Vous aimerez peut-être aussi
- USW1 RSCH 8210 Week05 ScenariosDocument2 pagesUSW1 RSCH 8210 Week05 ScenariosSunil Kumar0% (1)
- Descriptive StatisticsDocument29 pagesDescriptive Statisticsnamratachouhan84Pas encore d'évaluation
- FMEADocument91 pagesFMEAscorpionarnoldPas encore d'évaluation
- Mann Whitney Wilcoxon Tests (Simulation)Document16 pagesMann Whitney Wilcoxon Tests (Simulation)scjofyWFawlroa2r06YFVabfbajPas encore d'évaluation
- HR Project On Performance ManagementDocument42 pagesHR Project On Performance Managementyatinastha91% (23)
- Plan Training Session Written ExamDocument4 pagesPlan Training Session Written ExamIsmael Jade Sueno100% (1)
- AnnovaDocument19 pagesAnnovaLabiz Saroni Zida0% (1)
- Nonparametric TestDocument29 pagesNonparametric TestDela Cruz GenesisPas encore d'évaluation
- Chi Square TestDocument5 pagesChi Square TestToman Chi To LamPas encore d'évaluation
- Normal Distribution Nov 2021 - FinalDocument36 pagesNormal Distribution Nov 2021 - FinalmussaPas encore d'évaluation
- Soma.35.Data Analysis - FinalDocument7 pagesSoma.35.Data Analysis - FinalAmna iqbal100% (1)
- Mean Median and Mode For Grouped Data PDFDocument4 pagesMean Median and Mode For Grouped Data PDFArnold ArceoPas encore d'évaluation
- Sampling Distribution and Point Estimation of Parameters: MATH30-6 Probability and StatisticsDocument24 pagesSampling Distribution and Point Estimation of Parameters: MATH30-6 Probability and StatisticsmisakaPas encore d'évaluation
- What Is Hypothesis TestingDocument46 pagesWhat Is Hypothesis Testingmuliawan firdaus100% (1)
- A8 Maersk CaseDocument5 pagesA8 Maersk CaseSuduPas encore d'évaluation
- P Value DefinitionDocument1 pageP Value Definitionitsme5616100% (1)
- Central Limit TheormDocument101 pagesCentral Limit TheormGhada SheashaPas encore d'évaluation
- Benefits of Public TransportationDocument1 pageBenefits of Public TransportationHaritharan ManiamPas encore d'évaluation
- Measures of DispersionDocument25 pagesMeasures of Dispersionroland100% (1)
- Inquiries Midterm ExamDocument2 pagesInquiries Midterm ExamMarkmarilyn100% (1)
- Testing For Normality Using SPSS PDFDocument12 pagesTesting For Normality Using SPSS PDFΧρήστος Ντάνης100% (1)
- Roles and Responsibilities - PHD SupervisorDocument3 pagesRoles and Responsibilities - PHD SupervisormikekbkoPas encore d'évaluation
- Correlation and Regression AnalysisDocument19 pagesCorrelation and Regression AnalysisJefferson Ayubo BroncanoPas encore d'évaluation
- Basicresearchterminology 201129064504Document24 pagesBasicresearchterminology 201129064504amara de guzman100% (1)
- Chapter 11 Waiting LineDocument17 pagesChapter 11 Waiting LineJega KanagasabaiPas encore d'évaluation
- Levenes TestDocument7 pagesLevenes TestRex LimPas encore d'évaluation
- IKM - Sample Size Calculation in Epid Study PDFDocument7 pagesIKM - Sample Size Calculation in Epid Study PDFcindyPas encore d'évaluation
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignD'EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignPas encore d'évaluation
- Tabu Ran NormalDocument14 pagesTabu Ran NormalSylvia100% (1)
- Simplex Method AssignmentDocument11 pagesSimplex Method AssignmentNurul Rizal100% (1)
- Item AnalysisDocument13 pagesItem AnalysisParbati samantaPas encore d'évaluation
- Administering, Analyzing, and Improving TestsDocument3 pagesAdministering, Analyzing, and Improving TestsJessa Mae Cantillo100% (1)
- Non-Parametric TestDocument2 pagesNon-Parametric Testutcm77Pas encore d'évaluation
- CH 10 Skewness KurtosisDocument17 pagesCH 10 Skewness KurtosisiamakingPas encore d'évaluation
- Descriptive StatisticsDocument11 pagesDescriptive StatisticsTeresito AbsalonPas encore d'évaluation
- Spss ExercisesDocument13 pagesSpss ExercisesEbenezerPas encore d'évaluation
- Sampling Distribution: DefinitionDocument39 pagesSampling Distribution: Definitionمؤيد العتيبيPas encore d'évaluation
- 6 Pretest and Pilot StudyDocument31 pages6 Pretest and Pilot StudyChandan ShahPas encore d'évaluation
- Sample ErrorDocument19 pagesSample ErrorŘüđĥirSiddhamPas encore d'évaluation
- Hypothesis TestingDocument180 pagesHypothesis Testingrns116Pas encore d'évaluation
- Activity No. 2Document12 pagesActivity No. 2Keennan L. CuyosPas encore d'évaluation
- Norm - Referenced Tests & Criterion-Referenced TestsDocument13 pagesNorm - Referenced Tests & Criterion-Referenced TestsNeil Ang100% (2)
- The Values of Filipino Millennials and ZoomersDocument7 pagesThe Values of Filipino Millennials and ZoomersPsychology and Education: A Multidisciplinary JournalPas encore d'évaluation
- Test ConstructionDocument13 pagesTest ConstructionNiharikaBishtPas encore d'évaluation
- Lesson 12 T Test Dependent SamplesDocument26 pagesLesson 12 T Test Dependent SamplesNicole Daphnie LisPas encore d'évaluation
- Hypothesis TestsDocument3 pagesHypothesis TestsXenon FranciumPas encore d'évaluation
- Parametric Vs Non Parametric TestDocument4 pagesParametric Vs Non Parametric TestRitvik ChauhanPas encore d'évaluation
- Checklist For Diagnostic Accuracy-StudiesDocument3 pagesChecklist For Diagnostic Accuracy-StudiesConstanza PintoPas encore d'évaluation
- Nonparametric LectureDocument31 pagesNonparametric LecturejsembiringPas encore d'évaluation
- 8) Multilevel AnalysisDocument41 pages8) Multilevel AnalysisMulusewPas encore d'évaluation
- 2.1 Measures of Central TendencyDocument32 pages2.1 Measures of Central Tendencypooja_patnaik237Pas encore d'évaluation
- Likert ScaleDocument2 pagesLikert ScaleIvani KatalPas encore d'évaluation
- Statistical Soup - ANOVA, ANCOVA, MANOVA, & MANCOVA - Stats Make Me Cry ConsultingDocument3 pagesStatistical Soup - ANOVA, ANCOVA, MANOVA, & MANCOVA - Stats Make Me Cry ConsultingsapaPas encore d'évaluation
- Talisayon Chapter 4 DepEdDocument13 pagesTalisayon Chapter 4 DepEdShekaina Faith Cuizon LozadaPas encore d'évaluation
- List of Statistical PackagesDocument2 pagesList of Statistical Packagestavishi dhawanPas encore d'évaluation
- Paired Data, Correlation & RegressionDocument6 pagesPaired Data, Correlation & Regressionvelkus2013Pas encore d'évaluation
- The Nursing ProcessDocument17 pagesThe Nursing ProcessElla Lobenaria100% (1)
- What Is Item Analysis?Document4 pagesWhat Is Item Analysis?matang_lawinPas encore d'évaluation
- Introduction To Database Management and Statistical SoftwareDocument48 pagesIntroduction To Database Management and Statistical Softwareamin ahmedPas encore d'évaluation
- Task 3Document3 pagesTask 3Fleur De Liz Jagolino100% (1)
- Tests of Significance Notes PDFDocument12 pagesTests of Significance Notes PDFManish KPas encore d'évaluation
- Test ScoringDocument9 pagesTest ScoringArsal AliPas encore d'évaluation
- Solution: Step 2. Select The Distribution To UseDocument6 pagesSolution: Step 2. Select The Distribution To UseRobert S. DeligeroPas encore d'évaluation
- ch03 Ver3Document25 pagesch03 Ver3Mustansar Hussain NiaziPas encore d'évaluation
- Wilcoxon Signed-Ranks TestDocument16 pagesWilcoxon Signed-Ranks TestLayan MohammadPas encore d'évaluation
- Randomized Block Design and Latin SquareDocument2 pagesRandomized Block Design and Latin SquareDeepak Kumar SinghPas encore d'évaluation
- Research Hypothesis & TypesDocument11 pagesResearch Hypothesis & TypesMahendra Dhoni100% (1)
- Student's T Test: Ibrahim A. Alsarra, PH.DDocument20 pagesStudent's T Test: Ibrahim A. Alsarra, PH.DNana Fosu YeboahPas encore d'évaluation
- The T-Test: Home Analysis Inferential StatisticsDocument4 pagesThe T-Test: Home Analysis Inferential StatisticskakkrasPas encore d'évaluation
- Blooms TaxonomyDocument2 pagesBlooms Taxonomypchess_lilacksye802Pas encore d'évaluation
- D4123 Resilient ModulusDocument4 pagesD4123 Resilient ModulusNurul RizalPas encore d'évaluation
- Answr Reviewer's CommentsDocument5 pagesAnswr Reviewer's CommentsNurul RizalPas encore d'évaluation
- Blooms TaxonomyDocument2 pagesBlooms Taxonomypchess_lilacksye802Pas encore d'évaluation
- Blooms TaxonomyDocument2 pagesBlooms Taxonomypchess_lilacksye802Pas encore d'évaluation
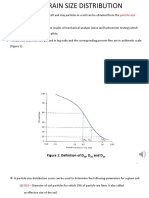
- 1.2 Grain Size Distribution CurveDocument11 pages1.2 Grain Size Distribution CurveNurul RizalPas encore d'évaluation
- Basic Knowledge of Polynomial Functions (Algebra 2, Polynomial Functions) - MathplanetDocument1 pageBasic Knowledge of Polynomial Functions (Algebra 2, Polynomial Functions) - MathplanetNurul RizalPas encore d'évaluation
- Hoffmann - TaxComp - TAXONOMY BLOOMDocument8 pagesHoffmann - TaxComp - TAXONOMY BLOOMNurul RizalPas encore d'évaluation
- Linking Words PDFDocument2 pagesLinking Words PDFmanojkhadka23Pas encore d'évaluation
- Homestay Murah Langkawi 2017Document2 pagesHomestay Murah Langkawi 2017Nurul RizalPas encore d'évaluation
- Jadual Harga Purata Bitumen 2005Document12 pagesJadual Harga Purata Bitumen 2005Nurul RizalPas encore d'évaluation
- BFC14003 1.3 Separable EquationDocument17 pagesBFC14003 1.3 Separable EquationNurul RizalPas encore d'évaluation
- NewItem 150 PlasticsWasteDocument47 pagesNewItem 150 PlasticsWasteYovitaAyuningtyasPas encore d'évaluation
- Determination Unsignalized Intersection at KM 20 Jalan Batu Pahat-KluangDocument6 pagesDetermination Unsignalized Intersection at KM 20 Jalan Batu Pahat-KluangNurul RizalPas encore d'évaluation
- Sustainable Community ReportDocument9 pagesSustainable Community ReportNurul RizalPas encore d'évaluation
- Unsignlized ProblemDocument3 pagesUnsignlized ProblemNurul RizalPas encore d'évaluation
- d36 Softening Point Test Ring and BallDocument5 pagesd36 Softening Point Test Ring and BallNurul RizalPas encore d'évaluation
- Geotextiles in Transportation ApplicationsDocument13 pagesGeotextiles in Transportation ApplicationstsuakPas encore d'évaluation
- Geotextiles in Transportation ApplicationsDocument13 pagesGeotextiles in Transportation ApplicationstsuakPas encore d'évaluation
- Creating Sustainable Community CampusDocument6 pagesCreating Sustainable Community CampusNurul RizalPas encore d'évaluation
- Asgnment 1 10 ImpactDocument9 pagesAsgnment 1 10 ImpactNurul RizalPas encore d'évaluation
- PHF CalculationDocument1 pagePHF CalculationNurul RizalPas encore d'évaluation
- Assignment 1 Mka1103 Advanced Pavement MaterialDocument5 pagesAssignment 1 Mka1103 Advanced Pavement MaterialNurul RizalPas encore d'évaluation
- Pavement Analysis and Design Mka 2063 Assignment 2Document3 pagesPavement Analysis and Design Mka 2063 Assignment 2Nurul RizalPas encore d'évaluation
- Asshto m320 BinderDocument1 pageAsshto m320 BinderNurul RizalPas encore d'évaluation
- Review of Impact Gis 1Document12 pagesReview of Impact Gis 1Nurul RizalPas encore d'évaluation
- Type of ModifierDocument4 pagesType of ModifierNurul RizalPas encore d'évaluation
- HomeworkDocument4 pagesHomeworkNurul RizalPas encore d'évaluation
- Chapter 06 PDFDocument18 pagesChapter 06 PDFMonicaFrensiaMegaFisheraPas encore d'évaluation
- Bgcse Literature CourseworkDocument5 pagesBgcse Literature Courseworkf5dhtyz1100% (2)
- My Lovely ResumeDocument3 pagesMy Lovely ResumeJanicz BalderamaPas encore d'évaluation
- Market Survey Report On Small CarDocument39 pagesMarket Survey Report On Small CarPrannoy Raj100% (1)
- 130 339 1 PBDocument12 pages130 339 1 PBSari YantiPas encore d'évaluation
- The Percentage Oil Content, P, and The Weight, W Milligrams, of Each of 10 RandomlyDocument17 pagesThe Percentage Oil Content, P, and The Weight, W Milligrams, of Each of 10 RandomlyHalal BoiPas encore d'évaluation
- Management in Practice: Assignment 2Document12 pagesManagement in Practice: Assignment 2yeah yeahPas encore d'évaluation
- Learning WalksDocument6 pagesLearning WalksheenamodiPas encore d'évaluation
- Zabur)Document42 pagesZabur)Mushimiyimana Paluku AlinePas encore d'évaluation
- Tugas Regresi & Kuisoner Aldi DKKDocument7 pagesTugas Regresi & Kuisoner Aldi DKKRegan Muammar NugrahaPas encore d'évaluation
- Simplified Guide To Fingerprint AnalysisDocument13 pagesSimplified Guide To Fingerprint AnalysisPRINCES ALLEN MATULACPas encore d'évaluation
- Data Analytics Key NotesDocument5 pagesData Analytics Key NotestimPas encore d'évaluation
- QsenDocument7 pagesQsendancehallstarraPas encore d'évaluation
- SSRN Id4354422Document19 pagesSSRN Id4354422Mr. DhimalPas encore d'évaluation
- Third Periodic Examination in Math Problem Solving: Main Campus - Level 12Document9 pagesThird Periodic Examination in Math Problem Solving: Main Campus - Level 12Shanna Basallo AlentonPas encore d'évaluation
- Data Analytics BI Data Sample PopulationDocument5 pagesData Analytics BI Data Sample PopulationA. T. M. Abdullah Al MamunPas encore d'évaluation
- Chapter 1 - 2Document36 pagesChapter 1 - 2Jeppry saniPas encore d'évaluation
- Case Study On Data MiningDocument7 pagesCase Study On Data MiningMichael Angelo ConuiPas encore d'évaluation
- Engineering, Construction and Architectural Management: Article InformationDocument16 pagesEngineering, Construction and Architectural Management: Article InformationGishan Nadeera GunadasaPas encore d'évaluation
- Positional Plagiocephaly: An Analysis of The Literature On The Effectiveness of Current GuidelinesDocument9 pagesPositional Plagiocephaly: An Analysis of The Literature On The Effectiveness of Current GuidelinesManjunath VaddambalPas encore d'évaluation
- Confidence Level and Sample SizeDocument19 pagesConfidence Level and Sample SizeJoice Camelle PinosPas encore d'évaluation
- SWAT Model Calibration EvaluationDocument16 pagesSWAT Model Calibration EvaluationAnonymous BVbpSEPas encore d'évaluation
- Study Skills Handbook - (B Academic Skills)Document16 pagesStudy Skills Handbook - (B Academic Skills)Fatimah Al-ShammiriPas encore d'évaluation