
Vous aimerez peut-être aussi
- DATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABD'EverandDATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABPas encore d'évaluation
- Class Imbalance Problem in Data Mining: ReviewDocument5 pagesClass Imbalance Problem in Data Mining: ReviewijcsnPas encore d'évaluation
- A Robust and Efficient Real Time Network Intrusion Detection System Using Artificial Neural Network in Data MiningDocument10 pagesA Robust and Efficient Real Time Network Intrusion Detection System Using Artificial Neural Network in Data MiningijitcsPas encore d'évaluation
- Anomaly Detection 2Document8 pagesAnomaly Detection 2Aishwarya SinghPas encore d'évaluation
- 14 AprDocument9 pages14 AprSiva GaneshPas encore d'évaluation
- A Novel Datamining Based Approach For Remote Intrusion DetectionDocument6 pagesA Novel Datamining Based Approach For Remote Intrusion Detectionsurendiran123Pas encore d'évaluation
- Acm - Erna - Bahan - TranslateDocument4 pagesAcm - Erna - Bahan - TranslateAhmad gunawan WibisonoPas encore d'évaluation
- Anomaly Detection Via Eliminating Data Redundancy and Rectifying Data Error in Uncertain Data StreamsDocument18 pagesAnomaly Detection Via Eliminating Data Redundancy and Rectifying Data Error in Uncertain Data StreamsAnonymous OT4vepPas encore d'évaluation
- Introduction and Problem Area: Tentative Title - Detecting Interesting PatternsDocument7 pagesIntroduction and Problem Area: Tentative Title - Detecting Interesting PatternsAishwarya SinghPas encore d'évaluation
- Data Mining Techniques and ApplicationsDocument16 pagesData Mining Techniques and Applicationslokesh KoppanathiPas encore d'évaluation
- Phase IiDocument46 pagesPhase IiVeera LakshmiPas encore d'évaluation
- Spam Detection & Classification FinalDocument38 pagesSpam Detection & Classification FinalSiva ForeviewPas encore d'évaluation
- Database Intrusion Detection SystemDocument4 pagesDatabase Intrusion Detection SystemPARAM JOSHI0% (1)
- Review of Data Mining Classification Techniques: Shraddha Sharma & Ankita SaxenaDocument8 pagesReview of Data Mining Classification Techniques: Shraddha Sharma & Ankita SaxenaTJPRC PublicationsPas encore d'évaluation
- Network Anomaly Detection using Supervised LearningDocument11 pagesNetwork Anomaly Detection using Supervised LearningShahid AzeemPas encore d'évaluation
- Data Mining Chapter 1Document12 pagesData Mining Chapter 1Rony saha0% (1)
- Data Mining ImplementationDocument9 pagesData Mining Implementationakhmad faiz al khairiPas encore d'évaluation
- Icpcsi.2017.8392219Document6 pagesIcpcsi.2017.8392219Jamal AhmedPas encore d'évaluation
- Feature Subset Selection With Fast Algorithm ImplementationDocument5 pagesFeature Subset Selection With Fast Algorithm ImplementationseventhsensegroupPas encore d'évaluation
- Sensors: Conditional Variational Autoencoder For Prediction and Feature Recovery Applied To Intrusion Detection in IotDocument17 pagesSensors: Conditional Variational Autoencoder For Prediction and Feature Recovery Applied To Intrusion Detection in IotAnanya ParameswaranPas encore d'évaluation
- Data and Application Security Term Paper-1 Inference ProblemDocument10 pagesData and Application Security Term Paper-1 Inference ProblemdinneabhilashPas encore d'évaluation
- Intrusion Detection System (Ids) Development Using Tree - Based Machine Learning AlgorithmsDocument17 pagesIntrusion Detection System (Ids) Development Using Tree - Based Machine Learning AlgorithmsAIRCC - IJCNCPas encore d'évaluation
- Intrusion Detection System (IDS) Development Using Tree-Based Machine Learning AlgorithmsDocument17 pagesIntrusion Detection System (IDS) Development Using Tree-Based Machine Learning AlgorithmsAIRCC - IJCNCPas encore d'évaluation
- Intrusion Detection System IDS DevelopmeDocument17 pagesIntrusion Detection System IDS DevelopmeFabio Carciofi JuniorPas encore d'évaluation
- A Genetic Algorithm Based Elucidation For Improving Intrusion Detection Through Condensed Feature Set by KDD 99 Data SetDocument10 pagesA Genetic Algorithm Based Elucidation For Improving Intrusion Detection Through Condensed Feature Set by KDD 99 Data SetRavindra ReddyPas encore d'évaluation
- Detecting Network Anomalies with Stacking ModelsDocument54 pagesDetecting Network Anomalies with Stacking ModelsKesehoPas encore d'évaluation
- ms160400843 - Synopsis v2.3Document12 pagesms160400843 - Synopsis v2.3Shahid AzeemPas encore d'évaluation
- Hybrid Neural Network and Ensemble Intrusion DetectionDocument7 pagesHybrid Neural Network and Ensemble Intrusion DetectionMeenakshi AryaPas encore d'évaluation
- Performance Evaluation of Class BalancingDocument6 pagesPerformance Evaluation of Class Balancingjaskeerat singhPas encore d'évaluation
- Data PrepDocument5 pagesData PrepHimanshu ShrivastavaPas encore d'évaluation
- Paper-1 Significance of One-Class Classification in Outlier DetectionDocument11 pagesPaper-1 Significance of One-Class Classification in Outlier DetectionRachel WheelerPas encore d'évaluation
- Systematic Approach To Intrusion Evaluation Using The Rough Set Based ClassificationDocument6 pagesSystematic Approach To Intrusion Evaluation Using The Rough Set Based ClassificationRavindra ReddyPas encore d'évaluation
- D Esign A ND I Mplementation F or A Utomated N Etwork T Roubleshooting U Sing D Ata M IningDocument19 pagesD Esign A ND I Mplementation F or A Utomated N Etwork T Roubleshooting U Sing D Ata M IningLewis TorresPas encore d'évaluation
- Ijctt V3i2p104Document5 pagesIjctt V3i2p104surendiran123Pas encore d'évaluation
- ms160400843 - Synopsis v2.4Document11 pagesms160400843 - Synopsis v2.4Shahid AzeemPas encore d'évaluation
- Malware Detection Using Stacking Algorithm: Ganesh S. & Dr.V.B.KirubanandDocument4 pagesMalware Detection Using Stacking Algorithm: Ganesh S. & Dr.V.B.KirubanandTJPRC PublicationsPas encore d'évaluation
- Survey of Network Anomaly Detection Using Markov ChainDocument7 pagesSurvey of Network Anomaly Detection Using Markov ChainijcseitPas encore d'évaluation
- Class-Dependent Density Feature SelectionDocument13 pagesClass-Dependent Density Feature SelectionNabeel AsimPas encore d'évaluation
- A Hybrid System For Reducing The False Alarm Rate of Anomaly Intrusion Detection SystemDocument6 pagesA Hybrid System For Reducing The False Alarm Rate of Anomaly Intrusion Detection Systemashish88bhardwaj_314Pas encore d'évaluation
- Sciencedirect: Survey On Anomaly Detection Using Data Mining TechniquesDocument6 pagesSciencedirect: Survey On Anomaly Detection Using Data Mining TechniquesncetcsedeptPas encore d'évaluation
- An Ensemble Design of Intrusion Detection System For Handling Uncertainty Using Neutrosophic Logic ClassifierDocument9 pagesAn Ensemble Design of Intrusion Detection System For Handling Uncertainty Using Neutrosophic Logic ClassifierMia AmaliaPas encore d'évaluation
- Strategies for Dealing with Real World Classification ProblemsDocument6 pagesStrategies for Dealing with Real World Classification ProblemsqazPas encore d'évaluation
- Data ScienceDocument7 pagesData ScienceZawar KhanPas encore d'évaluation
- Fuzzy techniques improve time series data imputationDocument6 pagesFuzzy techniques improve time series data imputationFarid Ali MousaPas encore d'évaluation
- Hybrid feature extraction improves IDS performanceDocument9 pagesHybrid feature extraction improves IDS performanceAliya TabassumPas encore d'évaluation
- Machine Learning Mini Project ReportDocument16 pagesMachine Learning Mini Project Reportpriyank mishraPas encore d'évaluation
- 2paper (SCI)Document10 pages2paper (SCI)lavanya penumudiPas encore d'évaluation
- An Overview of Machine Learning Applications For Intrusion DetectionDocument31 pagesAn Overview of Machine Learning Applications For Intrusion DetectionLucBettaiebPas encore d'évaluation
- DatawarehousingDocument10 pagesDatawarehousingHarshit JainPas encore d'évaluation
- PavanDocument23 pagesPavanAnusha KandulaPas encore d'évaluation
- DT 444Document19 pagesDT 444htlt215Pas encore d'évaluation
- Introduction To Pattern Recognition SystemDocument12 pagesIntroduction To Pattern Recognition SystemSandra NituPas encore d'évaluation
- Feature Selection Helps Classify Small SamplesDocument13 pagesFeature Selection Helps Classify Small SamplesleosallePas encore d'évaluation
- Feature Selection Based On Fuzzy EntropyDocument5 pagesFeature Selection Based On Fuzzy EntropyInternational Journal of Application or Innovation in Engineering & ManagementPas encore d'évaluation
- A Novel Feature Selection Method For Data Mining TDocument17 pagesA Novel Feature Selection Method For Data Mining TRishi AstasachindraPas encore d'évaluation
- A Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningDocument12 pagesA Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningB AnandPas encore d'évaluation
- Machine Learnin-WPS Office PDFDocument11 pagesMachine Learnin-WPS Office PDFSoham ChatterjeePas encore d'évaluation
- Workflow of a Machine Learning ProjectDocument12 pagesWorkflow of a Machine Learning ProjectashishPas encore d'évaluation
- Anomaly Detection Using Machine LearningDocument10 pagesAnomaly Detection Using Machine Learningvishal jainPas encore d'évaluation
- Information-decomposition-model-based algorithm estimates missing values in non-random datasetsDocument11 pagesInformation-decomposition-model-based algorithm estimates missing values in non-random datasetsJuan Francisco Durango GrisalesPas encore d'évaluation
- Web Engineering: With Effect From The Academic Year 2020-21Document2 pagesWeb Engineering: With Effect From The Academic Year 2020-21Ravindra ReddyPas encore d'évaluation
- Association and Correlation Analysis For Predicting The Anomaly in The Stock MarketDocument7 pagesAssociation and Correlation Analysis For Predicting The Anomaly in The Stock MarketRavindra ReddyPas encore d'évaluation
- G.O.Ms - No. 1, Dated 01.01.2022 - COVID-19Document2 pagesG.O.Ms - No. 1, Dated 01.01.2022 - COVID-19Ravindra ReddyPas encore d'évaluation
- Pre Annual Grammar Revision Worksheet 2021-22 Answer KeyDocument3 pagesPre Annual Grammar Revision Worksheet 2021-22 Answer KeyRavindra ReddyPas encore d'évaluation
- INDIA - 2022 Paper 159Document1 pageINDIA - 2022 Paper 159Ravindra ReddyPas encore d'évaluation
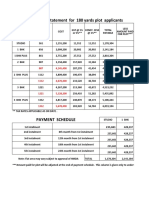
- COST STATEMENT FOR 180 SyDocument3 pagesCOST STATEMENT FOR 180 SyRavindra ReddyPas encore d'évaluation
- 1.implement FIND-S Algorithm: DesriptionDocument19 pages1.implement FIND-S Algorithm: DesriptionRavindra ReddyPas encore d'évaluation
- Faculty Individual - 2021-22 - Odd Semester - 21.12.2021 - First Year 31.1.2021Document1 pageFaculty Individual - 2021-22 - Odd Semester - 21.12.2021 - First Year 31.1.2021Ravindra ReddyPas encore d'évaluation
- Mamatha ChinthareddyDocument11 pagesMamatha ChinthareddyRavindra ReddyPas encore d'évaluation
- Grade 3 - Math Pre Annual Assessment Revision WorksheetDocument6 pagesGrade 3 - Math Pre Annual Assessment Revision WorksheetRavindra ReddyPas encore d'évaluation
- Grade 3 - Math Pre Annual Assessment Revision WorksheetDocument6 pagesGrade 3 - Math Pre Annual Assessment Revision WorksheetRavindra ReddyPas encore d'évaluation
- Grade 3 - Math Pre Annual Assessment Revision WorksheetDocument6 pagesGrade 3 - Math Pre Annual Assessment Revision WorksheetRavindra ReddyPas encore d'évaluation
- Chapter 19: Distributed DatabasesDocument125 pagesChapter 19: Distributed DatabasesNhb SohelPas encore d'évaluation
- Annex - II (Revised-4)Document1 pageAnnex - II (Revised-4)Ravindra ReddyPas encore d'évaluation
- C and DS ContentDocument380 pagesC and DS ContentRavindra Reddy50% (2)
- 8 WeekDocument5 pages8 WeekRavindra ReddyPas encore d'évaluation
- Annex - II (Revised-4)Document1 pageAnnex - II (Revised-4)Ravindra ReddyPas encore d'évaluation
- Network Security EssentialsDocument31 pagesNetwork Security EssentialsSukthanaPongmaPas encore d'évaluation
- C and DS ContentDocument380 pagesC and DS ContentRavindra Reddy50% (2)
- Systematic Approach To Intrusion Evaluation Using The Rough Set Based ClassificationDocument6 pagesSystematic Approach To Intrusion Evaluation Using The Rough Set Based ClassificationRavindra ReddyPas encore d'évaluation
- A Genetic Algorithm Based Elucidation For Improving Intrusion Detection Through Condensed Feature Set by KDD 99 Data SetDocument10 pagesA Genetic Algorithm Based Elucidation For Improving Intrusion Detection Through Condensed Feature Set by KDD 99 Data SetRavindra ReddyPas encore d'évaluation
- Privacy Enhanced Intrusion Detection: 1.1 AbstractDocument14 pagesPrivacy Enhanced Intrusion Detection: 1.1 AbstractRavindra ReddyPas encore d'évaluation
- 1 s2.0 S0267364916300802 MainDocument19 pages1 s2.0 S0267364916300802 MainRavindra ReddyPas encore d'évaluation
- Machine Learning ManualDocument81 pagesMachine Learning ManualPrabhu100% (1)
- Journal of Statistical Software: Gamboostlss: An R Package For Model Building andDocument31 pagesJournal of Statistical Software: Gamboostlss: An R Package For Model Building andtitanache0078434Pas encore d'évaluation
- Design of Multisensor Fusion-Based Tool Condition Monitoring System in End MillingDocument14 pagesDesign of Multisensor Fusion-Based Tool Condition Monitoring System in End Millinguamiranda3518Pas encore d'évaluation
- Table of Contents:: Predictnow - Ai Lets You Apply Machine Learning Predictions To Your Data Without Any ProgrammingDocument15 pagesTable of Contents:: Predictnow - Ai Lets You Apply Machine Learning Predictions To Your Data Without Any ProgrammingsgPas encore d'évaluation
- Recommendation SystemsDocument31 pagesRecommendation Systemsfabrizio01Pas encore d'évaluation
- Expert Systems With Applications: John Atkinson, Daniel CamposDocument7 pagesExpert Systems With Applications: John Atkinson, Daniel CamposPanos LionasPas encore d'évaluation
- Lookalike ConceptsDocument10 pagesLookalike ConceptssanjoyPas encore d'évaluation
- Applied Computing and Informatics: Kumash Kapadia, Hussein Abdel-Jaber, Fadi Thabtah, Wael HadiDocument6 pagesApplied Computing and Informatics: Kumash Kapadia, Hussein Abdel-Jaber, Fadi Thabtah, Wael Hadigaur1234Pas encore d'évaluation
- Feature Selection in Machine LearningDocument4 pagesFeature Selection in Machine LearningSTYXPas encore d'évaluation
- Tamir AntenehDocument149 pagesTamir AntenehAmePas encore d'évaluation
- 1-s2.0-S0306261924000515-mainDocument13 pages1-s2.0-S0306261924000515-mainjkm79sy2khPas encore d'évaluation
- Automatic Prediction of Diabetic Retinopathy and Glaucoma Through Retinal Image Analysis and Data Mining Techniques PDFDocument4 pagesAutomatic Prediction of Diabetic Retinopathy and Glaucoma Through Retinal Image Analysis and Data Mining Techniques PDFMohammad RofiiPas encore d'évaluation
- A Machine Learning Framework For Sport Result PredictionDocument7 pagesA Machine Learning Framework For Sport Result PredictionSiddharth ShuklaPas encore d'évaluation
- AccentureDocument3 pagesAccentureAshwin ChaudhariPas encore d'évaluation
- Assignment - Machine LearningDocument3 pagesAssignment - Machine LearningLe GPas encore d'évaluation
- Coastal Sentiment Review Using Naïve Bayes With Feature Selection Genetic AlgorithmDocument10 pagesCoastal Sentiment Review Using Naïve Bayes With Feature Selection Genetic AlgorithmCevi HerdianPas encore d'évaluation
- Assessment IIDocument25 pagesAssessment IIIshita JindalPas encore d'évaluation
- Decision Trees: A Recent Overview: S. B. KotsiantisDocument23 pagesDecision Trees: A Recent Overview: S. B. KotsiantisvarshithPas encore d'évaluation
- Predictive Maintenance Based On Event-Log Analysis: A Case StudyDocument12 pagesPredictive Maintenance Based On Event-Log Analysis: A Case StudyNapoleón Hernandez Venegas100% (1)
- Discriminative frequent pattern analysis for effective classificationDocument10 pagesDiscriminative frequent pattern analysis for effective classificationIvan FadillahPas encore d'évaluation
- FAST - A ROC-Based Feature Selection Metric For Small Samples and Imbalanced Data Classification Problems (2008)Document9 pagesFAST - A ROC-Based Feature Selection Metric For Small Samples and Imbalanced Data Classification Problems (2008)wokeshPas encore d'évaluation
- Bi NotesDocument138 pagesBi NotesFake BoraPas encore d'évaluation
- MLOps Brochure BITSDocument27 pagesMLOps Brochure BITSsivahariPas encore d'évaluation
- Man V Machine: Greyhound Racing Predictions: MSC Research Project Data AnalyticsDocument26 pagesMan V Machine: Greyhound Racing Predictions: MSC Research Project Data Analyticscucu269Pas encore d'évaluation
- Review of Heart Disease Prediction System Using Data Mining and Hybrid Intelligent TechniquesDocument5 pagesReview of Heart Disease Prediction System Using Data Mining and Hybrid Intelligent TechniquesAmedu EmmanuelPas encore d'évaluation
- A Guide To Machine Learning Algorithms 100+Document49 pagesA Guide To Machine Learning Algorithms 100+Muhammad AndiPas encore d'évaluation
- Feature Selection For Loan Repayment Prediction System Using Machine LearningDocument10 pagesFeature Selection For Loan Repayment Prediction System Using Machine LearningIJRASETPublicationsPas encore d'évaluation
- Predicting Young's Modulus of Linear Polyurethane and Polyurethane-Polyurea ElastomersDocument14 pagesPredicting Young's Modulus of Linear Polyurethane and Polyurethane-Polyurea Elastomers刘俊里Pas encore d'évaluation
- Future Generation Computer SystemsDocument13 pagesFuture Generation Computer SystemstharePas encore d'évaluation
- Corporate Failure Prediction Models in The Twenty-First Century: A ReviewDocument23 pagesCorporate Failure Prediction Models in The Twenty-First Century: A Reviewdr musafirPas encore d'évaluation
- Dark Data: Why What You Don’t Know MattersD'EverandDark Data: Why What You Don’t Know MattersÉvaluation : 4.5 sur 5 étoiles4.5/5 (3)
- ITIL 4: Digital and IT strategy: Reference and study guideD'EverandITIL 4: Digital and IT strategy: Reference and study guideÉvaluation : 5 sur 5 étoiles5/5 (1)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveD'EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveÉvaluation : 5 sur 5 étoiles5/5 (5)
- Agile Metrics in Action: How to measure and improve team performanceD'EverandAgile Metrics in Action: How to measure and improve team performancePas encore d'évaluation
- Blockchain Basics: A Non-Technical Introduction in 25 StepsD'EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsÉvaluation : 4.5 sur 5 étoiles4.5/5 (24)
- Monitored: Business and Surveillance in a Time of Big DataD'EverandMonitored: Business and Surveillance in a Time of Big DataÉvaluation : 4 sur 5 étoiles4/5 (1)
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]D'EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Évaluation : 5 sur 5 étoiles5/5 (8)
- COBOL Basic Training Using VSAM, IMS and DB2D'EverandCOBOL Basic Training Using VSAM, IMS and DB2Évaluation : 5 sur 5 étoiles5/5 (2)
- ITIL 4: Create, Deliver and Support: Reference and study guideD'EverandITIL 4: Create, Deliver and Support: Reference and study guidePas encore d'évaluation
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLD'EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLÉvaluation : 4.5 sur 5 étoiles4.5/5 (46)
- Mastering PostgreSQL: A Comprehensive Guide for DevelopersD'EverandMastering PostgreSQL: A Comprehensive Guide for DevelopersPas encore d'évaluation
- ITIL 4: Direct, plan and improve: Reference and study guideD'EverandITIL 4: Direct, plan and improve: Reference and study guidePas encore d'évaluation
- DB2 11 for z/OS: SQL Basic Training for Application DevelopersD'EverandDB2 11 for z/OS: SQL Basic Training for Application DevelopersÉvaluation : 4 sur 5 étoiles4/5 (1)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleD'EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleÉvaluation : 4 sur 5 étoiles4/5 (16)
- Pragmatic Enterprise Architecture: Strategies to Transform Information Systems in the Era of Big DataD'EverandPragmatic Enterprise Architecture: Strategies to Transform Information Systems in the Era of Big DataPas encore d'évaluation
- Joe Celko's SQL for Smarties: Advanced SQL ProgrammingD'EverandJoe Celko's SQL for Smarties: Advanced SQL ProgrammingÉvaluation : 3 sur 5 étoiles3/5 (1)
- Oracle Database 12c Install, Configure & Maintain Like a Professional: Install, Configure & Maintain Like a ProfessionalD'EverandOracle Database 12c Install, Configure & Maintain Like a Professional: Install, Configure & Maintain Like a ProfessionalPas encore d'évaluation

















































































































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-1-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1713743787?v=1)



















