Vous aimerez peut-être aussi
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- EN1201: Introductory Mathematics: University of Colombo, Sri LankaDocument6 pagesEN1201: Introductory Mathematics: University of Colombo, Sri LankaJanaka Bandara100% (1)
- Simplifying Absolute Value ProblemsDocument8 pagesSimplifying Absolute Value ProblemslmlPas encore d'évaluation
- C.7 Sliding ControlDocument7 pagesC.7 Sliding ControlNhật NguyễnPas encore d'évaluation
- ONeil7 6th Vectors Vector SpacesDocument68 pagesONeil7 6th Vectors Vector Spaces김민성Pas encore d'évaluation
- SHERPA - An Efficient and Robust Optimization/Search AlgorithmDocument3 pagesSHERPA - An Efficient and Robust Optimization/Search AlgorithmsantiagoPas encore d'évaluation
- Unit 2 ReviewDocument8 pagesUnit 2 ReviewSalvador NunezPas encore d'évaluation
- Econometrics Chapter 1 UNAVDocument38 pagesEconometrics Chapter 1 UNAVRachael VazquezPas encore d'évaluation
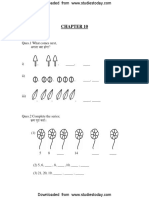
- CBSE Class 1 Maths Chapter 10 WorksheetDocument10 pagesCBSE Class 1 Maths Chapter 10 WorksheetSUBHAPas encore d'évaluation
- Lab Plan 5: Statistics and Probability: Describing A Single Set of DataDocument19 pagesLab Plan 5: Statistics and Probability: Describing A Single Set of DataSteffen ColePas encore d'évaluation
- J.P. Rizal Ext. West Rembo, Makati CityDocument2 pagesJ.P. Rizal Ext. West Rembo, Makati CityQ Annang TomanggongPas encore d'évaluation
- Stat NM Quen BankDocument11 pagesStat NM Quen BankSuresh BiradarPas encore d'évaluation
- M2 - Density and Completeness of RDocument1 pageM2 - Density and Completeness of RJason CostanzoPas encore d'évaluation
- Equn Bulletin BoardDocument8 pagesEqun Bulletin Boardapi-297021169Pas encore d'évaluation
- Chapter 3Document39 pagesChapter 3api-3729261Pas encore d'évaluation
- Johor Smktinggikluang Mathst p1 2015 QaDocument5 pagesJohor Smktinggikluang Mathst p1 2015 QalingbooPas encore d'évaluation
- Statistical Methods in HYDROLOGY-HaanDocument516 pagesStatistical Methods in HYDROLOGY-Haan3mmahmoodea100% (7)
- Topic5 Linear TransformationsDocument25 pagesTopic5 Linear TransformationsFilipus Boby Setiawan BudimanPas encore d'évaluation
- Systems Graphing Si 1 AnswersDocument1 pageSystems Graphing Si 1 AnswersDa'Mya GeorgePas encore d'évaluation
- Indian MathematiciansDocument47 pagesIndian MathematiciansS SunnyPas encore d'évaluation
- Sol AssignmentDocument5 pagesSol AssignmentLeia SeunghoPas encore d'évaluation
- Maths Chapter 16 Notebook WorkDocument3 pagesMaths Chapter 16 Notebook Workjaisurya14107Pas encore d'évaluation
- Questionpaper Paper1F January2018 IGCSE Edexcel MathsDocument24 pagesQuestionpaper Paper1F January2018 IGCSE Edexcel MathsmoncyzachariahPas encore d'évaluation
- Math10 Quarter1 Module 3 Melc 6Document12 pagesMath10 Quarter1 Module 3 Melc 6Jhiemalyn RonquilloPas encore d'évaluation
- Bernard P. Zeigler, Alexandre Muzy, Ernesto Kofman - Theory of Modeling and Simulation-Academic Press (2019) PDFDocument674 pagesBernard P. Zeigler, Alexandre Muzy, Ernesto Kofman - Theory of Modeling and Simulation-Academic Press (2019) PDFSebastián Cáceres G100% (4)
- Lab # 6 Time Response AnalysisDocument10 pagesLab # 6 Time Response AnalysisFahad AneebPas encore d'évaluation
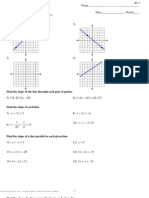
- AA - Slope Foldable AssignmentDocument4 pagesAA - Slope Foldable Assignmentmom4larsensPas encore d'évaluation
- PE2113-Chapter 9 - Center of Gravity and Centroid - DraftDocument18 pagesPE2113-Chapter 9 - Center of Gravity and Centroid - DraftMohammed AlkhalifaPas encore d'évaluation
- ITE3711 Lecture1.3 Operators 20230906Document18 pagesITE3711 Lecture1.3 Operators 20230906zainoff445Pas encore d'évaluation
- Simpson's Integration RuleDocument2 pagesSimpson's Integration RulerodwellheadPas encore d'évaluation
- Source Code 1Document40 pagesSource Code 1dinesh181899Pas encore d'évaluation