrachitPas encore d'évaluation
- Practical DWDMDocument32 pagesPractical DWDMDarshan MithaparaPas encore d'évaluation
- Study On The Alpha Generation and The Reflections of Its Behavior in The Organizational Environment PDFDocument11 pagesStudy On The Alpha Generation and The Reflections of Its Behavior in The Organizational Environment PDFAriane NotorioPas encore d'évaluation
- Effect of AIS on improving MSME food value chainsDocument36 pagesEffect of AIS on improving MSME food value chainsMarjorie Zara CustodioPas encore d'évaluation
- Econ 421 HW2 Winter 2015Document1 pageEcon 421 HW2 Winter 2015Yue MingPas encore d'évaluation
- Regression Stepwise (PIZZA)Document4 pagesRegression Stepwise (PIZZA)Jigar PriydarshiPas encore d'évaluation
- A Study On Training & Development in Kurnool: Yamaha Motors P.Chakrapani ReddyDocument7 pagesA Study On Training & Development in Kurnool: Yamaha Motors P.Chakrapani ReddybagyaPas encore d'évaluation
- Sales Data DashboardDocument37 pagesSales Data DashboardNaren Karthikeyan RPas encore d'évaluation
- Meeting Career Expectation: Can It Enhance Job Satisfaction of Generation Y?Document22 pagesMeeting Career Expectation: Can It Enhance Job Satisfaction of Generation Y?suzan wahbyPas encore d'évaluation
- Characterizing and Correcting For The Effect of Sensor Noise in The Dynamic Mode DecompositionDocument25 pagesCharacterizing and Correcting For The Effect of Sensor Noise in The Dynamic Mode DecompositionFABIANCHO2210Pas encore d'évaluation
- A Study On Badjaos: The Cases of Badjaos Residing in Novaliches, Quezon CityDocument38 pagesA Study On Badjaos: The Cases of Badjaos Residing in Novaliches, Quezon CityDonna LynnePas encore d'évaluation
- Research FinaleDocument55 pagesResearch FinalekatecamillebaranPas encore d'évaluation
- CORRELATION and REGRESSIONDocument19 pagesCORRELATION and REGRESSIONcharlene quiambaoPas encore d'évaluation
- Students' Potential Gains from Perception StudyDocument3 pagesStudents' Potential Gains from Perception StudyRovz GC BinPas encore d'évaluation
- Data Driven Decision Making Checklist TemplateDocument3 pagesData Driven Decision Making Checklist TemplateDhruvPas encore d'évaluation
- Bsafc4 PPT ch12Document30 pagesBsafc4 PPT ch12Niteesh KrishnaPas encore d'évaluation
- Rural - Urban Linkage ManualDocument100 pagesRural - Urban Linkage Manualonly exam100% (1)
- BRM Report WritingDocument17 pagesBRM Report WritingUdit Singh100% (1)
- A-level Maths Revision: Cheeky Revision ShortcutsD'EverandA-level Maths Revision: Cheeky Revision ShortcutsÉvaluation : 3.5 sur 5 étoiles3.5/5 (8)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormD'EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormÉvaluation : 5 sur 5 étoiles5/5 (5)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsD'EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsÉvaluation : 5 sur 5 étoiles5/5 (2)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeD'EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeÉvaluation : 4 sur 5 étoiles4/5 (2)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenD'EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenPas encore d'évaluation
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingD'EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingÉvaluation : 4.5 sur 5 étoiles4.5/5 (21)
- Calculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusD'EverandCalculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Psychology Behind Mathematics - The Comprehensive GuideD'EverandPsychology Behind Mathematics - The Comprehensive GuidePas encore d'évaluation
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathD'EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathÉvaluation : 5 sur 5 étoiles5/5 (1)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormD'EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormÉvaluation : 4.5 sur 5 étoiles4.5/5 (20)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)D'EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Pas encore d'évaluation
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsD'EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsÉvaluation : 3.5 sur 5 étoiles3.5/5 (9)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.D'EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Évaluation : 5 sur 5 étoiles5/5 (1)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldD'EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldÉvaluation : 3 sur 5 étoiles3/5 (79)
- Math Magic: How To Master Everyday Math ProblemsD'EverandMath Magic: How To Master Everyday Math ProblemsÉvaluation : 3.5 sur 5 étoiles3.5/5 (15)
- Mental Math Secrets - How To Be a Human CalculatorD'EverandMental Math Secrets - How To Be a Human CalculatorÉvaluation : 5 sur 5 étoiles5/5 (3)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceD'EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidencePas encore d'évaluation
- Classroom-Ready Number Talks for Kindergarten, First and Second Grade Teachers: 1,000 Interactive Activities and Strategies that Teach Number Sense and Math FactsD'EverandClassroom-Ready Number Talks for Kindergarten, First and Second Grade Teachers: 1,000 Interactive Activities and Strategies that Teach Number Sense and Math FactsPas encore d'évaluation
- Limitless Mind: Learn, Lead, and Live Without BarriersD'EverandLimitless Mind: Learn, Lead, and Live Without BarriersÉvaluation : 4 sur 5 étoiles4/5 (6)