Vous aimerez peut-être aussi
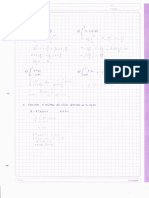
- Tarea 3. Probabilidad 1.Document3 pagesTarea 3. Probabilidad 1.Astrid D100% (1)
- Probab I Lida DesDocument74 pagesProbab I Lida Desalexgy56% (9)
- Dis Tri Buci OnesDocument10 pagesDis Tri Buci OnesAnii SuarezPas encore d'évaluation
- Tarea 4 Geovanny Largo PDFDocument4 pagesTarea 4 Geovanny Largo PDFAmor86% (7)
- Capitulo 7Document3 pagesCapitulo 7Marvin GaliciaPas encore d'évaluation
- Guia de Mate III Chida-MachinDocument12 pagesGuia de Mate III Chida-MachinAleRodea0% (9)
- Práctico de Regresión Lineal Múltiple - 1448492426244 - 1448550357377 - 1448550401443Document2 pagesPráctico de Regresión Lineal Múltiple - 1448492426244 - 1448550357377 - 1448550401443Victor NievesPas encore d'évaluation
- MEZCLASDocument2 pagesMEZCLASVictor NievesPas encore d'évaluation
- PRACTICODocument18 pagesPRACTICOVictor NievesPas encore d'évaluation
- Grado Practicas 2 Q InorganicaDocument82 pagesGrado Practicas 2 Q InorganicaCesarPas encore d'évaluation
- Agua OxigenadaDocument24 pagesAgua OxigenadaVictor NievesPas encore d'évaluation
- Hojas de Datos de Seguridad de MaterialesDocument27 pagesHojas de Datos de Seguridad de MaterialesVictor NievesPas encore d'évaluation
- Sustancia PeligrosaDocument46 pagesSustancia PeligrosaVictor NievesPas encore d'évaluation
- Fichas de SeguridadDocument4 pagesFichas de SeguridadVictor NievesPas encore d'évaluation
- ' Ut"''' R'" '''' (/i/., T'.io - ", LT'¡Document8 pages' Ut"''' R'" '''' (/i/., T'.io - ", LT'¡Victor NievesPas encore d'évaluation
- AutoCAD Es Un Software Del Tipo CADDocument13 pagesAutoCAD Es Un Software Del Tipo CADVictor NievesPas encore d'évaluation
- Qué Es AutocadDocument4 pagesQué Es AutocadVictor NievesPas encore d'évaluation
- 1) - Que Programas de Diseño Asistido Por Computadora Existen en La ActualidadDocument5 pages1) - Que Programas de Diseño Asistido Por Computadora Existen en La ActualidadVictor NievesPas encore d'évaluation
- Img PDFDocument1 pageImg PDFVictor NievesPas encore d'évaluation
- Img 0002 PDFDocument1 pageImg 0002 PDFVictor NievesPas encore d'évaluation
- Presentación PetroquimicaDocument30 pagesPresentación PetroquimicaVictor NievesPas encore d'évaluation
- Completacion Doble SelectivaDocument8 pagesCompletacion Doble SelectivaVictor NievesPas encore d'évaluation
- Decada de Los 60Document17 pagesDecada de Los 60Yoa NitaPas encore d'évaluation
- Hidraulica de PerforacionDocument38 pagesHidraulica de PerforacionVictor NievesPas encore d'évaluation
- Diseño y Evaluación de Separadores Bifásicos y TrifásicoDocument281 pagesDiseño y Evaluación de Separadores Bifásicos y TrifásicoMelissa SanchezPas encore d'évaluation
- Caracterizacion de Yacimientos de HidrocarburosDocument23 pagesCaracterizacion de Yacimientos de HidrocarburosVictor NievesPas encore d'évaluation
- AcetilenoDocument4 pagesAcetilenoVictor NievesPas encore d'évaluation
- Bases de Lewis Son Donadoras de ElectronesDocument5 pagesBases de Lewis Son Donadoras de ElectronesVictor NievesPas encore d'évaluation
- AcetilenoDocument4 pagesAcetilenoVictor NievesPas encore d'évaluation
- Tanque de AlmacenamientoDocument4 pagesTanque de AlmacenamientoVictor NievesPas encore d'évaluation
- ReologiaDocument4 pagesReologiaVictor NievesPas encore d'évaluation
- Intercambiadores PDFDocument2 pagesIntercambiadores PDFjosepripollPas encore d'évaluation
- El Hidrógeno y Los Gases NoblesDocument10 pagesEl Hidrógeno y Los Gases NoblesVictor NievesPas encore d'évaluation
- Quimica de Las Arcillas 1Document3 pagesQuimica de Las Arcillas 1Victor NievesPas encore d'évaluation
- ReologiaDocument4 pagesReologiaVictor NievesPas encore d'évaluation
- Guerrero Mayr ProbabilidadDocument3 pagesGuerrero Mayr Probabilidadmayra guerrero100% (1)
- Distribuciones BDocument4 pagesDistribuciones Blya2709 SiPas encore d'évaluation
- Universo Poblacion y MuestraDocument1 pageUniverso Poblacion y MuestraJenifer Ayala GarciaPas encore d'évaluation
- Metodos Estadisticos Oficial 2019-2BDocument134 pagesMetodos Estadisticos Oficial 2019-2BFlor Ines Gutierrez AvalosPas encore d'évaluation
- Teoría de La EstimaciónDocument23 pagesTeoría de La EstimaciónExneyder MontoyaPas encore d'évaluation
- Probabilidad ConsolidadoDocument45 pagesProbabilidad ConsolidadoLeandroNaranjoQuinteroPas encore d'évaluation
- Conceptos Caracterizacion Estatica.Document14 pagesConceptos Caracterizacion Estatica.Grupo A ComunicacionesPas encore d'évaluation
- Conceptos Básicos de ProbabilidadDocument107 pagesConceptos Básicos de ProbabilidadRolando LauraPas encore d'évaluation
- Semana 5 EstadisticaDocument8 pagesSemana 5 EstadisticaClara Milena VillamilPas encore d'évaluation
- Unidad 5Document18 pagesUnidad 5Iván ReyesPas encore d'évaluation
- Análisis de VarianzaDocument24 pagesAnálisis de VarianzaLuis Antonio FigueroaPas encore d'évaluation
- MITACCDocument55 pagesMITACCcliver turpo benique100% (2)
- Tarea 5Document18 pagesTarea 5Luz Angela Chaves GuacanPas encore d'évaluation
- Ejercicios de Estadística InferencialDocument2 pagesEjercicios de Estadística InferencialMarvin Eduardo Chura MartínezPas encore d'évaluation
- Bloque IV Modelos de Probabilidad y EstadísticaDocument37 pagesBloque IV Modelos de Probabilidad y EstadísticaSergio Javier Camargo CervantesPas encore d'évaluation
- Examen Unidad 3 Estadistica 2, EricoDocument6 pagesExamen Unidad 3 Estadistica 2, EricoMaria Sanabria Mur100% (1)
- Ejemplo de Poblacion y MuestraDocument3 pagesEjemplo de Poblacion y Muestraerika gutierrezPas encore d'évaluation
- Notas de EstadisticaDocument32 pagesNotas de Estadisticaluisis CaceresPas encore d'évaluation
- 2 - Muestreo - Aleatorio - Simple (1) - EVMDocument57 pages2 - Muestreo - Aleatorio - Simple (1) - EVMZainx XPLPas encore d'évaluation
- Unión de SucesosDocument24 pagesUnión de Sucesos'Sarai Cordovaa'Pas encore d'évaluation
- Of ErtasDocument2 pagesOf ErtasCinthya Alejandra RobledoPas encore d'évaluation
- Trabajo de Calculo de ProbabilidadesDocument34 pagesTrabajo de Calculo de ProbabilidadesJhampier Lamadrid100% (2)
- Análisis EstadísticoDocument6 pagesAnálisis EstadísticoPablo Ariel DomínguezPas encore d'évaluation
- Pia - Estadistica Inferencial - Grupo CMDocument10 pagesPia - Estadistica Inferencial - Grupo CMJoss CastroPas encore d'évaluation