Vous aimerez peut-être aussi
- Cross ValidationJackknife ApproachDocument13 pagesCross ValidationJackknife ApproachPippoPas encore d'évaluation
- An Overview of Multiple Indicator KrigingDocument7 pagesAn Overview of Multiple Indicator KrigingPratama AbimanyuPas encore d'évaluation
- CH9 Part IIDocument10 pagesCH9 Part IIFitsumPas encore d'évaluation
- Modelling Claim Frequency in Vehicle Insurance: Jiří ValeckýDocument7 pagesModelling Claim Frequency in Vehicle Insurance: Jiří ValeckýQinghua GuoPas encore d'évaluation
- Term Paper SIS Mizuno ID 1745441Document6 pagesTerm Paper SIS Mizuno ID 1745441Thiago Alduini MizunoPas encore d'évaluation
- Chapter 7 - Best+Document9 pagesChapter 7 - Best+endalkachewPas encore d'évaluation
- Skewness and kurtosis measures for non-normal distributionsDocument5 pagesSkewness and kurtosis measures for non-normal distributionsManuel CanelaPas encore d'évaluation
- Calibrating Jump-Diffusion ModelsDocument34 pagesCalibrating Jump-Diffusion ModelsrehanbtariqPas encore d'évaluation
- Distributions and Algebra of Variance: Probability, Normal, Lognormal and MoreDocument53 pagesDistributions and Algebra of Variance: Probability, Normal, Lognormal and MoreNoorPas encore d'évaluation
- Tesis - CarinaDocument17 pagesTesis - CarinaErly Zenteno TorresPas encore d'évaluation
- Probability and Statistics Formula SheetDocument2 pagesProbability and Statistics Formula SheetAl Diego FuseleroPas encore d'évaluation
- Ffjord: F - C D S R G M: REE Form Ontinuous Ynamics For Calable Eversible Enerative OdelsDocument13 pagesFfjord: F - C D S R G M: REE Form Ontinuous Ynamics For Calable Eversible Enerative Odelsjeff chenPas encore d'évaluation
- Em 602Document23 pagesEm 602Vaibhav DafalePas encore d'évaluation
- Geomechanical InterpolationDocument13 pagesGeomechanical InterpolationSumit PrajapatiPas encore d'évaluation
- Research ArticleDocument12 pagesResearch ArticleJeremi Pandapotan TogatoropPas encore d'évaluation
- An Overview of Multiple Indicator KrigingDocument7 pagesAn Overview of Multiple Indicator KrigingMr AyPas encore d'évaluation
- 40 2 Intvl Est Var PDFDocument10 pages40 2 Intvl Est Var PDFTarek MahmoudPas encore d'évaluation
- Application of The Bootstrap Method in The Site Characterization ProgramDocument14 pagesApplication of The Bootstrap Method in The Site Characterization ProgramSebestyén ZoltánPas encore d'évaluation
- Christoffersen &diebold - Cointegration and Long Horizon ForecastingDocument29 pagesChristoffersen &diebold - Cointegration and Long Horizon Forecastingkhrysttalexa3146Pas encore d'évaluation
- Probabilistic Safety Analysis under Random and Fuzzy ParametersDocument54 pagesProbabilistic Safety Analysis under Random and Fuzzy ParametersSEULI SAMPas encore d'évaluation
- The Derivation and Choice of Appropriate Test Statistic (Z, T, F and Chi-Square Test) in Research MethodologyDocument9 pagesThe Derivation and Choice of Appropriate Test Statistic (Z, T, F and Chi-Square Test) in Research MethodologyTeshomePas encore d'évaluation
- Comparing Areas Under Correlated ROC Curves Using Nonparametric ApproachDocument10 pagesComparing Areas Under Correlated ROC Curves Using Nonparametric Approachajax_telamonioPas encore d'évaluation
- Error and Data AnalysisDocument38 pagesError and Data AnalysisisiberisPas encore d'évaluation
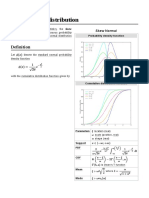
- Skew Normal DistributionDocument4 pagesSkew Normal Distributionanthony777Pas encore d'évaluation
- Variance Reduction TechniquesDocument19 pagesVariance Reduction TechniquesepuentePas encore d'évaluation
- Basics of digital image processing techniquesDocument57 pagesBasics of digital image processing techniquesDeepa RameshPas encore d'évaluation
- 2 20Micocci20Masala20BisignaniDocument17 pages2 20Micocci20Masala20Bisignaniericgyan319Pas encore d'évaluation
- Putational Methods For Local RegressionDocument16 pagesPutational Methods For Local Regressionhengky.75123014Pas encore d'évaluation
- International Biometric SocietyDocument10 pagesInternational Biometric Societyleviathan_brPas encore d'évaluation
- A comparison of Monte Carlo and FORMs methods in reliability analysis of composite structuresDocument8 pagesA comparison of Monte Carlo and FORMs methods in reliability analysis of composite structuresmin yoonjiPas encore d'évaluation
- 02-Random VariableDocument44 pages02-Random VariableBereketeab ZinabuPas encore d'évaluation
- PO 1-09 Normal Distribution PDFDocument4 pagesPO 1-09 Normal Distribution PDFshynaPas encore d'évaluation
- Bauer&Curran 2005Document28 pagesBauer&Curran 2005agoall93Pas encore d'évaluation
- Sjos 12054Document16 pagesSjos 12054唐唐Pas encore d'évaluation
- Wang, 2023, Deep Self-Consistent Learning of Local VolatilityDocument21 pagesWang, 2023, Deep Self-Consistent Learning of Local VolatilitynguyenhoangnguyenntPas encore d'évaluation
- Quantile Regression in Varying Coefficient Model of Upper Respiratory Tract Infections in Bandung CityDocument9 pagesQuantile Regression in Varying Coefficient Model of Upper Respiratory Tract Infections in Bandung Cityjack.torrance.kingPas encore d'évaluation
- Truncated Normal DistributionDocument5 pagesTruncated Normal Distributionkeisha555Pas encore d'évaluation
- Factor of safety probability failureDocument14 pagesFactor of safety probability failureSugiarYusufPas encore d'évaluation
- Steven 2Document18 pagesSteven 2Steven SergioPas encore d'évaluation
- Chapter 6 Reliability EstimationsDocument22 pagesChapter 6 Reliability EstimationsendalkachewPas encore d'évaluation
- Linear Kriging and Cokriging Procedures ExplainedDocument34 pagesLinear Kriging and Cokriging Procedures ExplainedTsamrotul JannahPas encore d'évaluation
- Equivalence Tests For The Ratio of Two Means in A 2x2 Cross-Over DesignDocument8 pagesEquivalence Tests For The Ratio of Two Means in A 2x2 Cross-Over DesignscjofyWFawlroa2r06YFVabfbajPas encore d'évaluation
- Fabio EJORDocument12 pagesFabio EJORLaura Chaves MirandaPas encore d'évaluation
- Jahanshahloo2006 (Topsis)Document10 pagesJahanshahloo2006 (Topsis)André MicoskyPas encore d'évaluation
- Kernel regression uniform rate estimation for censored data under α-mixing conditionDocument18 pagesKernel regression uniform rate estimation for censored data under α-mixing conditionGalina AlexeevaPas encore d'évaluation
- Master curve analysis of Euro fracture toughness datasetDocument31 pagesMaster curve analysis of Euro fracture toughness datasetarlyPas encore d'évaluation
- TMP 6 EEEDocument3 pagesTMP 6 EEEFrontiersPas encore d'évaluation
- Finite-Memory Universal Prediction of Individual SequencesDocument18 pagesFinite-Memory Universal Prediction of Individual SequencesperhackerPas encore d'évaluation
- Entropy Manipulation of Arbitrary Nonlinear MappingsDocument10 pagesEntropy Manipulation of Arbitrary Nonlinear Mappingsminliang2kbjPas encore d'évaluation
- EXAMPLE 2.13:: Applied Statistics Random Variables and Probability DistributionsDocument23 pagesEXAMPLE 2.13:: Applied Statistics Random Variables and Probability DistributionsAriaPas encore d'évaluation
- Comparacion GarchDocument17 pagesComparacion GarchJuan DiegoPas encore d'évaluation
- Surprising Results of Covariate AdjustmentDocument15 pagesSurprising Results of Covariate AdjustmentGuilherme MarthePas encore d'évaluation
- 19 Robust Design, Sensitivity Analysis, and Tolerance SettingDocument13 pages19 Robust Design, Sensitivity Analysis, and Tolerance SettingrogeriojuruaiaPas encore d'évaluation
- All Types of DistributionDocument7 pagesAll Types of DistributionAshikur RahmanPas encore d'évaluation
- Reliability Analysis of Circular Tunnel Under Hydrostatic Stress FieldDocument9 pagesReliability Analysis of Circular Tunnel Under Hydrostatic Stress FieldHUGIPas encore d'évaluation
- 2023 9 2 2 SahinDocument14 pages2023 9 2 2 SahinSome445GuyPas encore d'évaluation
- 1.3.6.6.1. Normal DistributionDocument5 pages1.3.6.6.1. Normal Distributionhav.stnPas encore d'évaluation
- Lo2001 - Testing The Number of Components in A Normal MixtureDocument12 pagesLo2001 - Testing The Number of Components in A Normal MixtureYingChun PatPas encore d'évaluation
- Gae Rtner 2000Document15 pagesGae Rtner 2000Dirceu NascimentoPas encore d'évaluation
- Two Empirical Hydrocyclone Models RevisitedDocument17 pagesTwo Empirical Hydrocyclone Models Revisitedcelebraty100% (1)
- Modeling and Simulation For System Reliability Analysis: The RAMSAS MethodDocument7 pagesModeling and Simulation For System Reliability Analysis: The RAMSAS MethodDirceu NascimentoPas encore d'évaluation
- Simulation of ore dressing plantsDocument17 pagesSimulation of ore dressing plantsBhavdeep Kumar SinghPas encore d'évaluation
- Grinding Process Within Vertical Roller Mills Experiment and SimulationDocument5 pagesGrinding Process Within Vertical Roller Mills Experiment and SimulationDirceu Nascimento100% (1)
- The Computer Simulation of A Rougher - Scavenger Flotation Circuit For A Hematite OreDocument7 pagesThe Computer Simulation of A Rougher - Scavenger Flotation Circuit For A Hematite OreDirceu NascimentoPas encore d'évaluation
- A Compartment Model For The Mass Transfer Inside A Conventional F Lotation CellDocument15 pagesA Compartment Model For The Mass Transfer Inside A Conventional F Lotation CellDirceu NascimentoPas encore d'évaluation
- A Mathematical Model of Concentrate Solids Cont 2003 International Journal oDocument13 pagesA Mathematical Model of Concentrate Solids Cont 2003 International Journal oNataliePas encore d'évaluation
- The Modelling of Froth Zone Recovery in Batch and Continuously Operated Laboratory Flotation CellsDocument17 pagesThe Modelling of Froth Zone Recovery in Batch and Continuously Operated Laboratory Flotation CellsDirceu NascimentoPas encore d'évaluation
- State of The Art and Challenges in Mineral Processing ControlDocument11 pagesState of The Art and Challenges in Mineral Processing ControlDirceu NascimentoPas encore d'évaluation
- Process Control Systems Deliver Quantifiable Benefits in Mineral MillingDocument4 pagesProcess Control Systems Deliver Quantifiable Benefits in Mineral MillingalnemangiPas encore d'évaluation
- 2015 MW Supervisor FlotationDocument5 pages2015 MW Supervisor FlotationDirceu NascimentoPas encore d'évaluation
- Modelling and Simulation of Particle Breakage in Impact CrushersDocument8 pagesModelling and Simulation of Particle Breakage in Impact CrushersDirceu NascimentoPas encore d'évaluation
- CrushersDocument11 pagesCrushersRenzo Chavez100% (1)
- Crusher PBM TMDocument4 pagesCrusher PBM TMDirceu NascimentoPas encore d'évaluation
- USIM PAC 3.0: New Features For A Global Approach in Mineral Processing DesignDocument13 pagesUSIM PAC 3.0: New Features For A Global Approach in Mineral Processing DesignDirceu NascimentoPas encore d'évaluation
- 2006 Advances in ComminutionDocument21 pages2006 Advances in ComminutionDirceu NascimentoPas encore d'évaluation
- 2015 WCSB7 Placer Gold SamplingDocument8 pages2015 WCSB7 Placer Gold SamplingDirceu NascimentoPas encore d'évaluation
- 2004 CAB Mat Balance LeachingDocument6 pages2004 CAB Mat Balance LeachingDirceu NascimentoPas encore d'évaluation
- Richardson SchwarzDocument7 pagesRichardson SchwarzhulupatPas encore d'évaluation
- The Overall Measurement error-TOS and Uncertainty Budget in Metal AccountingDocument4 pagesThe Overall Measurement error-TOS and Uncertainty Budget in Metal AccountingDirceu NascimentoPas encore d'évaluation
- Process Control Systems Deliver Quantifiable Benefits in Mineral MillingDocument4 pagesProcess Control Systems Deliver Quantifiable Benefits in Mineral MillingalnemangiPas encore d'évaluation
- CrushersDocument11 pagesCrushersRenzo Chavez100% (1)
- 1993c Cim2 UP HydroDocument14 pages1993c Cim2 UP HydroDirceu NascimentoPas encore d'évaluation
- 2013 Wcsb6 SB Sampling SDDocument12 pages2013 Wcsb6 SB Sampling SDDirceu NascimentoPas encore d'évaluation
- A Mathematical Model of Recovery of Dense Medium Magnetics in The Wet Drum Magnetic SeparatorDocument17 pagesA Mathematical Model of Recovery of Dense Medium Magnetics in The Wet Drum Magnetic SeparatorDirceu NascimentoPas encore d'évaluation
- Richardson SchwarzDocument7 pagesRichardson SchwarzhulupatPas encore d'évaluation
- 1994c Apcom Slovenie Opti MoinhoDocument10 pages1994c Apcom Slovenie Opti MoinhoDirceu NascimentoPas encore d'évaluation
- Fuzzy Logic PDFDocument20 pagesFuzzy Logic PDFlibranhitesh7889Pas encore d'évaluation
- 2012 SB FireAssay SamplingDocument8 pages2012 SB FireAssay SamplingDirceu NascimentoPas encore d'évaluation
- Arun GangwarDocument7 pagesArun GangwarArun GangwarPas encore d'évaluation
- Li/FeS2 Battery Performance and ChemistryDocument22 pagesLi/FeS2 Battery Performance and ChemistrypaulPas encore d'évaluation
- Guidelines For The Operation of Digital FM Radio BroadcastDocument3 pagesGuidelines For The Operation of Digital FM Radio BroadcastmiyumiPas encore d'évaluation
- Webpage Evaluation GuideDocument1 pageWebpage Evaluation Guideankit boxerPas encore d'évaluation
- 9 Little Translation Mistakes With Big ConsequencesDocument2 pages9 Little Translation Mistakes With Big ConsequencesJuliany Chaves AlvearPas encore d'évaluation
- MHP 6 (Tugas 1 Diskusi Presentasi Laudon Dan Chafey)Document2 pagesMHP 6 (Tugas 1 Diskusi Presentasi Laudon Dan Chafey)Alexander William Wijaya OeiPas encore d'évaluation
- University of Tripoli Faculty of Engineering Petroleum EngineeringDocument10 pagesUniversity of Tripoli Faculty of Engineering Petroleum EngineeringesraPas encore d'évaluation
- Electronic Devices and Circuit TheoryDocument32 pagesElectronic Devices and Circuit TheoryIñaki Zuriel ConstantinoPas encore d'évaluation
- Laterricaedwards Teacher ResumeDocument3 pagesLaterricaedwards Teacher Resumeapi-627213926Pas encore d'évaluation
- Corning® LEAF® Optical Fiber: Product InformationDocument0 pageCorning® LEAF® Optical Fiber: Product Informationhcdung18Pas encore d'évaluation
- Checking Mixing Procedures for Compounds in Mixers 1 & 2Document1 pageChecking Mixing Procedures for Compounds in Mixers 1 & 2Dilnesa EjiguPas encore d'évaluation
- Electrical Safety Testing GuideDocument3 pagesElectrical Safety Testing GuideBalasoobramaniam CarooppunnenPas encore d'évaluation
- Additional MathematicsDocument10 pagesAdditional MathematicsAnonymous jqevOeP7Pas encore d'évaluation
- Bus Order SummaryDocument3 pagesBus Order SummaryKhairul IdhamPas encore d'évaluation
- Study of the Courier Industry at BookMyPacketDocument34 pagesStudy of the Courier Industry at BookMyPacketPiyush MittalPas encore d'évaluation
- Build Ubuntu for Ultra-96 FPGA DevelopmentDocument5 pagesBuild Ubuntu for Ultra-96 FPGA Developmentksajj0% (1)
- Rule 4 - Types of Construction (Book Format)Document2 pagesRule 4 - Types of Construction (Book Format)Thea AbelardoPas encore d'évaluation
- TLEN 5830-AWL Lecture-05Document31 pagesTLEN 5830-AWL Lecture-05Prasanna KoratlaPas encore d'évaluation
- 120.anti Theft Alerting System For Vehicle (2 Wheeler)Document3 pages120.anti Theft Alerting System For Vehicle (2 Wheeler)Basha BashaPas encore d'évaluation
- Blind / Switch Actuator REG-K/12x/24x/10 With Manual Mode, Light GreyDocument2 pagesBlind / Switch Actuator REG-K/12x/24x/10 With Manual Mode, Light GreyRazvan RazPas encore d'évaluation
- Introduction To Critical Reading SkillsDocument4 pagesIntroduction To Critical Reading SkillsParlindungan PardedePas encore d'évaluation
- Last Service ReportDocument4 pagesLast Service ReportSandeep NikhilPas encore d'évaluation
- Engine Coolant Temperature Sensor PM3516 3516B Power Module NBR00001-UPDocument2 pagesEngine Coolant Temperature Sensor PM3516 3516B Power Module NBR00001-UPFaresPas encore d'évaluation
- 16.5.3 Optional Lab: Troubleshooting Access Security With Windows 7Document12 pages16.5.3 Optional Lab: Troubleshooting Access Security With Windows 7Jayme ReedPas encore d'évaluation
- Energy Landscapes: Applications To Clusters, Biomolecules and Glasses (Cambridge Molecular Science)Document6 pagesEnergy Landscapes: Applications To Clusters, Biomolecules and Glasses (Cambridge Molecular Science)darlyPas encore d'évaluation
- Xtract V 3 0 8Document72 pagesXtract V 3 0 8Don Ing Marcos LeónPas encore d'évaluation
- Thomas Calculus 13th Edition Thomas Test BankDocument33 pagesThomas Calculus 13th Edition Thomas Test Banklovellgwynavo100% (24)
- Organization Behaviour Understanding Organizations: Dr. Sumi JhaDocument32 pagesOrganization Behaviour Understanding Organizations: Dr. Sumi JhakartikPas encore d'évaluation
- Comparison of fibre migration in different yarn bodiesDocument5 pagesComparison of fibre migration in different yarn bodiesJerin JosephPas encore d'évaluation
- International Journal of Project Management: Lavagnon A. Ika, Jonas Söderlund, Lauchlan T. Munro, Paolo LandoniDocument11 pagesInternational Journal of Project Management: Lavagnon A. Ika, Jonas Söderlund, Lauchlan T. Munro, Paolo LandoniWarda IshakPas encore d'évaluation