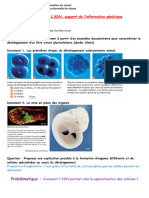
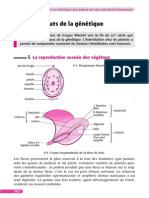
Vous aimerez peut-être aussi
- GENETIQUE FONDAMENTALE - Nature D - Tériel Génétique - MoodleDocument7 pagesGENETIQUE FONDAMENTALE - Nature D - Tériel Génétique - MoodleGh7Pas encore d'évaluation
- Le Matériel GénétiqueDocument14 pagesLe Matériel GénétiquenasroddinePas encore d'évaluation
- Matériel GénétiqueDocument7 pagesMatériel GénétiquenasroddinePas encore d'évaluation
- Unité 2 1SMFDocument8 pagesUnité 2 1SMFHamza AmjahdiPas encore d'évaluation
- Notion de L Information Genetique ActivitesDocument12 pagesNotion de L Information Genetique ActivitesOussama El meknassiPas encore d'évaluation
- Biologie Moléculaire - 3IE - 2022Document193 pagesBiologie Moléculaire - 3IE - 2022Espoir De la ViePas encore d'évaluation
- 1 Introduction Part 1Document7 pages1 Introduction Part 1Djã HîDāPas encore d'évaluation
- Chap 3 ADN 2024 2nd2 24.11Document7 pagesChap 3 ADN 2024 2nd2 24.11wildaman822Pas encore d'évaluation
- Diapo Chapitre 2 Transfert Horiz EndosymbioseDocument65 pagesDiapo Chapitre 2 Transfert Horiz EndosymbioseAbgamer976Pas encore d'évaluation
- Cours Génétique LPSVT S3Document87 pagesCours Génétique LPSVT S3samifilol703Pas encore d'évaluation
- La nature de l'informtion génétiqueDocument5 pagesLa nature de l'informtion génétiqueaanterzakariaPas encore d'évaluation
- Des Débuts de La Génétique Aux Enjeux ActuelsDocument8 pagesDes Débuts de La Génétique Aux Enjeux ActuelsJosé Ahanda NguiniPas encore d'évaluation
- Cours L1 Elts de Bio Mol Étud (Cours 20-21)Document119 pagesCours L1 Elts de Bio Mol Étud (Cours 20-21)YVESPas encore d'évaluation
- Cours Biologie Moleculaire NehDocument118 pagesCours Biologie Moleculaire NehDjena DiakitePas encore d'évaluation
- GénétiqueDocument150 pagesGénétiquefranck brice bado100% (1)
- L'expression de L'information GénétiqueDocument15 pagesL'expression de L'information GénétiqueAMINE 16Pas encore d'évaluation
- Notion de Linfo Géné Et Sonex SHDocument14 pagesNotion de Linfo Géné Et Sonex SHhajar hajoraPas encore d'évaluation
- Chapitre 3 Les Transferts Génétique La Transformation Et La TransductionDocument8 pagesChapitre 3 Les Transferts Génétique La Transformation Et La TransductionKeitaPas encore d'évaluation
- Analyse GénomiqueDocument31 pagesAnalyse GénomiquemokermiPas encore d'évaluation
- Cours Biologie Tse 2020-2021-1Document99 pagesCours Biologie Tse 2020-2021-1Oury Diaby Diaby100% (1)
- Professor GÜ Nther Enderlein DoctorDocument6 pagesProfessor GÜ Nther Enderlein DoctorvoviPas encore d'évaluation
- Activité 7 Version 2024Document2 pagesActivité 7 Version 2024Ahmedrayane NamlyPas encore d'évaluation
- Notion de L Information Genetique Cours 2 3Document8 pagesNotion de L Information Genetique Cours 2 3Malak MalakchakdiPas encore d'évaluation
- Al7sn02tdpa0112 Sequence 04Document104 pagesAl7sn02tdpa0112 Sequence 04A100% (1)
- Cours 01 IntroductionDocument28 pagesCours 01 Introductionjames deyPas encore d'évaluation
- 4°-B3-Activités 1-2-CORRECTIONDocument8 pages4°-B3-Activités 1-2-CORRECTIONberek leroyPas encore d'évaluation
- La Génétique: Encadré Par: Présenter Par: Mme - AthmaniDocument10 pagesLa Génétique: Encadré Par: Présenter Par: Mme - AthmaniFatima ZohraPas encore d'évaluation
- Csvt-206 TP Le Role de L AdnDocument6 pagesCsvt-206 TP Le Role de L AdnKhabtane AbdelhamidPas encore d'évaluation
- Cours - Unite I - Lois Statistiques - Lydex - 2020 - 2021 - Copie Prof - 2eme - SMDocument31 pagesCours - Unite I - Lois Statistiques - Lydex - 2020 - 2021 - Copie Prof - 2eme - SMhamza.aitounrar.96Pas encore d'évaluation
- Génétique Bactérienne Les Échanges Génétiques, Évolution, Plasticité Des Génomes Bactériens PDFDocument13 pagesGénétique Bactérienne Les Échanges Génétiques, Évolution, Plasticité Des Génomes Bactériens PDFkerkour-abd1523Pas encore d'évaluation
- Cours l1 Bio Mol Etudiant Bon 1 PDFDocument90 pagesCours l1 Bio Mol Etudiant Bon 1 PDFKOUADIO SALOMONPas encore d'évaluation
- genome 1Document8 pagesgenome 1mathildecarcenacPas encore d'évaluation
- Genome de MithocondrieDocument8 pagesGenome de MithocondrieNana LabellePas encore d'évaluation
- Cours 1Document24 pagesCours 1Hikari KazuePas encore d'évaluation
- BIO 110 RévisionsDocument2 pagesBIO 110 RévisionsKOFFI JOY AMEDJONEKOUPas encore d'évaluation
- De L - ADN À La Protéine - EducloudDocument92 pagesDe L - ADN À La Protéine - EducloudsananasPas encore d'évaluation
- ProgrammeDocument16 pagesProgrammeWalsy Sissoko100% (1)
- Biologie Ter Sciences ExpDocument101 pagesBiologie Ter Sciences ExpSawoulou celest Dopavogui100% (6)
- 2019 Cours GénetiqueDocument188 pages2019 Cours GénetiquedetobPas encore d'évaluation
- Chap2 PapierDocument26 pagesChap2 PapierNoahPas encore d'évaluation
- Génome BactérienDocument7 pagesGénome BactérienFati HaPas encore d'évaluation
- Annatut27 UE2 Biologie Cellulaire 2012 2013Document51 pagesAnnatut27 UE2 Biologie Cellulaire 2012 2013Mohamed hicham AllamPas encore d'évaluation
- Génétique BactérienneDocument14 pagesGénétique BactérienneSeryne OukrifPas encore d'évaluation
- Hérédité Cytoplasmique PDFDocument22 pagesHérédité Cytoplasmique PDFcoursenligne.lille1100% (4)
- La Conjugaison 2 - Copie - Etudts - CopieDocument8 pagesLa Conjugaison 2 - Copie - Etudts - CopieMemoire 2223Pas encore d'évaluation
- Theme 1Document19 pagesTheme 1fatimabenelallidPas encore d'évaluation
- Genie GénétiqueDocument61 pagesGenie GénétiqueHÄ ÝÄŤ100% (3)
- CM de Génie G Et de BioMol de L3 SVT 2013Document18 pagesCM de Génie G Et de BioMol de L3 SVT 2013Ester KouakouPas encore d'évaluation
- Épigénétique Et Memoire CellulaireDocument10 pagesÉpigénétique Et Memoire CellulaireAndreea SchiauPas encore d'évaluation
- 1spé T1 Chapitre3 CoursDocument8 pages1spé T1 Chapitre3 Coursabdirahman abdillahiPas encore d'évaluation
- Polycopier Génétique Des EucaryotesDocument72 pagesPolycopier Génétique Des EucaryotessabrinaPas encore d'évaluation
- Medecine-Intro Genetique MonohybridismeDocument23 pagesMedecine-Intro Genetique MonohybridismedzsergioPas encore d'évaluation
- Cours TSE Partie1vf-1Document14 pagesCours TSE Partie1vf-1Jœël Crèspœ KhæmænœPas encore d'évaluation
- 1-Historique de L ADNDocument11 pages1-Historique de L ADNal mounir alaouiPas encore d'évaluation
- Bilans 3 ThemesDocument20 pagesBilans 3 ThemesTimPas encore d'évaluation
- Theme 1 CHP 2 La Diversification Du Vivant Sans Reproduction Sexuee 2024Document9 pagesTheme 1 CHP 2 La Diversification Du Vivant Sans Reproduction Sexuee 2024Amar AliPas encore d'évaluation
- Biologie p143Document16 pagesBiologie p143jenensjsjPas encore d'évaluation
- act-part-iiii-c-corDocument2 pagesact-part-iiii-c-corkenzo.miclot202Pas encore d'évaluation
- Mes gènes, mon identité ?: Comprendre la génétique et ses enjeuxD'EverandMes gènes, mon identité ?: Comprendre la génétique et ses enjeuxPas encore d'évaluation
- Génétique: Les Grands Articles d'UniversalisD'EverandGénétique: Les Grands Articles d'UniversalisPas encore d'évaluation
- Kéfir de FruitsDocument1 pageKéfir de FruitsdominiquePas encore d'évaluation
- Kombucha - Harald TietzeDocument121 pagesKombucha - Harald Tietzedominique67% (3)
- Syndrome Des Micro OndesDocument16 pagesSyndrome Des Micro OndeseluesiomaPas encore d'évaluation
- Immaculee Conception de La Tres Sainte ViergeDocument5 pagesImmaculee Conception de La Tres Sainte ViergedominiquePas encore d'évaluation
- Planche Pour Pendule SEMAINEDocument1 pagePlanche Pour Pendule SEMAINEdominiquePas encore d'évaluation
- Zohar - Le Corpus Zoharique (C. Mopsik)Document31 pagesZohar - Le Corpus Zoharique (C. Mopsik)3am100% (1)
- TD - Biochimie BG2 PDFDocument22 pagesTD - Biochimie BG2 PDFMohamed Dahmane100% (2)
- Cours Chapitre 2 Membrane PlasmiqueDocument5 pagesCours Chapitre 2 Membrane PlasmiqueHou TrtyPas encore d'évaluation
- TD 1 BMGG 2024Document4 pagesTD 1 BMGG 2024Abbou BelkaisPas encore d'évaluation
- L PRA 1E026 Biologie Preventive Predictive Tarifs Analyses SpecialiseesDocument2 pagesL PRA 1E026 Biologie Preventive Predictive Tarifs Analyses SpecialiseesMounir HamitiPas encore d'évaluation
- RibosomesDocument9 pagesRibosomesBël RoumiPas encore d'évaluation
- Partie I: QCM (Questions À Choix Multiple) ................................. 7Document1 pagePartie I: QCM (Questions À Choix Multiple) ................................. 7nehemie nwayPas encore d'évaluation
- COURS 3 RéplicationDocument27 pagesCOURS 3 RéplicationHikari KazuePas encore d'évaluation
- TD BioreacteurDocument48 pagesTD Bioreacteurlola benr83% (6)
- Réticulum Endoplasmique OranDocument7 pagesRéticulum Endoplasmique OranHaitam El OuahabiPas encore d'évaluation
- TD BioinformatiqueDocument11 pagesTD Bioinformatiqueread cantonaPas encore d'évaluation
- 2012 01 26 - UE Nutrition - Biochimie - Mengual - Cholestérol PDFDocument10 pages2012 01 26 - UE Nutrition - Biochimie - Mengual - Cholestérol PDFZahraBenzakourPas encore d'évaluation
- ÉlectroDocument13 pagesÉlectroOTOTEPas encore d'évaluation
- Metabolisme Des Glucides PR SAADI OUISLIM A.SDocument13 pagesMetabolisme Des Glucides PR SAADI OUISLIM A.SDemba Tahirou DIOPPas encore d'évaluation
- Acides AminésDocument131 pagesAcides AminésLaira ImiPas encore d'évaluation
- Enzymologie 10Document84 pagesEnzymologie 10Dr.Zakaria MFTPas encore d'évaluation
- 8 - 2021 PR Bouhsain Structure Lipides PDFDocument114 pages8 - 2021 PR Bouhsain Structure Lipides PDFmademoisellefirdaousPas encore d'évaluation
- Td3 Prodites Biochimie Proteines Med1Document23 pagesTd3 Prodites Biochimie Proteines Med1mt6341373100% (1)
- Biochimie. Protéines PDFDocument70 pagesBiochimie. Protéines PDFBrahim Kotto Abdel-azizPas encore d'évaluation
- Mutation Et Mécanismes de Réparation de LDocument9 pagesMutation Et Mécanismes de Réparation de LFati HaPas encore d'évaluation
- PR Zaafrani Intro À La Biologie CellulaireDocument24 pagesPR Zaafrani Intro À La Biologie CellulaireLatif SsayPas encore d'évaluation
- 09-Les Lipides Complexes Ou HeterolipidesDocument12 pages09-Les Lipides Complexes Ou HeterolipidesBook HunterPas encore d'évaluation
- Cours de Chimie Organique Sur Les Acides AminésDocument13 pagesCours de Chimie Organique Sur Les Acides AminésKone KouweltonPas encore d'évaluation
- Replication de l'ADN (1) - 020827Document29 pagesReplication de l'ADN (1) - 020827nonamethe427Pas encore d'évaluation
- Biochimie MetaboliqueDocument32 pagesBiochimie Metabolique[AE]88% (8)
- Chapitre 7 - Les Acides AminésDocument7 pagesChapitre 7 - Les Acides AminésBeatrice Florin100% (1)
- Devoir de Contrôle n3 2010 2011said Mounir1mhamdiaDocument9 pagesDevoir de Contrôle n3 2010 2011said Mounir1mhamdiaChokri BesbesPas encore d'évaluation
- 16 Detection PCRDocument2 pages16 Detection PCRMed KhezPas encore d'évaluation
- Peptides Et ProtéinesDocument28 pagesPeptides Et ProtéinesFanny GrouxPas encore d'évaluation
- Cinetique Enzyme 2 PDFDocument13 pagesCinetique Enzyme 2 PDFMer OuanePas encore d'évaluation
- 51 s2.0 S115519842042360XDocument18 pages51 s2.0 S115519842042360XMoncef PechaPas encore d'évaluation