Vous aimerez peut-être aussi
- Modelo RelacionalDocument96 pagesModelo RelacionalCarlos QRPas encore d'évaluation
- La ElipseDocument16 pagesLa ElipseBERNILLA CARLOS YOVANIPas encore d'évaluation
- Acotaciones Sobre La Causación FormativaDocument22 pagesAcotaciones Sobre La Causación FormativaLeyderLasprillaBarretoPas encore d'évaluation
- Ejemplo de Matriz de LeopoldDocument12 pagesEjemplo de Matriz de LeopoldAntony Urquia RiveraPas encore d'évaluation
- Nosotros - Prólogo PDFDocument14 pagesNosotros - Prólogo PDFWilliam PuentesPas encore d'évaluation
- Las Sociedades TribalesDocument11 pagesLas Sociedades TribalesRafael MartinsPas encore d'évaluation
- La Física Cuántica y RelativistaDocument52 pagesLa Física Cuántica y RelativistaDaniel GarciaPas encore d'évaluation
- Dosier Tecnico Cambio Climatico Ihobe para Periodistas WebDocument26 pagesDosier Tecnico Cambio Climatico Ihobe para Periodistas WebPablilloPas encore d'évaluation
- Charles Coulomb y la ley de las fuerzas eléctricasDocument5 pagesCharles Coulomb y la ley de las fuerzas eléctricasdayportillo100% (1)
- Aportaciones Gauss Electricidad y MagnetismoDocument2 pagesAportaciones Gauss Electricidad y MagnetismomarPas encore d'évaluation
- Sistema Automatizado de Calibración de Densímetros de Inmersión para El Organismo Nacional de Metrología Del Instituto Nacional de Tecnología, Normalización y Metrología (Intn)Document173 pagesSistema Automatizado de Calibración de Densímetros de Inmersión para El Organismo Nacional de Metrología Del Instituto Nacional de Tecnología, Normalización y Metrología (Intn)Gustavo Adelio Riveiro GonzalezPas encore d'évaluation
- Sucesiones AritmeticasDocument41 pagesSucesiones AritmeticasJhoan MaflaPas encore d'évaluation
- c6. Física I. TrabajoDocument14 pagesc6. Física I. TrabajoAntoni VeracruzPas encore d'évaluation
- Teorema Fundamental Del CálculoDocument7 pagesTeorema Fundamental Del CálculoAVENDAÑO GOMEZ JENNIFERPas encore d'évaluation
- Matrices y DeterminantesDocument20 pagesMatrices y DeterminantesJon Holgado100% (1)
- Batalla de Carabobo (1821)Document6 pagesBatalla de Carabobo (1821)Alberto J Salcedo MPas encore d'évaluation
- Poema Del Cante JondoDocument4 pagesPoema Del Cante JondoEstela_MalvidoPas encore d'évaluation
- 2022 La Ensenanza de La Matematica PDFDocument71 pages2022 La Ensenanza de La Matematica PDFCamila GarayPas encore d'évaluation
- El Congreso de Panama de 1826Document175 pagesEl Congreso de Panama de 1826Ezequiel CuevasPas encore d'évaluation
- La Primera Traducción Castellana de La Utopia de Tomás MoroDocument5 pagesLa Primera Traducción Castellana de La Utopia de Tomás MoroCarlos VPas encore d'évaluation
- Material de Estudio Diplomado IEs - ENTREGA 4Document41 pagesMaterial de Estudio Diplomado IEs - ENTREGA 4Luciano Silva MoralesPas encore d'évaluation
- Leyes de KeplerDocument6 pagesLeyes de KeplerS4NT0 PLAYPas encore d'évaluation
- Decadentismo y EtcDocument150 pagesDecadentismo y EtcDiego ValenzuelaPas encore d'évaluation
- Funciones de La MenteDocument12 pagesFunciones de La MenteLiz GiselaPas encore d'évaluation
- Geometría Analítica PlanaDocument15 pagesGeometría Analítica PlanaCarmen BalladaresPas encore d'évaluation
- Historia Del Calculo Diferencial. ISRAEL GARATE CORREADocument2 pagesHistoria Del Calculo Diferencial. ISRAEL GARATE CORREAPaul Navas HugoPas encore d'évaluation
- Superficies ElementalesDocument13 pagesSuperficies ElementalesAlexis VallejoPas encore d'évaluation
- Integrales Definidas y Área Bajo Una CurvaDocument28 pagesIntegrales Definidas y Área Bajo Una Curvademer22Pas encore d'évaluation
- Principio de exclusión de PauliDocument6 pagesPrincipio de exclusión de PauliAlexGarciaPas encore d'évaluation
- 3 - Aplicaciones Prácticas de La Óptica GeométricaDocument10 pages3 - Aplicaciones Prácticas de La Óptica GeométricaThomas Sanhueza Vásquez50% (2)
- ANALOGIASDocument5 pagesANALOGIASJose Isaias Moo PistePas encore d'évaluation
- Keily Barragan-30176 - 73Document11 pagesKeily Barragan-30176 - 73keily barraganPas encore d'évaluation
- La Esfera de Pascal - EnsayoDocument1 pageLa Esfera de Pascal - EnsayoAlicia AvilaPas encore d'évaluation
- Introducción Concepto de FuncionDocument20 pagesIntroducción Concepto de Funcionkristes92Pas encore d'évaluation
- La Historia Del Cálculo IntegralDocument6 pagesLa Historia Del Cálculo IntegralMarcos PBPas encore d'évaluation
- La Física Cuántica y El DestinoDocument4 pagesLa Física Cuántica y El DestinokzadorrPas encore d'évaluation
- CFS ES4 1P U4 PDFDocument20 pagesCFS ES4 1P U4 PDFJorge Vazkz ArkoxPas encore d'évaluation
- Quimica Apuntes Serie 3 1PDocument12 pagesQuimica Apuntes Serie 3 1PZoe AsconaPas encore d'évaluation
- Escenario NaturalDocument33 pagesEscenario NaturalVanessa LrPas encore d'évaluation
- Dinamica en FisicaDocument27 pagesDinamica en FisicaWay Guz PuertaPas encore d'évaluation
- Leptones y QuarksDocument9 pagesLeptones y Quarksraul_icpPas encore d'évaluation
- Inteligencia de Enjambre - WikipediaDocument8 pagesInteligencia de Enjambre - WikipediaRicardo VillalongaPas encore d'évaluation
- Normas Apa 7ma EdicionDocument16 pagesNormas Apa 7ma EdicionAklider Córdova ChipanaPas encore d'évaluation
- Mecánica Cuántica UESDocument62 pagesMecánica Cuántica UESSergio AguilarPas encore d'évaluation
- Simon Bolivar Como EscritorDocument10 pagesSimon Bolivar Como EscritorJORGE SUAREZPas encore d'évaluation
- Infancia y Adolescencia de Simón Bolívar WilkerDocument3 pagesInfancia y Adolescencia de Simón Bolívar WilkerEduard Gabriel Gonzalez ColmenaresPas encore d'évaluation
- Campaña Del SurDocument3 pagesCampaña Del SurGamer EchetoPas encore d'évaluation
- Termodinámica Del No EquilibrioDocument8 pagesTermodinámica Del No EquilibrioBARBOSA RAFFAELLIPas encore d'évaluation
- El Efecto FotoelectricoDocument34 pagesEl Efecto FotoelectricoJOSEPH STEVEN QUEVEDO BERMEOPas encore d'évaluation
- Unidad 01 Integrada Primer PrincipioDocument15 pagesUnidad 01 Integrada Primer PrincipioAndres ZambranoPas encore d'évaluation
- Sistemas ecuaciones lineales métodos resoluciónDocument4 pagesSistemas ecuaciones lineales métodos resoluciónJose Abraham Hernandez MendezPas encore d'évaluation
- Metodologia PolyaDocument3 pagesMetodologia PolyaOscar LopezPas encore d'évaluation
- Espin ElectronicoDocument34 pagesEspin ElectronicoRichert Jesus BompartPas encore d'évaluation
- Aplicacion de Las Leyes de NewtonDocument4 pagesAplicacion de Las Leyes de NewtonConsuelo CoradoPas encore d'évaluation
- La Cuadratura de La ParabolaDocument21 pagesLa Cuadratura de La ParabolaAntonio Quintana DénizPas encore d'évaluation
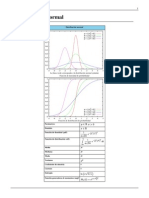
- Distribucion NormalDocument19 pagesDistribucion NormalSebastian Nieto100% (1)
- Distribución Normal - Wikipedia, La Enciclopedia LibreDocument51 pagesDistribución Normal - Wikipedia, La Enciclopedia LibreCristobal Isaac Arthieedd Vera PalaciosPas encore d'évaluation
- Distribución normal: guía completa de la campana de GaussDocument19 pagesDistribución normal: guía completa de la campana de GaussPedro PuchePas encore d'évaluation
- Distribucion Normal y Normal Reducida o EstandarDocument13 pagesDistribucion Normal y Normal Reducida o EstandarLMVVPas encore d'évaluation
- Probabilidad y estadística: un enfoque teórico-prácticoD'EverandProbabilidad y estadística: un enfoque teórico-prácticoÉvaluation : 4 sur 5 étoiles4/5 (40)
- Control PID Multivariable de Un Helicóptero de 2-GdL Utilizando Algoritmos EvolutivosDocument6 pagesControl PID Multivariable de Un Helicóptero de 2-GdL Utilizando Algoritmos EvolutivosRicardo VillalongaPas encore d'évaluation
- Varistor - WikipediaDocument2 pagesVaristor - WikipediaRicardo VillalongaPas encore d'évaluation
- Instrumentación y Control de ProcesosDocument2 pagesInstrumentación y Control de ProcesosJulian LondoñoPas encore d'évaluation
- Reglas de Oro (Electricidad) - WikipediaDocument4 pagesReglas de Oro (Electricidad) - WikipediaRicardo VillalongaPas encore d'évaluation
- Conexión Equipotencial - WikipediaDocument3 pagesConexión Equipotencial - WikipediaRicardo VillalongaPas encore d'évaluation
- Las Mejores 5 Recomendaciones en LucidchartDocument1 pageLas Mejores 5 Recomendaciones en LucidchartRicardo VillalongaPas encore d'évaluation
- Inductor - WikipediaDocument8 pagesInductor - WikipediaRicardo VillalongaPas encore d'évaluation
- Instalación EléctricaDocument8 pagesInstalación EléctricaChristian Matos de la CruzPas encore d'évaluation
- Corriente Máxima - WikipediaDocument1 pageCorriente Máxima - WikipediaRicardo VillalongaPas encore d'évaluation
- Sistemas Trifásicos - WikipediaDocument6 pagesSistemas Trifásicos - WikipediaRicardo VillalongaPas encore d'évaluation
- Sistema Monofásico - WikipediaDocument1 pageSistema Monofásico - WikipediaRicardo VillalongaPas encore d'évaluation
- Admitancia - WikipediaDocument3 pagesAdmitancia - WikipediaRicardo VillalongaPas encore d'évaluation
- Valor NominalDocument3 pagesValor NominalTyris De Los MonterosPas encore d'évaluation
- Frame - WikipediaDocument2 pagesFrame - WikipediaRicardo VillalongaPas encore d'évaluation
- Factor de Potencia - WikipediaDocument9 pagesFactor de Potencia - WikipediaRicardo VillalongaPas encore d'évaluation
- Flujo de Potencia - WikipediaDocument2 pagesFlujo de Potencia - WikipediaRicardo VillalongaPas encore d'évaluation
- Susceptancia - WikipediaDocument2 pagesSusceptancia - WikipediaRicardo VillalongaPas encore d'évaluation
- MATLABDocument4 pagesMATLABMiguel LSPas encore d'évaluation
- Función de Densidad de Probabilidad - WikipediaDocument4 pagesFunción de Densidad de Probabilidad - WikipediaRicardo VillalongaPas encore d'évaluation
- ETAP - WikipediaDocument1 pageETAP - WikipediaRicardo VillalongaPas encore d'évaluation
- Puesta A Tierra - WikipediaDocument8 pagesPuesta A Tierra - WikipediaRicardo VillalongaPas encore d'évaluation
- Raíz Del Error Cuadrático Medio - WikipediaDocument2 pagesRaíz Del Error Cuadrático Medio - WikipediaRicardo VillalongaPas encore d'évaluation
- Función Gaussiana - WikipediaDocument4 pagesFunción Gaussiana - WikipediaRicardo VillalongaPas encore d'évaluation
- Reactor en Línea - WikipediaDocument1 pageReactor en Línea - WikipediaRicardo VillalongaPas encore d'évaluation
- Ensayo de Cortocircuito - WikipediaDocument2 pagesEnsayo de Cortocircuito - WikipediaRicardo VillalongaPas encore d'évaluation
- Sistema Por Unidad - WikipediaDocument2 pagesSistema Por Unidad - WikipediaRicardo VillalongaPas encore d'évaluation
- Varianza y Desviación EstándarDocument3 pagesVarianza y Desviación EstándarRicardo VillalongaPas encore d'évaluation
- Error de Medición - WikipediaDocument4 pagesError de Medición - WikipediaRicardo VillalongaPas encore d'évaluation
- Correlación - WikipediaDocument4 pagesCorrelación - WikipediaRicardo VillalongaPas encore d'évaluation
- Guia Del Cuidado de Polinizadores de ArándanoDocument9 pagesGuia Del Cuidado de Polinizadores de ArándanomarcosanchezveramendPas encore d'évaluation
- Elaboracion de Un Filtro para Limpieza de Aguas en PecerasDocument9 pagesElaboracion de Un Filtro para Limpieza de Aguas en Peceraslezcano1290Pas encore d'évaluation
- Temario AnatomiaDocument15 pagesTemario AnatomiaThalya YanezPas encore d'évaluation
- Ensayo Salud e HigieneDocument5 pagesEnsayo Salud e HigienewilkendryPas encore d'évaluation
- Conceptos Generales Sobre ParasitologíaDocument45 pagesConceptos Generales Sobre ParasitologíaJohanGreenEyesPas encore d'évaluation
- Óxidos y PeróxidosDocument22 pagesÓxidos y PeróxidosPeqkeñalovii EsteliitaPas encore d'évaluation
- OrtotoluidinaDocument6 pagesOrtotoluidinaRodrigo GomezPas encore d'évaluation
- Freire Zent2007Document75 pagesFreire Zent2007giomicaPas encore d'évaluation
- 22010064633Document1 page22010064633Gary Miller FelizPas encore d'évaluation
- Ecología de Las ComunidadesDocument22 pagesEcología de Las ComunidadesAdrián MaciasPas encore d'évaluation
- ANALISIS CUENTO LAS ZAPATILLAS ROJASDocument5 pagesANALISIS CUENTO LAS ZAPATILLAS ROJASleon2105Pas encore d'évaluation
- Personalidad, Temperamento y CaracterDocument10 pagesPersonalidad, Temperamento y CaracterMaríaJosé HerreraPas encore d'évaluation
- Importancia de La BiósferaDocument3 pagesImportancia de La BiósferaTheHowling33Pas encore d'évaluation
- Vievienda Experimental PreviDocument39 pagesVievienda Experimental PreviAndy SisniegasPas encore d'évaluation
- Agar Deshidratado Papa DextrosaDocument3 pagesAgar Deshidratado Papa DextrosaDebby Bowie MizukiPas encore d'évaluation
- Biología 9° (2) - 1Document10 pagesBiología 9° (2) - 1LUNA VALENTINA FERNANDEZ PINEDAPas encore d'évaluation
- Cuadernillo Biologia Enero 1BDocument10 pagesCuadernillo Biologia Enero 1BMaria de Jesus Perez OrtizPas encore d'évaluation
- Estrés LaboralDocument130 pagesEstrés LaboralLizandro Amador COAQUIRA COAQUIRAPas encore d'évaluation
- Resumen Cap 6 Memoria OperativaDocument9 pagesResumen Cap 6 Memoria OperativaJuan FernándezPas encore d'évaluation
- EugenolDocument11 pagesEugenolHelen UHPas encore d'évaluation
- Evolución de La Especie HumanaDocument5 pagesEvolución de La Especie HumanaJuan ReyesPas encore d'évaluation
- Rheinberger - 2015 - Partículas Citoplásmicas. Trayectoria de Un Objeto Científico PDFDocument18 pagesRheinberger - 2015 - Partículas Citoplásmicas. Trayectoria de Un Objeto Científico PDFIesus GudiñoPas encore d'évaluation
- AlternativadigitalDocument6 pagesAlternativadigitalLuisSalasPas encore d'évaluation
- Normas de Rotulación y Señalización para La Manipulación - OriginalDocument99 pagesNormas de Rotulación y Señalización para La Manipulación - OriginalJuan Gabriel Butrón CespedesPas encore d'évaluation
- Principales Razas PorcinasDocument45 pagesPrincipales Razas PorcinasEstefania Conde AndradePas encore d'évaluation
- SemanaDocument10 pagesSemanaBryan Tejada SaenzPas encore d'évaluation
- Madres TóxicasDocument4 pagesMadres Tóxicasflavy20100% (1)
- Taller de QuimicaDocument3 pagesTaller de QuimicaCarolinaPas encore d'évaluation
- Tarea 3-MicroDocument4 pagesTarea 3-Micronathalia shekPas encore d'évaluation
- Resumen Del Vídeo Una Voz en La Fuga CósmicaDocument5 pagesResumen Del Vídeo Una Voz en La Fuga CósmicaJESSICA GUAMAN100% (1)