Vous aimerez peut-être aussi
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- Sickle Cell AnemiaDocument13 pagesSickle Cell Anemiamayra100% (1)
- Elementary SurveyingDocument19 pagesElementary SurveyingJefferson EscobidoPas encore d'évaluation
- Units 6-10 Review TestDocument20 pagesUnits 6-10 Review TestCristian Patricio Torres Rojas86% (14)
- In Christ Alone My Hope Is FoundDocument9 pagesIn Christ Alone My Hope Is FoundJessie JessPas encore d'évaluation
- 3er Grado - DMPA 05 - ACTIVIDAD DE COMPRENSION LECTORA - UNIT 2 - CORRECCIONDocument11 pages3er Grado - DMPA 05 - ACTIVIDAD DE COMPRENSION LECTORA - UNIT 2 - CORRECCIONANDERSON BRUCE MATIAS DE LA SOTAPas encore d'évaluation
- Spyderco Product Guide - 2016Document154 pagesSpyderco Product Guide - 2016marceudemeloPas encore d'évaluation
- Unit 2 Foundations of CurriculumDocument20 pagesUnit 2 Foundations of CurriculumKainat BatoolPas encore d'évaluation
- Entity-Level Controls Fraud QuestionnaireDocument8 pagesEntity-Level Controls Fraud QuestionnaireKirby C. LoberizaPas encore d'évaluation
- Afia Rasheed Khan V. Mazharuddin Ali KhanDocument6 pagesAfia Rasheed Khan V. Mazharuddin Ali KhanAbhay GuptaPas encore d'évaluation
- Task Basis JurisprudenceDocument10 pagesTask Basis JurisprudenceKerwin LeonidaPas encore d'évaluation
- Pakistan List of Approved Panel PhysicianssDocument5 pagesPakistan List of Approved Panel PhysicianssGulzar Ahmad RawnPas encore d'évaluation
- 4.3.6. Changing The Parameters of A Volume GroupDocument2 pages4.3.6. Changing The Parameters of A Volume GroupNitesh KohliPas encore d'évaluation
- International Human Rights LawDocument21 pagesInternational Human Rights LawRea Nica GeronaPas encore d'évaluation
- Donor S Tax Exam AnswersDocument6 pagesDonor S Tax Exam AnswersAngela Miles DizonPas encore d'évaluation
- Mathematics in The Primary Curriculum: Uncorrected Proof - For Lecturer Review OnlyDocument12 pagesMathematics in The Primary Curriculum: Uncorrected Proof - For Lecturer Review OnlyYekeen Luqman LanrePas encore d'évaluation
- Linking and Relocation - Stacks - Procedures - MacrosDocument11 pagesLinking and Relocation - Stacks - Procedures - MacrosJeevanantham GovindarajPas encore d'évaluation
- Muller-Lyer IllusionDocument3 pagesMuller-Lyer Illusionsara VermaPas encore d'évaluation
- Measures-English, Metric, and Equivalents PDFDocument1 pageMeasures-English, Metric, and Equivalents PDFluz adolfoPas encore d'évaluation
- IUGRDocument4 pagesIUGRMichael Spica RampangileiPas encore d'évaluation
- Mathematicaleconomics PDFDocument84 pagesMathematicaleconomics PDFSayyid JifriPas encore d'évaluation
- Endocrine System Unit ExamDocument3 pagesEndocrine System Unit ExamCHRISTINE JULIANEPas encore d'évaluation
- E 18 - 02 - Rte4ltay PDFDocument16 pagesE 18 - 02 - Rte4ltay PDFvinoth kumar SanthanamPas encore d'évaluation
- Practice Makes Perfect Basic Spanish Premium Third Edition Dorothy Richmond All ChapterDocument67 pagesPractice Makes Perfect Basic Spanish Premium Third Edition Dorothy Richmond All Chaptereric.temple792100% (3)
- Biblehub Com Commentaries Matthew 3 17 HTMDocument21 pagesBiblehub Com Commentaries Matthew 3 17 HTMSorin TrimbitasPas encore d'évaluation
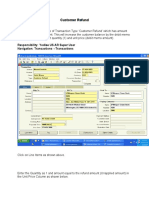
- Customer Refund: Responsibility: Yodlee US AR Super User Navigation: Transactions TransactionsDocument12 pagesCustomer Refund: Responsibility: Yodlee US AR Super User Navigation: Transactions TransactionsAziz KhanPas encore d'évaluation
- 1sebastian Vs CalisDocument6 pages1sebastian Vs CalisRai-chan Junior ÜPas encore d'évaluation
- Million-Day Gregorian-Julian Calendar - NotesDocument10 pagesMillion-Day Gregorian-Julian Calendar - Notesraywood100% (1)
- Strategi Pencegahan Kecelakaan Di PT VALE Indonesia Presentation To FPP Workshop - APKPI - 12102019Document35 pagesStrategi Pencegahan Kecelakaan Di PT VALE Indonesia Presentation To FPP Workshop - APKPI - 12102019Eko Maulia MahardikaPas encore d'évaluation
- Chan Sophia ResumeDocument1 pageChan Sophia Resumeapi-568119902Pas encore d'évaluation
- Flow ChemistryDocument6 pagesFlow Chemistryrr1819Pas encore d'évaluation