Vous aimerez peut-être aussi
- Cours Cloud Et VirtualisationDocument52 pagesCours Cloud Et Virtualisationelahmadi cheikhPas encore d'évaluation
- TP SVMDocument7 pagesTP SVMmarwaPas encore d'évaluation
- TP 1Document6 pagesTP 1Mohamed JlassiPas encore d'évaluation
- INF365 Chap4 22Document10 pagesINF365 Chap4 22Armando Franck NguePas encore d'évaluation
- TP Cryptographie PGP v1.0Document7 pagesTP Cryptographie PGP v1.0Yunes iFriPas encore d'évaluation
- Routage Statique 2Document8 pagesRoutage Statique 2gamee eerPas encore d'évaluation
- Application de La Methode Adaboost A La Reconnaissance Automatique de La ParoleDocument8 pagesApplication de La Methode Adaboost A La Reconnaissance Automatique de La ParoleWalidAdrarPas encore d'évaluation
- TP N1 Sec OSDocument4 pagesTP N1 Sec OSSalim AssalamPas encore d'évaluation
- Rappel - Le Routage StatiqueDocument17 pagesRappel - Le Routage StatiqueSimo Sirage DdinePas encore d'évaluation
- 1 Introduction PDFDocument23 pages1 Introduction PDFAzerPas encore d'évaluation
- CV Matthieu - Lopez PDFDocument12 pagesCV Matthieu - Lopez PDFAnonymous aN2NPgKPas encore d'évaluation
- Machine Learning 2 PDFDocument18 pagesMachine Learning 2 PDFgfgfPas encore d'évaluation
- TP SpinDocument4 pagesTP SpinAnonymous JJR7TduPas encore d'évaluation
- Intelligence Artificielle - TD N 1Document1 pageIntelligence Artificielle - TD N 1Gabin PADONOUPas encore d'évaluation
- Rapport - Data Processing in Distributed SystemsDocument27 pagesRapport - Data Processing in Distributed SystemsEL MAMOUN ABDELLAHPas encore d'évaluation
- Tutoriel Adaboost Haar LBP Face DetectionDocument27 pagesTutoriel Adaboost Haar LBP Face Detectiondahman160% (1)
- Correction ChatDocument2 pagesCorrection Chatyves1ndriPas encore d'évaluation
- TD EC Big DataDocument3 pagesTD EC Big DataMme et Mr LafonPas encore d'évaluation
- TD3 Big DataDocument2 pagesTD3 Big DataMohamed Sidi BrahimPas encore d'évaluation
- Cours ProgrammationDocument62 pagesCours ProgrammationtalainiPas encore d'évaluation
- TP Acp TempDocument3 pagesTP Acp TempNadia SahraouiPas encore d'évaluation
- TP Pki 2.1Document12 pagesTP Pki 2.1bioine100% (1)
- TP 5Document25 pagesTP 5nafissa bridahPas encore d'évaluation
- tp3 CorrDocument6 pagestp3 CorrDolores AbernathyPas encore d'évaluation
- 5 Régression Logistique Et Algorithmes de ClassificationDocument49 pages5 Régression Logistique Et Algorithmes de Classificationyoussefbenfrija25Pas encore d'évaluation
- Vinel Slimane TP Routage Cisco 2Document52 pagesVinel Slimane TP Routage Cisco 2AshràfCasawiAchrafPas encore d'évaluation
- Algorithme Random ForestDocument32 pagesAlgorithme Random ForestMANAL ESSALMOUNIPas encore d'évaluation
- Data Science - Introduction Au Machine Learning PDFDocument1 pageData Science - Introduction Au Machine Learning PDFMIMKANPas encore d'évaluation
- Kivy FRDocument23 pagesKivy FRSORO MOISE la fouinePas encore d'évaluation
- TD dw1Document14 pagesTD dw1Arsene PendaPas encore d'évaluation
- 1 Ch1 Introduction À MLDocument78 pages1 Ch1 Introduction À MLons nouiliPas encore d'évaluation
- TP2 - HDFS - Etudiants (Copy)Document4 pagesTP2 - HDFS - Etudiants (Copy)hahaPas encore d'évaluation
- Tp4: Sharding Sur MongodbDocument7 pagesTp4: Sharding Sur MongodbIam MePas encore d'évaluation
- Compte Rendu 2: Les ThreadsDocument7 pagesCompte Rendu 2: Les ThreadsABID HananePas encore d'évaluation
- Algorithmesderecherche 160306125009Document109 pagesAlgorithmesderecherche 160306125009Islam HaffiedPas encore d'évaluation
- Mif18 2015 MapreduceDocument4 pagesMif18 2015 MapreduceAnonymous 1P2S4tbMPas encore d'évaluation
- Chiffrement de HillDocument2 pagesChiffrement de HillshylamoPas encore d'évaluation
- Chapitre2 Hadoop MapReduceDocument28 pagesChapitre2 Hadoop MapReduceAmen MhamdiPas encore d'évaluation
- Les Defenses MateriellesDocument11 pagesLes Defenses MateriellesJean Louis KacouPas encore d'évaluation
- Corrige GL 2021Document2 pagesCorrige GL 2021PapiPas encore d'évaluation
- TP SVMDocument2 pagesTP SVMChafik BerdjouhPas encore d'évaluation
- Chap1-Ingénierie Des donnéesEnseigne2021StudentsDocument86 pagesChap1-Ingénierie Des donnéesEnseigne2021StudentsRiadh Abdelfattah100% (1)
- Présentation de System ExpertDocument30 pagesPrésentation de System ExpertAness OrichaPas encore d'évaluation
- Projets IADocument2 pagesProjets IADriss AabourPas encore d'évaluation
- TP2 Virtual BoxDocument8 pagesTP2 Virtual Boxdayno_majPas encore d'évaluation
- TD01 - Fondements IADocument2 pagesTD01 - Fondements IAAnes ElmouaddebPas encore d'évaluation
- Rapport Du PFEDocument39 pagesRapport Du PFEtarik oumeslakhtPas encore d'évaluation
- Les Threads en JAVADocument17 pagesLes Threads en JAVAmoualek adlenePas encore d'évaluation
- Cours D'algo & Prog ParallèleDocument76 pagesCours D'algo & Prog ParallèleMinasquin SokombePas encore d'évaluation
- Deepmath - Mathématiques (Simples) Des Réseaux de Neurones (Pas Trop Compliqués) : Algorithmes Et MathématiquesDocument283 pagesDeepmath - Mathématiques (Simples) Des Réseaux de Neurones (Pas Trop Compliqués) : Algorithmes Et MathématiquesgilouPas encore d'évaluation
- Programmation ConcurenteDocument74 pagesProgrammation Concurenteikhou08Pas encore d'évaluation
- 2 Agent Et SmaDocument66 pages2 Agent Et SmaTsiory HeriniavoPas encore d'évaluation
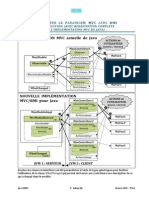
- TD MVC Pour RMIDocument6 pagesTD MVC Pour RMIPooopoPas encore d'évaluation
- Chapitre 3 Système ExpertDocument62 pagesChapitre 3 Système ExpertSayed BenslimanePas encore d'évaluation
- Cours Intelligence Artificielle 22Document99 pagesCours Intelligence Artificielle 22Hamza NasriPas encore d'évaluation
- TP Sécurité - CryptographieDocument16 pagesTP Sécurité - Cryptographietay ssirPas encore d'évaluation
- Présentation Du Lanagae Promela PDFDocument27 pagesPrésentation Du Lanagae Promela PDFMoncef MezouarPas encore d'évaluation
- CH5 - CH6 - Synchronisation de Processus (1ère Partie)Document33 pagesCH5 - CH6 - Synchronisation de Processus (1ère Partie)Dev ImadPas encore d'évaluation
- Rapport GL PERTDocument11 pagesRapport GL PERTson.600Pas encore d'évaluation
- TP Gestion de Projet - MasterDocument6 pagesTP Gestion de Projet - Masterson.600Pas encore d'évaluation
- Cours 2Document21 pagesCours 2son.600Pas encore d'évaluation
- Cahiers de Charge D - Un ProjetDocument9 pagesCahiers de Charge D - Un Projetson.600Pas encore d'évaluation
- Notice Daonil 5mg Comp Sec. B 20Document6 pagesNotice Daonil 5mg Comp Sec. B 20son.600Pas encore d'évaluation
- Notice Amoxicilline Eg 1g Comp. Dispers. B 14 2Document1 pageNotice Amoxicilline Eg 1g Comp. Dispers. B 14 2son.600Pas encore d'évaluation
- Notice Daivonex 50 G G Creme Derm. T 30gDocument4 pagesNotice Daivonex 50 G G Creme Derm. T 30gson.600Pas encore d'évaluation
- Notice Dafalgan Codeine 500mg 30mg Comp .Pelli. B 16Document1 pageNotice Dafalgan Codeine 500mg 30mg Comp .Pelli. B 16Naruto & SasukePas encore d'évaluation
- Notice Amoxicilline Eg 1g Comp. Dispers. B 14 2Document1 pageNotice Amoxicilline Eg 1g Comp. Dispers. B 14 2son.600Pas encore d'évaluation
- Notice Debridat 100mg Comp - Pelli. B 20Document4 pagesNotice Debridat 100mg Comp - Pelli. B 20son.600Pas encore d'évaluation
- Notice Biafine 0,670g 100g Emuls - Pour Applic. Cutanee T 93g (100ml) Et T 186g (200ml)Document1 pageNotice Biafine 0,670g 100g Emuls - Pour Applic. Cutanee T 93g (100ml) Et T 186g (200ml)son.600Pas encore d'évaluation
- Notice Dakin Cooper Stabilise 0,5% de Chlore Actif Sol. Usage Externe Fl. 250mlDocument5 pagesNotice Dakin Cooper Stabilise 0,5% de Chlore Actif Sol. Usage Externe Fl. 250mlson.600Pas encore d'évaluation
- 10 Agenda OCT2021Document1 page10 Agenda OCT2021son.600Pas encore d'évaluation
- 01.automate FiniDocument12 pages01.automate FinisamiiiiiPas encore d'évaluation
- TD Maziz Asma Master I VA 2Document4 pagesTD Maziz Asma Master I VA 2son.600Pas encore d'évaluation
- Notes Inf105Document105 pagesNotes Inf105son.600Pas encore d'évaluation
- Med SpeDocument3 pagesMed Speson.600Pas encore d'évaluation
- Chapitre 1Document13 pagesChapitre 1son.600Pas encore d'évaluation
- Formulaire SNDLDocument2 pagesFormulaire SNDLson.600Pas encore d'évaluation
- 035 Filtres A Particules FRDocument1 page035 Filtres A Particules FRson.600Pas encore d'évaluation
- 035 Filtres A Particules FRDocument1 page035 Filtres A Particules FRson.600Pas encore d'évaluation
- FactureDocument2 pagesFactureson.600Pas encore d'évaluation
- TD 03Document3 pagesTD 03son.600Pas encore d'évaluation
- Formulaire SNDLDocument2 pagesFormulaire SNDLson.600Pas encore d'évaluation
- 3 TD LCD 1Document1 page3 TD LCD 1son.600Pas encore d'évaluation
- D56556FR31 38 FDocument4 pagesD56556FR31 38 FAbderrahmane FrindiPas encore d'évaluation
- D56556FR31 38 FDocument4 pagesD56556FR31 38 FAbderrahmane FrindiPas encore d'évaluation
- TD 03Document3 pagesTD 03son.600Pas encore d'évaluation
- CartepuceDocument105 pagesCartepuceson.600Pas encore d'évaluation
- Compil TD2Document1 pageCompil TD2son.600Pas encore d'évaluation
- Série D'exercices N°3-3tech-Bascules-Compteurs-2012-2013-CorrectionDocument10 pagesSérie D'exercices N°3-3tech-Bascules-Compteurs-2012-2013-CorrectionMustapha LibourkiPas encore d'évaluation
- Sujet TD1Document2 pagesSujet TD1YAKRAMO DIVINEPas encore d'évaluation
- Les Erreurs StopDocument8 pagesLes Erreurs StopKill IanPas encore d'évaluation
- Etude D'active Directory - KHALID KATKOUTDocument37 pagesEtude D'active Directory - KHALID KATKOUTAbdelhak YaichePas encore d'évaluation
- SMI - S4 TPs Serie - 3 Et Correction Langage CDocument6 pagesSMI - S4 TPs Serie - 3 Et Correction Langage COmar KhalidPas encore d'évaluation
- Restauration SDocument3 pagesRestauration Sdode285Pas encore d'évaluation
- Chap2-Circuits Séquentiels PDFDocument29 pagesChap2-Circuits Séquentiels PDFaymen houchePas encore d'évaluation
- Transmission de DonneesDocument117 pagesTransmission de DonneesHachim BoubacarPas encore d'évaluation
- console de réglage ftx 117Document19 pagesconsole de réglage ftx 117johndombroPas encore d'évaluation
- Pnacw 973Document37 pagesPnacw 973Marcellin Moukilou ntsoulambaPas encore d'évaluation
- 1-Services de Stockage de Windows Server 2012 R2Document15 pages1-Services de Stockage de Windows Server 2012 R2NGOM100% (1)
- TD 1 Numérisation-Echantillonage Et Quantification2022Document4 pagesTD 1 Numérisation-Echantillonage Et Quantification2022Chawia Ith8iPas encore d'évaluation
- Annexe - Bit Octet DebitDocument2 pagesAnnexe - Bit Octet DebitFlorian RIVASPas encore d'évaluation
- TP 02Document8 pagesTP 02Sahouma SkPas encore d'évaluation
- Partie 6 Slide Livre Réseaux InformatiquesDocument41 pagesPartie 6 Slide Livre Réseaux Informatiqueschatjpt34Pas encore d'évaluation
- 4 TrisDocument123 pages4 TrisNafissaBenFtimaPas encore d'évaluation
- Les Commandes de Base en Console Lunix UbuntuDocument15 pagesLes Commandes de Base en Console Lunix UbuntuElji JalloPas encore d'évaluation
- Cours PLSQLDocument110 pagesCours PLSQLAbdelilah MtkPas encore d'évaluation
- Les VuesDocument5 pagesLes VuesHajar El atmaniPas encore d'évaluation
- Ressources Formation CiscoICND2Document193 pagesRessources Formation CiscoICND2Anselme SERIPas encore d'évaluation
- CBD 8Document5 pagesCBD 8Oussama AyachiamorPas encore d'évaluation
- tp23 CompressDocument11 pagestp23 CompressChaymaa Bjm100% (1)
- Cours API-AEG020-2016 2 FiniDocument16 pagesCours API-AEG020-2016 2 Finibasma100% (2)
- Td3-Bda-3ing-Glsi - C PDFDocument9 pagesTd3-Bda-3ing-Glsi - C PDFHamdouch BachrPas encore d'évaluation
- 3iir G3Document1 page3iir G3SabriPas encore d'évaluation
- DBA OracleDocument36 pagesDBA Oraclehajar razikPas encore d'évaluation
- Autorisations NTFSDocument4 pagesAutorisations NTFSsaidaggounPas encore d'évaluation
- 00 Ass MachineDocument6 pages00 Ass MachineazouaoufPas encore d'évaluation
- Les Codes Détecteurs Et Correcteurs Derreur - Codage InfoDocument4 pagesLes Codes Détecteurs Et Correcteurs Derreur - Codage Infomohamed amine boukariPas encore d'évaluation