Vous aimerez peut-être aussi
- Robotics 12 00119 v2Document18 pagesRobotics 12 00119 v2Josep Rueda CollellPas encore d'évaluation
- 4 Active Teaching in Robot Programming by DemonstrationDocument6 pages4 Active Teaching in Robot Programming by DemonstrationoldenPas encore d'évaluation
- A Heuristic Predictive LOS Guidance Law Based On Trajectory Learning, Ant Colony Optimization and Tabu SearchDocument7 pagesA Heuristic Predictive LOS Guidance Law Based On Trajectory Learning, Ant Colony Optimization and Tabu Searchاحمد عليPas encore d'évaluation
- Reinforcement Learning in Robotics: A Survey: Jens Kober J. Andrew Bagnell Jan PetersDocument38 pagesReinforcement Learning in Robotics: A Survey: Jens Kober J. Andrew Bagnell Jan PetersLaxmikanth CherukupalliPas encore d'évaluation
- Composite Dynamic Movement Primitives Based On Neural Networks For Human-Robot Skill TransferDocument11 pagesComposite Dynamic Movement Primitives Based On Neural Networks For Human-Robot Skill TransferathenavladivostokPas encore d'évaluation
- Robust Feedback Motion Policy Design Using Reinforcement Learning On A 3D Digit Bipedal RobotDocument8 pagesRobust Feedback Motion Policy Design Using Reinforcement Learning On A 3D Digit Bipedal Robotnarvan.m31Pas encore d'évaluation
- A Teaching Demonstration Set of A 5DOF Robotic Arm Controlled by PLCInternational Journal of Information and Education TechnologyDocument5 pagesA Teaching Demonstration Set of A 5DOF Robotic Arm Controlled by PLCInternational Journal of Information and Education TechnologytheinPas encore d'évaluation
- Mobile Robot Path Planning in Dynamic Environments Through Globally Guided Reinforcement LearningDocument8 pagesMobile Robot Path Planning in Dynamic Environments Through Globally Guided Reinforcement LearningVarun AgarwalPas encore d'évaluation
- Learning To Walk Via Deep Reinforcement LearningDocument10 pagesLearning To Walk Via Deep Reinforcement LearningZiming MengPas encore d'évaluation
- Deep Reinforcement Learning For Robotic Manipulation With Asynchronous Off-Policy UpdatesDocument9 pagesDeep Reinforcement Learning For Robotic Manipulation With Asynchronous Off-Policy Updatescong nguyenPas encore d'évaluation
- Task-Level Imitation Learning Using Variance-Based Movement OptimizationDocument8 pagesTask-Level Imitation Learning Using Variance-Based Movement OptimizationumarsulemanPas encore d'évaluation
- (Ae 420) Module 7Document15 pages(Ae 420) Module 7RPas encore d'évaluation
- Model-Based Deep Hand Pose EstimationDocument7 pagesModel-Based Deep Hand Pose EstimationĐào Văn HưngPas encore d'évaluation
- RoboticsDocument3 pagesRoboticsRishabh ShahPas encore d'évaluation
- Robot Learning System Based On Adaptive Neural Control and Dynamic Movement PrimitivesDocument11 pagesRobot Learning System Based On Adaptive Neural Control and Dynamic Movement PrimitivesathenavladivostokPas encore d'évaluation
- Good 3Document15 pagesGood 3tanvir anwarPas encore d'évaluation
- Object Detection and Recognition For A Pick and Place Robot: Rahul Kumar Sanjesh KumarDocument7 pagesObject Detection and Recognition For A Pick and Place Robot: Rahul Kumar Sanjesh KumarLuật NguyễnPas encore d'évaluation
- Icra 2010Document6 pagesIcra 2010farhadPas encore d'évaluation
- Kormushev ROB2013Document28 pagesKormushev ROB2013dhanushdarshan7Pas encore d'évaluation
- p72 TsiakmakiDocument6 pagesp72 TsiakmakicafexarmaniPas encore d'évaluation
- Mobile Robots That Learn To Navigate: Honours Year Project ReportDocument85 pagesMobile Robots That Learn To Navigate: Honours Year Project ReportUmer Farooq ShahPas encore d'évaluation
- Visual Reinforcement Learning With Imagined Goals: Equal Contribution. Order Was Determined by Coin FlipDocument15 pagesVisual Reinforcement Learning With Imagined Goals: Equal Contribution. Order Was Determined by Coin FlipalyasocialwayPas encore d'évaluation
- Intelligent Trainer For Model-Based Deep Reinforcement LearningDocument13 pagesIntelligent Trainer For Model-Based Deep Reinforcement LearningTeam2 ResearchPas encore d'évaluation
- University of Dortmund, Computer Science Dept. LS VIII, D-44221 Dortmund, Germany Volker, Morik @ls8.informatik - Uni-Dortmund - deDocument8 pagesUniversity of Dortmund, Computer Science Dept. LS VIII, D-44221 Dortmund, Germany Volker, Morik @ls8.informatik - Uni-Dortmund - deadrian_veidtPas encore d'évaluation
- FPGA Architecture For Deep Learning and Its ApplicationDocument9 pagesFPGA Architecture For Deep Learning and Its ApplicationクォックアンPas encore d'évaluation
- Acclerating RL For Maze GameDocument22 pagesAcclerating RL For Maze GameChaoshun HuPas encore d'évaluation
- Software Compliments Structured Learning For Kinematics of MechanismsDocument4 pagesSoftware Compliments Structured Learning For Kinematics of MechanismsSathesh KumarPas encore d'évaluation
- Supervision Via Competition: Robot Adversaries For Learning TasksDocument8 pagesSupervision Via Competition: Robot Adversaries For Learning TasksrobotdazeroPas encore d'évaluation
- Control of A Quadrotor With Reinforcement Learning: Jemin Hwangbo, Inkyu Sa, Roland Siegwart and Marco HutterDocument8 pagesControl of A Quadrotor With Reinforcement Learning: Jemin Hwangbo, Inkyu Sa, Roland Siegwart and Marco HutterVikas MagarPas encore d'évaluation
- 2023 MPC Quadruped RLDocument13 pages2023 MPC Quadruped RLpouya mansouriPas encore d'évaluation
- R Be 550 Motion Planning ProjectDocument8 pagesR Be 550 Motion Planning ProjectAkash SridharanPas encore d'évaluation
- Reinforcement Learning in Robotics A SurveyDocument37 pagesReinforcement Learning in Robotics A Surveyaleong1Pas encore d'évaluation
- P12 Visual Foresight - Model-Based Deep Reinforcement Learning For Vision-Based Robotic ControlDocument14 pagesP12 Visual Foresight - Model-Based Deep Reinforcement Learning For Vision-Based Robotic ControlSau L.Pas encore d'évaluation
- AMP: Adversarial Motion Priors For Stylized Physics-Based Character ControlDocument20 pagesAMP: Adversarial Motion Priors For Stylized Physics-Based Character ControlZiming MengPas encore d'évaluation
- A Survey On Deep Learning and Deep Reinforcement Learning in Robotics With A Tutorial On Deep Reinforcement LearningDocument33 pagesA Survey On Deep Learning and Deep Reinforcement Learning in Robotics With A Tutorial On Deep Reinforcement LearninghadiPas encore d'évaluation
- ICRA2024 IRL Reward Shaping WuDocument8 pagesICRA2024 IRL Reward Shaping Wukkanishk2023Pas encore d'évaluation
- PDF - Js ViewerDocument5 pagesPDF - Js ViewerPranoy MukherjeePas encore d'évaluation
- IJISAE 20 Divya+kumawat 3 1834Document10 pagesIJISAE 20 Divya+kumawat 3 1834Siddesh PingalePas encore d'évaluation
- Unsupervised Learning of Depth and Ego-Motion From VideoDocument10 pagesUnsupervised Learning of Depth and Ego-Motion From VideoSagar URPas encore d'évaluation
- tmp3FCD TMPDocument14 pagestmp3FCD TMPFrontiersPas encore d'évaluation
- Seminar Abhi SVDDocument31 pagesSeminar Abhi SVDAbhishek R NairPas encore d'évaluation
- OpenAI Et Al. - 2019 - Learning Dexterous In-Hand ManipulationDocument27 pagesOpenAI Et Al. - 2019 - Learning Dexterous In-Hand ManipulationAdam LeePas encore d'évaluation
- Introducing Python Programming For Engineering Scholars: Zahid Hussain, Muhammad Siyab KhanDocument8 pagesIntroducing Python Programming For Engineering Scholars: Zahid Hussain, Muhammad Siyab KhanDavid C HouserPas encore d'évaluation
- Study of Amateur High Power Rocket Trajectories: Bachelor Final ThesisDocument32 pagesStudy of Amateur High Power Rocket Trajectories: Bachelor Final ThesisVictor QuezadaPas encore d'évaluation
- Ibarz Et Al 2021 How To Train Your Robot With Deep Reinforcement Learning Lessons We Have LearnedDocument24 pagesIbarz Et Al 2021 How To Train Your Robot With Deep Reinforcement Learning Lessons We Have LearnedhadiPas encore d'évaluation
- 2011-Leon Teaching A RobotbDocument8 pages2011-Leon Teaching A RobotbfarhadPas encore d'évaluation
- 3D Robotic Navigation Using A Vision-Based Deep Reinforcement - 1-S2.0-S1568494621005238-MainDocument17 pages3D Robotic Navigation Using A Vision-Based Deep Reinforcement - 1-S2.0-S1568494621005238-Mainroykaushik4uPas encore d'évaluation
- Application of Reinforcement Learning To A Two Dof Robot Arm ControlDocument2 pagesApplication of Reinforcement Learning To A Two Dof Robot Arm ControlmarcoPas encore d'évaluation
- Virtual-To-Real Deep Reinforcement Learning - Continuous Control of Mobile Robots For Mapless NavigationDocument6 pagesVirtual-To-Real Deep Reinforcement Learning - Continuous Control of Mobile Robots For Mapless Navigationbuihuyanh2018Pas encore d'évaluation
- Setting Up A Reinforcement Learning Task With A Real-World RobotDocument6 pagesSetting Up A Reinforcement Learning Task With A Real-World RobotAyman TaniraPas encore d'évaluation
- CS401Document8 pagesCS401苗子良Pas encore d'évaluation
- Human Body Orientation Estimation Using Convolutional Neural NetworkDocument5 pagesHuman Body Orientation Estimation Using Convolutional Neural Networkbukhtawar zamirPas encore d'évaluation
- Robotic Grasping and Manipulation of Objects: András Fekete University of New HampshireDocument5 pagesRobotic Grasping and Manipulation of Objects: András Fekete University of New HampshirerPas encore d'évaluation
- Imitation-Based Motion Planning and Control of A MDocument8 pagesImitation-Based Motion Planning and Control of A Mabdelhamid.ghoul93Pas encore d'évaluation
- Geometric Loss Functions For Camera Pose Regression With Deep LearningDocument10 pagesGeometric Loss Functions For Camera Pose Regression With Deep LearningvukpetarPas encore d'évaluation
- Belkhale 等 - 2021 - Model-Based Meta-Reinforcement Learning for FlightDocument8 pagesBelkhale 等 - 2021 - Model-Based Meta-Reinforcement Learning for FlightAo AoPas encore d'évaluation
- An Evaluation of 2D SLAM Techniques Availablein Robot Operating SystemDocument6 pagesAn Evaluation of 2D SLAM Techniques Availablein Robot Operating SystemDimas de la PeñaPas encore d'évaluation
- 5 Csiszar 20bcgswDocument6 pages5 Csiszar 20bcgswMEHMETPas encore d'évaluation
- An Ergodic Measure For Active Learning From EquilibriumDocument15 pagesAn Ergodic Measure For Active Learning From EquilibriumJoan QuraPas encore d'évaluation
- Georgia Jean Weckler 070217Document223 pagesGeorgia Jean Weckler 070217api-290747380Pas encore d'évaluation
- Hanumaan Bajrang Baan by JDocument104 pagesHanumaan Bajrang Baan by JAnonymous R8qkzgPas encore d'évaluation
- The Nature of Mathematics: "Nature's Great Books Is Written in Mathematics" Galileo GalileiDocument9 pagesThe Nature of Mathematics: "Nature's Great Books Is Written in Mathematics" Galileo GalileiLei-Angelika TungpalanPas encore d'évaluation
- Weird Tales v14 n03 1929Document148 pagesWeird Tales v14 n03 1929HenryOlivr50% (2)
- E Tech SLHT QTR 2 Week 1Document11 pagesE Tech SLHT QTR 2 Week 1Vie Boldios Roche100% (1)
- OPSS 415 Feb90Document7 pagesOPSS 415 Feb90Muhammad UmarPas encore d'évaluation
- Tesmec Catalogue TmeDocument208 pagesTesmec Catalogue TmeDidier solanoPas encore d'évaluation
- The Rise of Political Fact CheckingDocument17 pagesThe Rise of Political Fact CheckingGlennKesslerWPPas encore d'évaluation
- Rudolf Steiner - Twelve Senses in Man GA 206Document67 pagesRudolf Steiner - Twelve Senses in Man GA 206Raul PopescuPas encore d'évaluation
- Educ 3 Prelim Act.1 AlidonDocument2 pagesEduc 3 Prelim Act.1 AlidonJonash AlidonPas encore d'évaluation
- SRL CompressorsDocument20 pagesSRL Compressorssthe03Pas encore d'évaluation
- English HL P1 Nov 2019Document12 pagesEnglish HL P1 Nov 2019Khathutshelo KharivhePas encore d'évaluation
- Specification - Pump StationDocument59 pagesSpecification - Pump StationchialunPas encore d'évaluation
- 2 Lista Total de Soportados 14-12-2022Document758 pages2 Lista Total de Soportados 14-12-2022Emanuel EspindolaPas encore d'évaluation
- TrematodesDocument95 pagesTrematodesFarlogy100% (3)
- Health and Hatha Yoga by Swami Sivananda CompressDocument356 pagesHealth and Hatha Yoga by Swami Sivananda CompressLama Fera with Yachna JainPas encore d'évaluation
- Product Training OutlineDocument3 pagesProduct Training OutlineDindin KamaludinPas encore d'évaluation
- Diva Arbitrage Fund PresentationDocument65 pagesDiva Arbitrage Fund Presentationchuff6675Pas encore d'évaluation
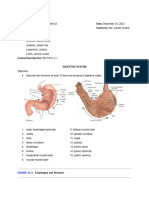
- Digestive System LabsheetDocument4 pagesDigestive System LabsheetKATHLEEN MAE HERMOPas encore d'évaluation
- LR 7833Document11 pagesLR 7833Trung ĐinhPas encore d'évaluation
- Duterte Vs SandiganbayanDocument17 pagesDuterte Vs SandiganbayanAnonymous KvztB3Pas encore d'évaluation
- Living Greyhawk - Greyhawk Grumbler #1 Coldeven 598 n1Document2 pagesLiving Greyhawk - Greyhawk Grumbler #1 Coldeven 598 n1Magus da RodaPas encore d'évaluation
- Dye-Sensitized Solar CellDocument7 pagesDye-Sensitized Solar CellFaez Ahammad MazumderPas encore d'évaluation
- NI 43-101 Technical Report - Lithium Mineral Resource Estimate Zeus Project, Clayton Valley, USADocument71 pagesNI 43-101 Technical Report - Lithium Mineral Resource Estimate Zeus Project, Clayton Valley, USAGuillaume De SouzaPas encore d'évaluation
- Lesson 17 Be MoneySmart Module 1 Student WorkbookDocument14 pagesLesson 17 Be MoneySmart Module 1 Student WorkbookAry “Icky”100% (1)
- Human Development IndexDocument17 pagesHuman Development IndexriyaPas encore d'évaluation
- Full Download Test Bank For Health Psychology Well Being in A Diverse World 4th by Gurung PDF Full ChapterDocument36 pagesFull Download Test Bank For Health Psychology Well Being in A Diverse World 4th by Gurung PDF Full Chapterbiscuitunwist20bsg4100% (18)
- The Future of Psychology Practice and Science PDFDocument15 pagesThe Future of Psychology Practice and Science PDFPaulo César MesaPas encore d'évaluation
- Internal Rules of Procedure Sangguniang BarangayDocument37 pagesInternal Rules of Procedure Sangguniang Barangayhearty sianenPas encore d'évaluation
- Type of MorphologyDocument22 pagesType of MorphologyIntan DwiPas encore d'évaluation