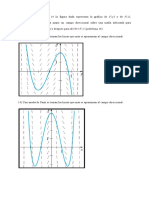
Vous aimerez peut-être aussi
- Problemas 13 - 18 Isoclinas y CeroclinasDocument9 pagesProblemas 13 - 18 Isoclinas y CeroclinaspaolaPas encore d'évaluation
- Prueba 3 Calculo 1 UCDocument5 pagesPrueba 3 Calculo 1 UCCande RetamalPas encore d'évaluation
- Abaco de RegnierDocument14 pagesAbaco de RegnierSAYA BOLAÑOS0% (1)
- Practica 4 SySDocument23 pagesPractica 4 SySCarlos Frausto100% (1)
- Metodo de Jacobi - Gauss SeidelDocument9 pagesMetodo de Jacobi - Gauss SeidelMaribel RomeroPas encore d'évaluation
- La ecuación general de segundo grado en dos y tres variablesD'EverandLa ecuación general de segundo grado en dos y tres variablesPas encore d'évaluation
- Taller 4 - Metodos NumericosDocument4 pagesTaller 4 - Metodos NumericosAlberto Lagos100% (1)
- Ejercicios Algoritmos 2014Document42 pagesEjercicios Algoritmos 2014maria rusoPas encore d'évaluation
- RECUPERATORIO 2do Parcial 28 Dic RESPUESTASDocument3 pagesRECUPERATORIO 2do Parcial 28 Dic RESPUESTASsebaschmeilPas encore d'évaluation
- Estructuras Diferenciales y Análisis Multivariable en Funciones Compuestas"Document13 pagesEstructuras Diferenciales y Análisis Multivariable en Funciones Compuestas"Abraham Hernandez RoaPas encore d'évaluation
- PF Mayor 2018 Sol PubDocument6 pagesPF Mayor 2018 Sol Pubggjtj gjfgjfgjgfPas encore d'évaluation
- Analisis 2019 Evau EspañaDocument10 pagesAnalisis 2019 Evau EspañaanaPas encore d'évaluation
- Ejercicios Resueltos Similares Práctica Control No. 1 de Cbm105 (Febrero-Abril 2021)Document8 pagesEjercicios Resueltos Similares Práctica Control No. 1 de Cbm105 (Febrero-Abril 2021)Julio Cesar De Los Santos MéndezPas encore d'évaluation
- ElipseDocument8 pagesElipseDaniela TarifaPas encore d'évaluation
- Funciones y Sus GráficasDocument7 pagesFunciones y Sus GráficasYelaika MendezPas encore d'évaluation
- Teoria de Funciones CuadraticasDocument30 pagesTeoria de Funciones CuadraticasSalvador CatalfamoPas encore d'évaluation
- Examen Matematicas 2 Jul 2020Document8 pagesExamen Matematicas 2 Jul 2020Juan IsidroPas encore d'évaluation
- Funciones Exponenciales e Hiperbã LicasDocument8 pagesFunciones Exponenciales e Hiperbã LicasJUAN LEONARDO QUIROGA YATEPas encore d'évaluation
- Práctica Nº2 de Métodos NumericosDocument43 pagesPráctica Nº2 de Métodos NumericosJonathan Tomás Josué Chipana AjnotaPas encore d'évaluation
- 10 - Tarea No.3Document13 pages10 - Tarea No.3pedroPas encore d'évaluation
- Kety Gutierrez Tarea1Document14 pagesKety Gutierrez Tarea1Kety GutierrezPas encore d'évaluation
- G1126 - Cristian Cubillos - Tarea 2Document13 pagesG1126 - Cristian Cubillos - Tarea 2Cristian CubillosPas encore d'évaluation
- Funciones y AplicacionesDocument7 pagesFunciones y AplicacionesAntonio Chumpitaz JulcaPas encore d'évaluation
- CAP. 16 Introducción Al Análisis en Ingeniería QuímicaDocument14 pagesCAP. 16 Introducción Al Análisis en Ingeniería QuímicaAbraham Gutierrez DguezPas encore d'évaluation
- MM 211 Vectores y Matrices Unidad II Sistemas de Ecuaciones, Desigualdades Lineales y Sus AplicacionesDocument55 pagesMM 211 Vectores y Matrices Unidad II Sistemas de Ecuaciones, Desigualdades Lineales y Sus AplicacionesArielPas encore d'évaluation
- 817 - Neisy BalantaDocument14 pages817 - Neisy BalantaAdriana patricia PalaciosPas encore d'évaluation
- Guia N4Document3 pagesGuia N4Aguilerita CatalinaPas encore d'évaluation
- Mat Guia 2°medio Func Cuadr2 AgostoDocument8 pagesMat Guia 2°medio Func Cuadr2 Agostoariel vegaPas encore d'évaluation
- Funciones Exponenciales y LogaritmicasDocument43 pagesFunciones Exponenciales y LogaritmicasPetan TrabajoPas encore d'évaluation
- Sistema HomogeneoDocument4 pagesSistema HomogeneoDaniel Peña SaenzPas encore d'évaluation
- Problema 10 TG 2021 CARMENGÓMEZDocument3 pagesProblema 10 TG 2021 CARMENGÓMEZCarmen Gómez AlarcónPas encore d'évaluation
- Cuadraicas y Funcion RaizDocument11 pagesCuadraicas y Funcion Raizbraulio93Pas encore d'évaluation
- Prueba Parcial 1, Métodos Numéricos 2015Document5 pagesPrueba Parcial 1, Métodos Numéricos 2015Leonel Molina AlvaradoPas encore d'évaluation
- HiperbolaDocument9 pagesHiperbolaDaniela Tarifa100% (1)
- Conicas y MatricesDocument13 pagesConicas y MatricesArnold Eduardo Chuquillanqui GuimarayPas encore d'évaluation
- 5 Ecuaciones Dif 2do Orden Coef IndetDocument27 pages5 Ecuaciones Dif 2do Orden Coef Indetemanuel leivaPas encore d'évaluation
- Olimpiada Colombiana de Matematica UniversitariaDocument5 pagesOlimpiada Colombiana de Matematica Universitariajfmarques100% (1)
- Guia Teorica-Practica 13Document34 pagesGuia Teorica-Practica 13Jose Eduardo Cuyutupa HuarcayaPas encore d'évaluation
- Taller No12-1Document5 pagesTaller No12-1alejandroPas encore d'évaluation
- Preguntas Dinamizadoras 1Document7 pagesPreguntas Dinamizadoras 1Euller Francisco Alvarado VargasPas encore d'évaluation
- Calculo Infinitesimal Trabajo Personal Trinidad Salas JosephDocument12 pagesCalculo Infinitesimal Trabajo Personal Trinidad Salas JosephYamirPas encore d'évaluation
- Mamt1 U1 A2 GellDocument5 pagesMamt1 U1 A2 GellGerardo LuvianoPas encore d'évaluation
- Libro Ejercicios TDC Camilo TapiaDocument111 pagesLibro Ejercicios TDC Camilo TapiaCarla Andrea ZúñigaPas encore d'évaluation
- Funcion CuadraticaDocument11 pagesFuncion CuadraticaazulcosmosPas encore d'évaluation
- Compendio CB103 2006-01 PDFDocument7 pagesCompendio CB103 2006-01 PDFJohan castro estradaPas encore d'évaluation
- Sistemas EcDocument13 pagesSistemas EcSONIAPas encore d'évaluation
- La Recta, La Parábola y La HiperbolaDocument9 pagesLa Recta, La Parábola y La HiperbolaMarly Salinas AriasPas encore d'évaluation
- Resumen y Ejercicios Resueltos ParábolasDocument7 pagesResumen y Ejercicios Resueltos ParábolasSEBASTIAN HERNANDEZ BABATIVA100% (1)
- Ecuaciones y Funciones - Unidad - 3 y 6Document6 pagesEcuaciones y Funciones - Unidad - 3 y 6Marini Morales DanaPas encore d'évaluation
- Mat II Septiembre 2010Document6 pagesMat II Septiembre 2010Alejandro Mayuri MauricioPas encore d'évaluation
- Actividad # 6 Temas 7 Función Cuadrática Marzo 2022Document16 pagesActividad # 6 Temas 7 Función Cuadrática Marzo 2022lesliePas encore d'évaluation
- Función CuadráticaDocument6 pagesFunción CuadráticaAdrián HernándezPas encore d'évaluation
- Modulo Distribuciones DiscretasDocument16 pagesModulo Distribuciones DiscretasOCLOCK BQPas encore d'évaluation
- Unidad 1 Tarea 2Document10 pagesUnidad 1 Tarea 2Nicolas EspinosaPas encore d'évaluation
- Aplicacion de Diagonalizacion de MatricesDocument10 pagesAplicacion de Diagonalizacion de MatricesRaúl Romero TámaraPas encore d'évaluation
- Funcion LinealDocument15 pagesFuncion LinealHenrry Cifuentes33% (3)
- DeterminantesDocument2 pagesDeterminantesDaniel AlejandroPas encore d'évaluation
- 3 Eso 7 Ecuaciones 1 Grado 2 IncogDocument2 pages3 Eso 7 Ecuaciones 1 Grado 2 IncogAldo RamirezPas encore d'évaluation
- Funcion Exponencialy LogaritmicaDocument20 pagesFuncion Exponencialy Logaritmicachevave322Pas encore d'évaluation
- Ruido FotodetectoresDocument9 pagesRuido FotodetectoresJosé Alberto GarcíaPas encore d'évaluation
- Transistor Bipolar Transistor Bipolar: Introducción A La ElectrónicaDocument68 pagesTransistor Bipolar Transistor Bipolar: Introducción A La Electrónicagatomares1Pas encore d'évaluation
- Reloj DigitalDocument6 pagesReloj DigitalJosé Alberto GarcíaPas encore d'évaluation
- CholeskyDocument15 pagesCholeskyJosé Alberto GarcíaPas encore d'évaluation
- Sony Vaio SVE-14A27CLS PDFDocument1 pageSony Vaio SVE-14A27CLS PDFOscarPas encore d'évaluation
- Parcial 2 v2 FixedDocument12 pagesParcial 2 v2 FixedcachorrotrenquePas encore d'évaluation
- Informe 1Document8 pagesInforme 1Jorge Luis QuinterosPas encore d'évaluation
- Tarea. DMLDocument2 pagesTarea. DMLMichael Ortiz100% (1)
- Instructivo Punto de CuentaDocument2 pagesInstructivo Punto de CuentaWilmerGironPas encore d'évaluation
- Sgdlcem - Proyecto en Ing Sistemas Cem - ChilcaDocument67 pagesSgdlcem - Proyecto en Ing Sistemas Cem - ChilcaJoannes Dixon Cardenas MoriPas encore d'évaluation
- 337 TPDocument5 pages337 TPAnabell LaresPas encore d'évaluation
- TRAB Rec02 Indicaciones Esp - v0r2Document3 pagesTRAB Rec02 Indicaciones Esp - v0r2Erick Fabrizio Lasso MoralesPas encore d'évaluation
- Manual Dichessxt Es Release 54Document8 pagesManual Dichessxt Es Release 54Joaquin A. Vásquez TantaleánPas encore d'évaluation
- 2da P.C de BASE DE DATOSDocument25 pages2da P.C de BASE DE DATOSVictor Elvis Castro GarayPas encore d'évaluation
- Poa Gestion Documental 2021Document2 pagesPoa Gestion Documental 2021AZ Gestión DocumentalPas encore d'évaluation
- Investigación Conexiones SGBDDocument11 pagesInvestigación Conexiones SGBDAndres CameloPas encore d'évaluation
- Hyudai HF 2210Document28 pagesHyudai HF 2210Edgar Pimentel0% (1)
- Modelo de U-Learning Basado en Plataformas de TV Everywhere: Gustavo Alberto Moreno LópezDocument295 pagesModelo de U-Learning Basado en Plataformas de TV Everywhere: Gustavo Alberto Moreno Lópezjorge escalantePas encore d'évaluation
- Semana 4 - Direccionamiento TCP-IP - AdicionalDocument25 pagesSemana 4 - Direccionamiento TCP-IP - AdicionalLuis Rojas BarbaránPas encore d'évaluation
- Dell Latitude E5400Document42 pagesDell Latitude E5400geniusrunnerPas encore d'évaluation
- Electrónica Digital 3 - Proyecto FIME UANLDocument4 pagesElectrónica Digital 3 - Proyecto FIME UANLMartín BarreraPas encore d'évaluation
- Lista de ChequeoDocument2 pagesLista de ChequeoAldair Ortiz GuerreroPas encore d'évaluation
- Guia Paso A Paso Conectar Igualdad PDFDocument112 pagesGuia Paso A Paso Conectar Igualdad PDFguillePas encore d'évaluation
- Arquitectura EmpresarialDocument16 pagesArquitectura EmpresarialHUGO CESAR CASANOVA DEL CASTILLOPas encore d'évaluation
- FP PrlabDocument46 pagesFP PrlabJuanjo SerranoPas encore d'évaluation
- Manual Tecnico Hardware SettiDocument16 pagesManual Tecnico Hardware SettidjalexraulPas encore d'évaluation
- Proyecto Final ControlDocument3 pagesProyecto Final ControlDiana Carolina HPas encore d'évaluation
- Ejemplos de RecursividadDocument3 pagesEjemplos de RecursividadWilliamAbelPeraltaTorresPas encore d'évaluation
- Alumno de UabcDocument90 pagesAlumno de UabcJavier GomezPas encore d'évaluation
- Lab 14 - Polimorfismo Con InterfacesDocument7 pagesLab 14 - Polimorfismo Con InterfacesKlebert LaymePas encore d'évaluation
- Sistemas Hidráulicos y Neumáticos - EXAMENES PDFDocument47 pagesSistemas Hidráulicos y Neumáticos - EXAMENES PDFoscarPas encore d'évaluation
- UG Vidar Es 11 EspñolDocument16 pagesUG Vidar Es 11 Espñolcharliy100% (1)