Vous aimerez peut-être aussi
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- Which Layer Chooses and Determines The Availability of CommunDocument5 pagesWhich Layer Chooses and Determines The Availability of CommunOctavius BalangkitPas encore d'évaluation
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Advantages of DatabasesDocument5 pagesAdvantages of DatabasesshammyjosephkPas encore d'évaluation
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- M.Tech I Mid QPDocument2 pagesM.Tech I Mid QPsree bvritPas encore d'évaluation
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (894)
- Data Analysis in Qualitative ResearchDocument4 pagesData Analysis in Qualitative ResearchNikul JoshiPas encore d'évaluation
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Data Access For Highly Scalable SolutionsDocument273 pagesData Access For Highly Scalable SolutionsTamash IonutPas encore d'évaluation
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- Apps Make Semantic Web A Reality-2005Document2 pagesApps Make Semantic Web A Reality-2005Amit ShethPas encore d'évaluation
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Defining The Marketing Research Problem and Developing An ApproachDocument25 pagesDefining The Marketing Research Problem and Developing An ApproachMir Hossain EkramPas encore d'évaluation
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Mainframe Training Overview: z/OS FundamentalsDocument9 pagesMainframe Training Overview: z/OS FundamentalsLuis RamirezPas encore d'évaluation
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (587)
- Big DataDocument2 pagesBig Datagohriishana2012Pas encore d'évaluation
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (265)
- Test Case: If Your Formulas Are Correct, You Should Get The Following Values For The First SentenceDocument7 pagesTest Case: If Your Formulas Are Correct, You Should Get The Following Values For The First SentenceAbdelrahman AshrafPas encore d'évaluation
- Advantages of the database approachDocument13 pagesAdvantages of the database approachAhmad Hussain Shafi SE-3rdPas encore d'évaluation
- Operate Database ApplicationDocument31 pagesOperate Database Applicationmelesse bisemaPas encore d'évaluation
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Query Processing System: BREB-2016)Document11 pagesQuery Processing System: BREB-2016)Salim Shadman AnkurPas encore d'évaluation
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- TreeView Control inDocument4 pagesTreeView Control inSaku RaPas encore d'évaluation
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Interview QnsDocument195 pagesInterview QnsJames AndersonPas encore d'évaluation
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Energy Consumption at Home Grade 9 Project and Rubric PDFDocument3 pagesEnergy Consumption at Home Grade 9 Project and Rubric PDFascd_msvuPas encore d'évaluation
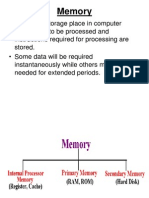
- Memory: - Electronic Storage Place in ComputerDocument18 pagesMemory: - Electronic Storage Place in ComputerSaikatSenguptaPas encore d'évaluation
- Database Design Using REA ModelingDocument35 pagesDatabase Design Using REA ModelingShella FrankeraPas encore d'évaluation
- DNA HistoricalServices PDFDocument102 pagesDNA HistoricalServices PDFAdrian PajakiewiczPas encore d'évaluation
- LogDocument2 pagesLogKarran DerPas encore d'évaluation
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Parental Involvement in Education in Ghana: The Case of A Private Elementary SchoolDocument16 pagesParental Involvement in Education in Ghana: The Case of A Private Elementary SchoolJustine CagasPas encore d'évaluation
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2219)
- Wef GGGR 2021Document405 pagesWef GGGR 2021MarisolAndrésPas encore d'évaluation
- Research Paper Topics About Academic PerformanceDocument8 pagesResearch Paper Topics About Academic Performancelctcjtznd100% (1)
- Novell 050-733 Exam Questions - Major 050 733 PDF QuestionsDocument5 pagesNovell 050-733 Exam Questions - Major 050 733 PDF Questionsherypeal100% (1)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Decompose Functional DependenciesDocument3 pagesDecompose Functional Dependenciestiyixe1817Pas encore d'évaluation
- Unit 5 Sample TestDocument6 pagesUnit 5 Sample TestcoffeeneverendsPas encore d'évaluation
- Practical English Learning Using Word Cards in Tiwoho Village, Wori District, North Minahasa RegencyDocument7 pagesPractical English Learning Using Word Cards in Tiwoho Village, Wori District, North Minahasa RegencyIjahss JournalPas encore d'évaluation
- How To Handle Multi-Language Translations in QlikViewDocument24 pagesHow To Handle Multi-Language Translations in QlikViewLinhNguyenPas encore d'évaluation
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (119)
- Using Tourism Brochures to Improve Students' Descriptive WritingDocument34 pagesUsing Tourism Brochures to Improve Students' Descriptive WritingDeva Persikmania ManchunianPas encore d'évaluation
- Test SqsDocument8 pagesTest Sqssamir silwalPas encore d'évaluation
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)