Vous aimerez peut-être aussi
- Presentation 1Document3 pagesPresentation 1Javed HussainPas encore d'évaluation
- List of Math SymbolsDocument164 pagesList of Math SymbolsBob CaPas encore d'évaluation
- Sde Lecture PDFDocument56 pagesSde Lecture PDFradioheadddddPas encore d'évaluation
- DG Notes PDFDocument54 pagesDG Notes PDFJaved HussainPas encore d'évaluation
- C1Document196 pagesC1Javed HussainPas encore d'évaluation
- DG Notes PDFDocument54 pagesDG Notes PDFJaved HussainPas encore d'évaluation
- Tensor PDFDocument53 pagesTensor PDFCristhian ValladaresPas encore d'évaluation
- Mynpower Bill 20 11 2013 PDFDocument5 pagesMynpower Bill 20 11 2013 PDFJaved HussainPas encore d'évaluation
- Stochastic Modelling in Finance - It o Lemma and QuadraticDocument4 pagesStochastic Modelling in Finance - It o Lemma and QuadraticTu ShirotaPas encore d'évaluation
- Ilmul IqtisadDocument130 pagesIlmul IqtisadJaved Hussain100% (1)
- 10 1 1 17 4670Document35 pages10 1 1 17 4670Javed HussainPas encore d'évaluation
- 146 Metric SpacesDocument1 page146 Metric SpacesJaved HussainPas encore d'évaluation
- ArticleDocument4 pagesArticleJaved HussainPas encore d'évaluation
- Van Casteren - 1980 - Strongly Continuous Semi GroupsDocument207 pagesVan Casteren - 1980 - Strongly Continuous Semi GroupsJaved HussainPas encore d'évaluation
- (Javed)Document4 pages(Javed)Javed HussainPas encore d'évaluation
- MFE ManualDocument549 pagesMFE Manualashtan100% (1)
- Hujjat Allah Al-Baligha (Arabic / Urdu) by Shah Waliullah / Shah Wali UllahDocument1 pageHujjat Allah Al-Baligha (Arabic / Urdu) by Shah Waliullah / Shah Wali UllahRana Mazhar75% (4)
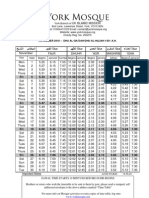
- Namza November Time TableDocument1 pageNamza November Time TableJaved HussainPas encore d'évaluation
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (119)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- 12 Identify and Interpret GradientsDocument2 pages12 Identify and Interpret GradientsHuzaifa brightPas encore d'évaluation
- Transformation of Plane Stress and Strain PDFDocument14 pagesTransformation of Plane Stress and Strain PDFFitsum OmituPas encore d'évaluation
- Abbott - Understanding Analysis Problem SetDocument4 pagesAbbott - Understanding Analysis Problem SetFeynman Liang0% (1)
- Mechanical VibrationsDocument131 pagesMechanical Vibrationsumudum.civilengineerPas encore d'évaluation
- Work TheoryDocument57 pagesWork TheoryIftekhar AliPas encore d'évaluation
- Graph of Polynomial FunctionDocument27 pagesGraph of Polynomial FunctionJulie IsmaelPas encore d'évaluation
- Chapter 7: The Root Locus MethodDocument13 pagesChapter 7: The Root Locus MethodPankaj Kumar MehtaPas encore d'évaluation
- GenmathDocument2 pagesGenmathJosafatPas encore d'évaluation
- Chapter 4 LimitDocument32 pagesChapter 4 Limitsyamim ikram bin mohd zamriPas encore d'évaluation
- Lecture Notes Probability Theory (5thsem) 3Document9 pagesLecture Notes Probability Theory (5thsem) 3MrigankaPas encore d'évaluation
- Straight Line Equation of A Straight Line 3x - 4y 7: Answer All Questions. For Examiner' S UseDocument22 pagesStraight Line Equation of A Straight Line 3x - 4y 7: Answer All Questions. For Examiner' S UseDavinAvalaniPas encore d'évaluation
- 1981-Dual-Rotation PropellersDocument49 pages1981-Dual-Rotation PropellersJianbo JiangPas encore d'évaluation
- Full Solutions 2018: Mathematics Paper 2Document14 pagesFull Solutions 2018: Mathematics Paper 2Raphael Diego KeesPas encore d'évaluation
- HW10 483 Fall17Document2 pagesHW10 483 Fall17Yagya Raj JoshiPas encore d'évaluation
- Bu I 7 - Dynamic Programming AlgorithmsDocument119 pagesBu I 7 - Dynamic Programming AlgorithmsPhạm Gia DũngPas encore d'évaluation
- Axisymmetric Shrink Fit Analysis and DesignDocument10 pagesAxisymmetric Shrink Fit Analysis and DesignParag NaikPas encore d'évaluation
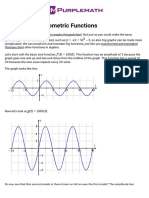
- Graphing Trigonometric Functions - Purplemath PDFDocument7 pagesGraphing Trigonometric Functions - Purplemath PDFmatthewPas encore d'évaluation
- 4 - The Finite Volume Method For Convection-Diffusion Problems - 2Document25 pages4 - The Finite Volume Method For Convection-Diffusion Problems - 2Abaziz Mousa OutlawZzPas encore d'évaluation
- G10 Circinus - Science 10 GradesDocument32 pagesG10 Circinus - Science 10 GradesGirlie Mae PondiasPas encore d'évaluation
- (2018) MA1103-Business Mathematics IDocument37 pages(2018) MA1103-Business Mathematics ISaskia Dila SagataPas encore d'évaluation
- Numerical Methods Test 1Document17 pagesNumerical Methods Test 1Ashley StraubPas encore d'évaluation
- Complex Number With SolutionDocument13 pagesComplex Number With SolutionVijay Pratap Singh RathorePas encore d'évaluation
- Desirability FunctionDocument15 pagesDesirability FunctionDrPeter de BarcelonaPas encore d'évaluation
- 2004 State Math Contest: Junior Pretest - SolutionsDocument6 pages2004 State Math Contest: Junior Pretest - Solutionsbhaskar rayPas encore d'évaluation
- Alg Linear Axminusbeqc All PDFDocument20 pagesAlg Linear Axminusbeqc All PDFNurulPas encore d'évaluation
- Basic Advanced Linear AlgebraDocument10 pagesBasic Advanced Linear Algebraarmando licanda BSE Math 2APas encore d'évaluation
- Solving A Gas-Lift Optimization Problem by Dynamic ProgrammingDocument27 pagesSolving A Gas-Lift Optimization Problem by Dynamic ProgrammingCehanPas encore d'évaluation
- Mathematics for ML: Linear Algebra Formula SheetDocument1 pageMathematics for ML: Linear Algebra Formula SheetBobPas encore d'évaluation
- Numerical Solutions of The Euler Equations For Steady Flow ProblemsDocument455 pagesNumerical Solutions of The Euler Equations For Steady Flow ProblemsКонстантинPas encore d'évaluation
- Pil Unit Review2015 KeyDocument6 pagesPil Unit Review2015 Keyapi-296347043Pas encore d'évaluation