Vous aimerez peut-être aussi
- Facility Maintenance Series: Types of Maintenance ProgramsD'EverandFacility Maintenance Series: Types of Maintenance ProgramsÉvaluation : 5 sur 5 étoiles5/5 (1)
- Barringer Analyzer ReliabilityDocument9 pagesBarringer Analyzer ReliabilityTessfaye Wolde Gebretsadik100% (2)
- A Simply Strategy For Eliminating Plant FailuresDocument17 pagesA Simply Strategy For Eliminating Plant FailuresElvis DiazPas encore d'évaluation
- Mean Time Between FailureDocument10 pagesMean Time Between FailureJay Rai100% (1)
- Session 11 12 - FMECADocument21 pagesSession 11 12 - FMECASusanoo12Pas encore d'évaluation
- Asset Maintenance Management Journal 1501Document59 pagesAsset Maintenance Management Journal 1501Budi100% (1)
- Modern Approaches to Discrete, Integrated Component and System Reliability Engineering: Reliability EngineeringD'EverandModern Approaches to Discrete, Integrated Component and System Reliability Engineering: Reliability EngineeringPas encore d'évaluation
- Eng Oee Industry StandardDocument30 pagesEng Oee Industry Standardjoseparra100% (1)
- Maintenance StrategyDocument9 pagesMaintenance Strategyganeshji@vsnl.comPas encore d'évaluation
- 10 Steps To Precision Maintenance Reliability SuccessDocument11 pages10 Steps To Precision Maintenance Reliability SuccessElvis DiazPas encore d'évaluation
- Product Reliability and MTBF2Document4 pagesProduct Reliability and MTBF2sifuszPas encore d'évaluation
- Mean Time Between FailureDocument10 pagesMean Time Between FailureMansour Soliman0% (1)
- 5 Ways To Break Out of The Reactive Maintenance Cycle of DoomDocument5 pages5 Ways To Break Out of The Reactive Maintenance Cycle of DoomElvis DiazPas encore d'évaluation
- InDesign Manual 2022Document449 pagesInDesign Manual 2022Anders Vaelds100% (2)
- Precision MaintenanceDocument8 pagesPrecision MaintenanceMohammad GhiasiPas encore d'évaluation
- Service Best Practice Dealer IT KPI Administrator GuideDocument7 pagesService Best Practice Dealer IT KPI Administrator GuideSergio lopezPas encore d'évaluation
- NetOps 2.0 Transformation: The DIRE MethodologyD'EverandNetOps 2.0 Transformation: The DIRE MethodologyÉvaluation : 5 sur 5 étoiles5/5 (1)
- Q & A ReliablityDocument6 pagesQ & A ReliablitypkcdubPas encore d'évaluation
- 8 Essential KPIs For Maintenance Management - TRACTIANDocument26 pages8 Essential KPIs For Maintenance Management - TRACTIANsatya krishna chagantiPas encore d'évaluation
- Managing Maintenance BudgetDocument6 pagesManaging Maintenance BudgetElvis DiazPas encore d'évaluation
- MTBF and Power Supply ReliabilityDocument8 pagesMTBF and Power Supply ReliabilityMazlan MansorPas encore d'évaluation
- Evolution of Maintenance PracticesDocument10 pagesEvolution of Maintenance PracticesKandaswamy VajjiraveluPas encore d'évaluation
- Why Do Machines and Equipment Continue To Fail in CompaniesDocument13 pagesWhy Do Machines and Equipment Continue To Fail in CompaniesElvis DiazPas encore d'évaluation
- Adopting Risk-Based Maintenance Enabled by SAP Asset Strategy and Performance ManagementDocument51 pagesAdopting Risk-Based Maintenance Enabled by SAP Asset Strategy and Performance ManagementElvis Diaz100% (1)
- Preventive Maintenance Optimization Through FMEADocument3 pagesPreventive Maintenance Optimization Through FMEAHugoCabanillasPas encore d'évaluation
- Top Five Maintenance Reliability Enablers For Improved Operational PerformanceDocument10 pagesTop Five Maintenance Reliability Enablers For Improved Operational PerformanceElvis DiazPas encore d'évaluation
- 3162.Mtbf MTTF MTTR Fit ExplanationsDocument3 pages3162.Mtbf MTTF MTTR Fit ExplanationsGeorgeSalazarPas encore d'évaluation
- CP 1 CBM StrategyDocument4 pagesCP 1 CBM StrategyCristian Garcia100% (1)
- Maintenance Indices - Meaningful Measures of Equipment Performance: 1, #10D'EverandMaintenance Indices - Meaningful Measures of Equipment Performance: 1, #10Pas encore d'évaluation
- 9 Principles of Modern MaintenanceDocument9 pages9 Principles of Modern MaintenancedejanPas encore d'évaluation
- Bathtub, Failure Distribution, MTBF, MTTF, and MoreDocument10 pagesBathtub, Failure Distribution, MTBF, MTTF, and MoreVivek ShrivastavaPas encore d'évaluation
- DCCADocument248 pagesDCCATan Keng HuiPas encore d'évaluation
- Flexi Network Gateway Rel. 2.1 2.0, Operating Documentation, v2Document38 pagesFlexi Network Gateway Rel. 2.1 2.0, Operating Documentation, v2Yassine LASRIPas encore d'évaluation
- Time To Move On From Mean Time Between Failure (MTBF) and Mean Time To Failure (MTTF)Document4 pagesTime To Move On From Mean Time Between Failure (MTBF) and Mean Time To Failure (MTTF)aliPas encore d'évaluation
- Reliability - Introduction To MTBF and CalculationsDocument15 pagesReliability - Introduction To MTBF and CalculationsCarlos Jose Sibaja CardozoPas encore d'évaluation
- White Paper MTBF: The Most Misunderstood RAMS Parameter: Silver AtenaDocument2 pagesWhite Paper MTBF: The Most Misunderstood RAMS Parameter: Silver AtenaJuan Ramón RuizPas encore d'évaluation
- MTBFDocument4 pagesMTBFmithileshkumareicPas encore d'évaluation
- Performing Effective MTBF Comparisons For Data Center InfrastructureDocument16 pagesPerforming Effective MTBF Comparisons For Data Center Infrastructure(unknown)Pas encore d'évaluation
- Simple Guide To MTBFDocument14 pagesSimple Guide To MTBFAminu A.OPas encore d'évaluation
- MTBF MTTR MTTF FitDocument4 pagesMTBF MTTR MTTF Fitamitverma7737458138Pas encore d'évaluation
- MTBF and Availability PrimerDocument5 pagesMTBF and Availability PrimerSatyanneshi ERPas encore d'évaluation
- MTBFDocument3 pagesMTBFscribdfuckuPas encore d'évaluation
- Unit 1Document10 pagesUnit 1Shaku SinglaPas encore d'évaluation
- Top 5 Reasons Companies Experience Equipment FailuresDocument4 pagesTop 5 Reasons Companies Experience Equipment FailuresHernnPas encore d'évaluation
- What Is MTBFDocument2 pagesWhat Is MTBFElvis DiazPas encore d'évaluation
- Company White Paper Shortage SolutionsDocument10 pagesCompany White Paper Shortage Solutionsapi-257036971Pas encore d'évaluation
- Complete GuideDocument5 pagesComplete Guideamk2009Pas encore d'évaluation
- MTTR MTBF - Simple GuideDocument10 pagesMTTR MTBF - Simple Guidenadal.shahidPas encore d'évaluation
- Establishing Ultrasound Testing As A CBM Pillar Part 2 - Reliabilityweb - A Culture of ReliabilityDocument5 pagesEstablishing Ultrasound Testing As A CBM Pillar Part 2 - Reliabilityweb - A Culture of Reliabilityatorresh090675Pas encore d'évaluation
- MTBF MTTR MTTF FIT Terms 3618wp 1703446671Document2 pagesMTBF MTTR MTTF FIT Terms 3618wp 1703446671Dan SartoriPas encore d'évaluation
- Fundamentals of Availability TranscriptDocument13 pagesFundamentals of Availability TranscriptJean Constantin Eko MedjoPas encore d'évaluation
- Fundamentals of Availability TranscriptDocument13 pagesFundamentals of Availability Transcriptfernanda boldtPas encore d'évaluation
- Reliability Centered Maintenance Literature ReviewDocument5 pagesReliability Centered Maintenance Literature Reviewfvehwd96Pas encore d'évaluation
- Establishing Ultrasound Testing As A CBM Pillar Part 3 - Reliabilityweb - A Culture of ReliabilityDocument4 pagesEstablishing Ultrasound Testing As A CBM Pillar Part 3 - Reliabilityweb - A Culture of Reliabilityatorresh090675Pas encore d'évaluation
- Aste-5zyqf2 R1 enDocument15 pagesAste-5zyqf2 R1 enram27_rajiPas encore d'évaluation
- Managing Mill Maintenance - Maintenance Options and ChallengesDocument7 pagesManaging Mill Maintenance - Maintenance Options and ChallengesMilling and Grain magazinePas encore d'évaluation
- Reliability Centered Maintenance - John Moubray - 04Document100 pagesReliability Centered Maintenance - John Moubray - 04George Florin OcheaPas encore d'évaluation
- MTBF User Guide: Understanding DefinitionsDocument4 pagesMTBF User Guide: Understanding DefinitionsjaviermvsPas encore d'évaluation
- Why Do We Need Fmeas?Document44 pagesWhy Do We Need Fmeas?Leonardo SunsinoPas encore d'évaluation
- A Critical Discussion On Bath-Tub CurveDocument18 pagesA Critical Discussion On Bath-Tub CurveSyafik PipikPas encore d'évaluation
- Thesis FmeaDocument7 pagesThesis Fmeaafktgmqaouoixx100% (2)
- Chapter 1: Introduction To Operations ManagementDocument5 pagesChapter 1: Introduction To Operations ManagementsultanatkhanPas encore d'évaluation
- Are Your PMs Working For or Against YouDocument4 pagesAre Your PMs Working For or Against Yousrjsk1Pas encore d'évaluation
- Teoria Examen Final ProducciónDocument2 pagesTeoria Examen Final ProducciónJuan Jose RodriguezPas encore d'évaluation
- Issues and Aims For JIPMDocument5 pagesIssues and Aims For JIPMtoquekedaPas encore d'évaluation
- Fundamentals of Availability TranscriptDocument12 pagesFundamentals of Availability TranscriptMAHENDRA HARIJANPas encore d'évaluation
- Tips For A Lean Approach To Motor Reliability: by Noah Bethel, Vice President-Product Development, Pdma CorporationDocument5 pagesTips For A Lean Approach To Motor Reliability: by Noah Bethel, Vice President-Product Development, Pdma CorporationNguyenPas encore d'évaluation
- Manufacturing Maintenance ExcellenceDocument3 pagesManufacturing Maintenance Excellencemintek2009Pas encore d'évaluation
- SKF Bearing ReliabilityDocument14 pagesSKF Bearing ReliabilityedimazorPas encore d'évaluation
- Maintenance Program Development For New Assets ServicesDocument8 pagesMaintenance Program Development For New Assets ServicesElvis DiazPas encore d'évaluation
- My Personal Journey To Escaping The Vicious Cycle of Reactive MaintenanceDocument3 pagesMy Personal Journey To Escaping The Vicious Cycle of Reactive MaintenanceElvis DiazPas encore d'évaluation
- Harald RødsethDocument203 pagesHarald RødsethElvis DiazPas encore d'évaluation
- Elevating Maintenance Reliability Practices Financial Business CaseDocument14 pagesElevating Maintenance Reliability Practices Financial Business CaseElvis DiazPas encore d'évaluation
- RCM Process Reduces Maintenance Spending Increases Production OutputDocument5 pagesRCM Process Reduces Maintenance Spending Increases Production OutputElvis DiazPas encore d'évaluation
- 10 Basics To Improve Maintenance in Your Organization MainnovationDocument2 pages10 Basics To Improve Maintenance in Your Organization MainnovationElvis DiazPas encore d'évaluation
- Aligning Maintenance With Business GoalsDocument3 pagesAligning Maintenance With Business GoalsElvis DiazPas encore d'évaluation
- 7 Effective Strategies To Initiate Proactive Maintenance Culture For Companies That Use SpreadsheetsDocument3 pages7 Effective Strategies To Initiate Proactive Maintenance Culture For Companies That Use SpreadsheetsElvis DiazPas encore d'évaluation
- Fallas Tiempos Acumt. Tiempo (T/Ti) LN (T/Ti)Document5 pagesFallas Tiempos Acumt. Tiempo (T/Ti) LN (T/Ti)Elvis DiazPas encore d'évaluation
- Template AMEFDocument10 pagesTemplate AMEFElvis DiazPas encore d'évaluation
- Failure Code Hierarchy Is It The Best Design?: John ReeveDocument3 pagesFailure Code Hierarchy Is It The Best Design?: John ReeveElvis DiazPas encore d'évaluation
- Predictive Maintenance, A CommentDocument10 pagesPredictive Maintenance, A CommentElvis DiazPas encore d'évaluation
- SPM33 Modbus Address ListDocument26 pagesSPM33 Modbus Address ListjesankingPas encore d'évaluation
- Lecture Notes 13 7Document14 pagesLecture Notes 13 7Aldrige LuisPas encore d'évaluation
- Interpretasi n47Document8 pagesInterpretasi n47Mahgfira GintingPas encore d'évaluation
- MAD ImpDocument1 pageMAD ImpHarshwardhansinh ChauhanPas encore d'évaluation
- Pacing Guidelines For Database FoundationsDocument2 pagesPacing Guidelines For Database FoundationsRizal SatriawanPas encore d'évaluation
- Tech Article - Optimized Use of Power Supply ModuleDocument3 pagesTech Article - Optimized Use of Power Supply ModuleSandeep NairPas encore d'évaluation
- Abana Group RESEARCH CHAP1 5Document47 pagesAbana Group RESEARCH CHAP1 5Maui Carlos EstonactocPas encore d'évaluation
- Supervisor Monthly Report MINGGU 2Document7 pagesSupervisor Monthly Report MINGGU 2dwi hapsPas encore d'évaluation
- Fer Aguilar CV EnglishDocument1 pageFer Aguilar CV EnglishFer AguilarPas encore d'évaluation
- Database Fundamental (TIS 1101 Tutorial 10Document3 pagesDatabase Fundamental (TIS 1101 Tutorial 10Blackk WorldzPas encore d'évaluation
- Data Sheet: Dekafix DEK 6 FSZ 41-50Document8 pagesData Sheet: Dekafix DEK 6 FSZ 41-50RAVIMURUGANPas encore d'évaluation
- Final Examination in Purposive CommunicationDocument3 pagesFinal Examination in Purposive CommunicationJames VicentePas encore d'évaluation
- MS-CIT Job Readiness 2023 Day-Wise Break-Up EnglishDocument119 pagesMS-CIT Job Readiness 2023 Day-Wise Break-Up EnglishVaishakhi GadePas encore d'évaluation
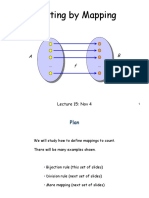
- Chap5 - Counting by MappingDocument33 pagesChap5 - Counting by MappingDorian GreyPas encore d'évaluation
- EMVCo 3DS Protocol Oct2017Document255 pagesEMVCo 3DS Protocol Oct2017vicvinodPas encore d'évaluation
- Ass 6Document3 pagesAss 6DevPas encore d'évaluation
- Geotechnical Engineer CV: Career ObjectiveDocument2 pagesGeotechnical Engineer CV: Career ObjectiveMuazPas encore d'évaluation
- Free Proxy Lists - HTTP Proxy Servers (IP Address, Port) - PDF - Hypertext Transfer Protocol - Proxy ServerDocument1 pageFree Proxy Lists - HTTP Proxy Servers (IP Address, Port) - PDF - Hypertext Transfer Protocol - Proxy ServerEnzo DadiPas encore d'évaluation
- Practical Pentesting ERP Systems and Business Applications EAS SECDocument48 pagesPractical Pentesting ERP Systems and Business Applications EAS SECmohammed.aljakriPas encore d'évaluation
- 06 Tda Medix90 01Document9 pages06 Tda Medix90 01Sulehri EntertainmentPas encore d'évaluation
- AgentinstalllogDocument86 pagesAgentinstalllogRahatullah SaadatPas encore d'évaluation
- Lecture 4 - Ais2Document12 pagesLecture 4 - Ais2Jhunsam SamacoPas encore d'évaluation
- Frequency Tables, Bar Graphs, and Histograms: Handout #5Document54 pagesFrequency Tables, Bar Graphs, and Histograms: Handout #5NadiahNasirPas encore d'évaluation
- Logistics 05 00062Document16 pagesLogistics 05 00062VikasPas encore d'évaluation
- Nano Ceramic Roofing TileDocument13 pagesNano Ceramic Roofing Tileaqsam aliPas encore d'évaluation
- Two Sided MaterialDocument3 pagesTwo Sided Materialreza fachrul rozyPas encore d'évaluation
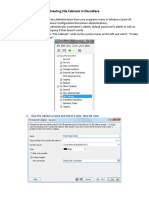
- Creating File Cabinets in DocuwareDocument5 pagesCreating File Cabinets in DocuwareOmar AbooshPas encore d'évaluation