Vous aimerez peut-être aussi
- Answers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesD'EverandAnswers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesÉvaluation : 1.5 sur 5 étoiles1.5/5 (2)
- Simulasi CPU SchedulingDocument7 pagesSimulasi CPU SchedulingRa DoPas encore d'évaluation
- (Main) : Computer Based Test (CBT)Document12 pages(Main) : Computer Based Test (CBT)Resonance Eduventures100% (1)
- Problems Using Bankers Algortihm: Operating SystemDocument8 pagesProblems Using Bankers Algortihm: Operating SystemShreyaPas encore d'évaluation
- Problems Using Bankers Algortihm: Operating SystemDocument8 pagesProblems Using Bankers Algortihm: Operating SystemShreyaPas encore d'évaluation
- Problems Using Bankers Algortihm: Operating SystemDocument8 pagesProblems Using Bankers Algortihm: Operating SystemShreyaPas encore d'évaluation
- OS - Tutorial 6Document2 pagesOS - Tutorial 6黄佩珺Pas encore d'évaluation
- 07-12-16 - SR - IIT-IZ-CO-SPARK - RPTA-13 - 2015 - P1 - Key & Sol'sDocument13 pages07-12-16 - SR - IIT-IZ-CO-SPARK - RPTA-13 - 2015 - P1 - Key & Sol'sfocusonyourgoaldreamiitbombayPas encore d'évaluation
- 04-06-16 JR - Iit-Iz-Co-Spark Jee-Main Wtm-6 Key & Sols's F NDocument9 pages04-06-16 JR - Iit-Iz-Co-Spark Jee-Main Wtm-6 Key & Sols's F NrahulPas encore d'évaluation
- Chapter 5 - Arithmetic ProgressionsDocument16 pagesChapter 5 - Arithmetic Progressionssari.1225Pas encore d'évaluation
- Discrete-Time Markov Chains: He ShuangchiDocument61 pagesDiscrete-Time Markov Chains: He ShuangchiZhengYang ChinPas encore d'évaluation
- Industrial Quality Assurance: TopicDocument19 pagesIndustrial Quality Assurance: TopicSebastian OrdoñezPas encore d'évaluation
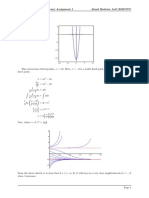
- Assignment 1 MAT323 (22301787)Document5 pagesAssignment 1 MAT323 (22301787)Ahnaf ShahriarPas encore d'évaluation
- DFC10103 Dis2019 Pbe03Document9 pagesDFC10103 Dis2019 Pbe03Haziqhv GamingPas encore d'évaluation
- ACTIVIDAD 1 GUIA 1-Morelia Diaz Hernandez 15Document1 pageACTIVIDAD 1 GUIA 1-Morelia Diaz Hernandez 15Morelia DiazPas encore d'évaluation
- Gate Deadlock With AnswersDocument6 pagesGate Deadlock With AnswersPriya PatelPas encore d'évaluation
- Marcos 01Document3 pagesMarcos 01markoagustinPas encore d'évaluation
- 04 CS316 Algorithms Recursive AlgorithmsDocument33 pages04 CS316 Algorithms Recursive AlgorithmsAbdelrhman SowilamPas encore d'évaluation
- ET4069 Fundamentals of Data Communication Networks Lecture 06Document13 pagesET4069 Fundamentals of Data Communication Networks Lecture 06Loc DoPas encore d'évaluation
- (4666) - 55 M.C.A. (Commerce) 506-Operation Research (Semester-V) (2008 Pattern)Document4 pages(4666) - 55 M.C.A. (Commerce) 506-Operation Research (Semester-V) (2008 Pattern)KuNdAn DeOrEPas encore d'évaluation
- 1660477463929Document62 pages1660477463929alih3sPas encore d'évaluation
- Os Past Papers' Solutions 2019Document3 pagesOs Past Papers' Solutions 2019zainab tehreemPas encore d'évaluation
- Ajay Kumar Garg Engineering College, Ghaziabad: Department of CSEDocument2 pagesAjay Kumar Garg Engineering College, Ghaziabad: Department of CSEGaurav Singh RawatPas encore d'évaluation
- Math Paper 2 MR 6points 1Document141 pagesMath Paper 2 MR 6points 1j4b2ds4mbxPas encore d'évaluation
- (Main) : Computer Based Test (CBT)Document9 pages(Main) : Computer Based Test (CBT)Resonance EduventuresPas encore d'évaluation
- Mumba Individual AlgosDocument5 pagesMumba Individual AlgosMusariri TalentPas encore d'évaluation
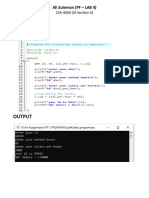
- PF Lab 4Document14 pagesPF Lab 4k224060 Ali SulemanPas encore d'évaluation
- Deadlock in OSDocument43 pagesDeadlock in OSRamin Khalifa WaliPas encore d'évaluation
- Cs 63Document7 pagesCs 63Bhargav HathiPas encore d'évaluation
- Joko As 2Document12 pagesJoko As 2HepyShollihudinPas encore d'évaluation
- Forum Session 13 R5Document4 pagesForum Session 13 R5Nurawanti tianiPas encore d'évaluation
- Stat I PDFDocument34 pagesStat I PDFVikrant AggarwalPas encore d'évaluation
- 06-04-17 - SR - IPLCO - Jee Adv - Ph-III - GTA-1 - New Model-1 (P1) - Key & Sol'sDocument14 pages06-04-17 - SR - IPLCO - Jee Adv - Ph-III - GTA-1 - New Model-1 (P1) - Key & Sol'sUppu EshwarPas encore d'évaluation
- Compre - Answerkey CS F372Document9 pagesCompre - Answerkey CS F372nasa stickPas encore d'évaluation
- Solution DPP Statistics Mathongo Bitsat 2023 Crash CourseDocument18 pagesSolution DPP Statistics Mathongo Bitsat 2023 Crash CourseAPARNA DIXITPas encore d'évaluation
- MathDocument2 pagesMathArdenielPas encore d'évaluation
- Dynamic Programming Solution To The Matrix-Chain Multiplication ProblemDocument4 pagesDynamic Programming Solution To The Matrix-Chain Multiplication ProblemHARSHRAJSINH SOLANKIPas encore d'évaluation
- Sequencing & Sorting: Budi Hartono, ST, MPMDocument49 pagesSequencing & Sorting: Budi Hartono, ST, MPMcokbinPas encore d'évaluation
- Measure The Sky 2nd Edition Chromey Solutions ManualDocument6 pagesMeasure The Sky 2nd Edition Chromey Solutions Manualschahheelpost4ogl100% (25)
- Measure The Sky 2Nd Edition Chromey Solutions Manual Full Chapter PDFDocument24 pagesMeasure The Sky 2Nd Edition Chromey Solutions Manual Full Chapter PDFJacobFloresxbpcn100% (10)
- Test ( (I + 8) % 10) Test ( (I + 2) % 10) : Part Correct: 3 Marks Entire: 8 MarksDocument3 pagesTest ( (I + 8) % 10) Test ( (I + 2) % 10) : Part Correct: 3 Marks Entire: 8 Markssai nikhilPas encore d'évaluation
- Assignment On Deadlock: Set: 01 Class Test Number: 02Document6 pagesAssignment On Deadlock: Set: 01 Class Test Number: 02Md Saidur Rahman Kohinoor70% (10)
- Jbptunikompp GDL Hermanssoe 25652 8 Kuliah1Document24 pagesJbptunikompp GDL Hermanssoe 25652 8 Kuliah1Daemon7Pas encore d'évaluation
- R R X R YtDocument9 pagesR R X R YtAthiyo MartinPas encore d'évaluation
- Logarithms DPPDocument2 pagesLogarithms DPPRajikPas encore d'évaluation
- 1473079949Document9 pages1473079949Athiyo MartinPas encore d'évaluation
- Hackerrank TestDocument3 pagesHackerrank Testswapnil0% (7)
- Conic Section - SolutionsDocument12 pagesConic Section - SolutionsFrank MartinezPas encore d'évaluation
- April 8 2Document42 pagesApril 8 2xejis32200Pas encore d'évaluation
- CCP403Document28 pagesCCP403api-3849444Pas encore d'évaluation
- Section ADocument2 pagesSection AUnderground PoetryPas encore d'évaluation
- (Main) : Computer Based Test (CBT)Document6 pages(Main) : Computer Based Test (CBT)Resonance EduventuresPas encore d'évaluation
- Os Past Papers' Solutions 2017Document4 pagesOs Past Papers' Solutions 2017zainab tehreemPas encore d'évaluation
- (Clipping Eksplisit 2D) : Soal IDocument5 pages(Clipping Eksplisit 2D) : Soal Ipranatha31071990Pas encore d'évaluation
- CLS - ENG 23 24 XI - Mat - Target 4 - Level 1 - Chapter 10Document57 pagesCLS - ENG 23 24 XI - Mat - Target 4 - Level 1 - Chapter 10Akshay KumarPas encore d'évaluation
- Enc 4215 Lec 6Document36 pagesEnc 4215 Lec 6elsayedyasser29Pas encore d'évaluation
- Network DiagramDocument23 pagesNetwork DiagramFazril ColoniPas encore d'évaluation
- Help Gaphic FuncionesDocument15 pagesHelp Gaphic Funcionesjhonatan fasanando tenazoaPas encore d'évaluation
- Marking Guideline: Mathematics N4Document9 pagesMarking Guideline: Mathematics N4nathanielPas encore d'évaluation
- Residual Number SystemDocument32 pagesResidual Number SystemDlishaPas encore d'évaluation
- Cloud Risk Management Mod 5Document26 pagesCloud Risk Management Mod 5Asmita BhagdikarPas encore d'évaluation
- IT Governance Mod 5Document40 pagesIT Governance Mod 5Asmita Bhagdikar100% (1)
- Amity University Dubai Operating System Concepts - CSIT123 BSC ItDocument1 pageAmity University Dubai Operating System Concepts - CSIT123 BSC ItAsmita BhagdikarPas encore d'évaluation
- IAS DoubtsDocument4 pagesIAS DoubtsAsmita BhagdikarPas encore d'évaluation
- Dice Profile Timothy HerrityDocument5 pagesDice Profile Timothy HerrityDave JonesPas encore d'évaluation
- CCS336 CSM PART A AND B Question and AnswersDocument83 pagesCCS336 CSM PART A AND B Question and AnswersNISHANTH M100% (1)
- Kevin Lun ResumeDocument1 pageKevin Lun Resumeapi-270258424Pas encore d'évaluation
- Tugas 3 CadDocument45 pagesTugas 3 CadPutro Adi nugrohoPas encore d'évaluation
- Low Cost Arduino BasedDocument6 pagesLow Cost Arduino Basedraeljohn273Pas encore d'évaluation
- Python RequestsDocument18 pagesPython RequestsKlever StylePas encore d'évaluation
- Iot Lecture PDFDocument423 pagesIot Lecture PDFshubhamPas encore d'évaluation
- Cubase LE AI Elements 750 Activated 72 PDFDocument3 pagesCubase LE AI Elements 750 Activated 72 PDFLoriPas encore d'évaluation
- Embedded SystemDocument75 pagesEmbedded SystemDnyaneshwar KarhalePas encore d'évaluation
- Tibbo2 Tps Catalogue EngDocument4 pagesTibbo2 Tps Catalogue EngseacerPas encore d'évaluation
- FDS Config Management PDocument38 pagesFDS Config Management Plucas christianPas encore d'évaluation
- Jeremy Harris Lipschultz - Social Media Communication - Concepts, Practices, Data, Law and EthicsDocument301 pagesJeremy Harris Lipschultz - Social Media Communication - Concepts, Practices, Data, Law and EthicsEko PutroPas encore d'évaluation
- Web Application Development: Bootstrap FrameworkDocument20 pagesWeb Application Development: Bootstrap FrameworkRaya AhmadaPas encore d'évaluation
- Ge2112 - Fundamentals of Computing and Programming: Unit Iv CDocument22 pagesGe2112 - Fundamentals of Computing and Programming: Unit Iv CAnitha VeeramanePas encore d'évaluation
- Instruction Manual: Electro-Pneumatic Valve PositionersDocument31 pagesInstruction Manual: Electro-Pneumatic Valve PositionersArdvarkPas encore d'évaluation
- Vanessa Morgan Da Silva - CV - ENDocument2 pagesVanessa Morgan Da Silva - CV - ENDiogo DomicianoPas encore d'évaluation
- Xtream IPTV Activation Code 2025Document18 pagesXtream IPTV Activation Code 2025sadoun dz79% (14)
- Manual Usuario Se-2003&se-2012Document41 pagesManual Usuario Se-2003&se-2012jimena lopez cardenasPas encore d'évaluation
- Basic Calculus MODULE-QTR-1-W5 To W6Document2 pagesBasic Calculus MODULE-QTR-1-W5 To W6James CaponponPas encore d'évaluation
- Cae PDFDocument56 pagesCae PDFChetan HcPas encore d'évaluation
- Bahasa Inggris Sma Ipa UnDocument9 pagesBahasa Inggris Sma Ipa UnMartinus AdjiePas encore d'évaluation
- Melides - Network-Ip - ListDocument34 pagesMelides - Network-Ip - ListJpPas encore d'évaluation
- GPS102-B User Manual 20141231 PDFDocument19 pagesGPS102-B User Manual 20141231 PDFСергей НеважноPas encore d'évaluation
- Quartiles For Grouped DataDocument19 pagesQuartiles For Grouped DataBeverly Joy Chicano AlonzoPas encore d'évaluation
- 6145 - JSPM'S Jaywantrao Sawant College of Engineering, PuneDocument13 pages6145 - JSPM'S Jaywantrao Sawant College of Engineering, PuneRushikesh KalePas encore d'évaluation
- AC#9-Setting Report - Intel - 20.10.20 - R0Document25 pagesAC#9-Setting Report - Intel - 20.10.20 - R0VũDuyTânPas encore d'évaluation
- Algo TMO18315-V4.1-SG-Ed8Document640 pagesAlgo TMO18315-V4.1-SG-Ed8SABER1980Pas encore d'évaluation
- AGIL Fence Perimeter Intrusion Detection System English SPDocument6 pagesAGIL Fence Perimeter Intrusion Detection System English SPTech GreenPas encore d'évaluation
- Blockchain Hack TX ScriptDocument5 pagesBlockchain Hack TX ScriptAkobe Urbain NdePas encore d'évaluation
- Sony Mhc-V50, V50d Ver. 1.0Document70 pagesSony Mhc-V50, V50d Ver. 1.0ЕвгенийPas encore d'évaluation