Vous aimerez peut-être aussi
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- E-Paper Technology DocumentDocument32 pagesE-Paper Technology DocumentZuber Md54% (13)
- Automatic Railway Gate ControlDocument14 pagesAutomatic Railway Gate Controlapi-26871643100% (23)
- Anas - Echo CancellationDocument27 pagesAnas - Echo Cancellationapi-26871643100% (1)
- Munday CH 5.3-5.3.1 Skopos TheoryDocument11 pagesMunday CH 5.3-5.3.1 Skopos TheoryEvelina Tutlyte100% (1)
- Microwave Link Technology in CommunicatioDocument15 pagesMicrowave Link Technology in Communicatioapi-26871643Pas encore d'évaluation
- Improved Security For Credit and Debit CardsDocument11 pagesImproved Security For Credit and Debit Cardsapi-26871643Pas encore d'évaluation
- SUKUNATHDocument31 pagesSUKUNATHapi-26871643Pas encore d'évaluation
- Dynamic Power Management For Non-Stationary Service RequestDocument14 pagesDynamic Power Management For Non-Stationary Service Requestapi-26871643Pas encore d'évaluation
- Emerging Trends in Electronics NanobioelectronicsDocument13 pagesEmerging Trends in Electronics Nanobioelectronicsapi-26871643100% (2)
- Blue Tooth Security Implemented Using VHDLDocument11 pagesBlue Tooth Security Implemented Using VHDLapi-26871643Pas encore d'évaluation
- Autonomus Mobile RobotDocument19 pagesAutonomus Mobile Robotapi-268716430% (1)
- Aquatic RobotDocument8 pagesAquatic Robotapi-268716430% (1)
- A Futuristic Heterogeneous WirelessDocument17 pagesA Futuristic Heterogeneous Wirelessapi-26871643100% (1)
- 4GMOBILESDocument11 pages4GMOBILESapi-26871643100% (1)
- Opportunities & Threats For Implementation of 4G Cellular NetworksDocument13 pagesOpportunities & Threats For Implementation of 4G Cellular Networksapi-26871643Pas encore d'évaluation
- Operating Check List For Disel Generator: Date: TimeDocument2 pagesOperating Check List For Disel Generator: Date: TimeAshfaq BilwarPas encore d'évaluation
- Manufacturing Systems-Fleximble Manufacturing Application-Case Study of ZimbabweDocument5 pagesManufacturing Systems-Fleximble Manufacturing Application-Case Study of Zimbabwejosphat muchatutaPas encore d'évaluation
- PDFDocument2 pagesPDFSalim AshorPas encore d'évaluation
- '11!01!05 NEC Femtocell Solution - Femto Specific FeaturesDocument25 pages'11!01!05 NEC Femtocell Solution - Femto Specific FeaturesBudi Agus SetiawanPas encore d'évaluation
- F 1069 - 87 R99 - Rjewnjk - PDFDocument6 pagesF 1069 - 87 R99 - Rjewnjk - PDFRománBarciaVazquezPas encore d'évaluation
- StarbucksDocument19 pagesStarbucksNimah SaeedPas encore d'évaluation
- MapObjects inVBNET PDFDocument34 pagesMapObjects inVBNET PDFWanly PereiraPas encore d'évaluation
- Silabus Reading VDocument4 pagesSilabus Reading VAndi AsrifanPas encore d'évaluation
- Dap 018 ADocument28 pagesDap 018 AajoaomvPas encore d'évaluation
- Needle en b275-293Document19 pagesNeedle en b275-293ajeeshsbabuPas encore d'évaluation
- Director, Policy and Research (SEG 3 Et Al - Ministry of Culture, Gender, Entertainment and Sport PDFDocument12 pagesDirector, Policy and Research (SEG 3 Et Al - Ministry of Culture, Gender, Entertainment and Sport PDFvernon whitePas encore d'évaluation
- PSS Report206Document90 pagesPSS Report206Abhishek TiwariPas encore d'évaluation
- HRTC RoutesDiverted Via KiratpurManali Four LaneDocument9 pagesHRTC RoutesDiverted Via KiratpurManali Four Lanepibope6477Pas encore d'évaluation
- Activities Pm.Document13 pagesActivities Pm.jona llamasPas encore d'évaluation
- Industrial Visit Report OnDocument41 pagesIndustrial Visit Report OnLalit SharmaPas encore d'évaluation
- Updated Resume Kelly oDocument2 pagesUpdated Resume Kelly oapi-254046653Pas encore d'évaluation
- Oracle - Fusion - Middleware - 11g ADF I Volume IDocument374 pagesOracle - Fusion - Middleware - 11g ADF I Volume IMaged AliPas encore d'évaluation
- 4 Litre Closed SamplersDocument3 pages4 Litre Closed Samplerslimhockkin3766Pas encore d'évaluation
- ALR Compact Repeater: Future On DemandDocument62 pagesALR Compact Repeater: Future On DemandmickycachoperroPas encore d'évaluation
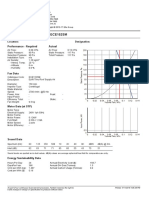
- Technical Data - Fan Model ECE152SM: Location: Designation: Performance - Required ActualDocument2 pagesTechnical Data - Fan Model ECE152SM: Location: Designation: Performance - Required ActualJPas encore d'évaluation
- AIS - 007 - Rev 5 - Table - 1Document21 pagesAIS - 007 - Rev 5 - Table - 1Vino Joseph VarghesePas encore d'évaluation
- Usermanual en Manual Arium Bagtanks WH26010 ADocument33 pagesUsermanual en Manual Arium Bagtanks WH26010 AԳոռ ԽաչատրյանPas encore d'évaluation
- Be Katalog-Grabenfr 2013 Engl RZ KleinDocument36 pagesBe Katalog-Grabenfr 2013 Engl RZ Kleincherif100% (1)
- Motor Driver Board Tb6560-5axisDocument14 pagesMotor Driver Board Tb6560-5axisAli Asghar MuzzaffarPas encore d'évaluation
- En Mirage Classic Installation GuideDocument4 pagesEn Mirage Classic Installation GuideMykel VelasquezPas encore d'évaluation
- Marketing Information Systems & Market ResearchDocument20 pagesMarketing Information Systems & Market ResearchJalaj Mathur100% (1)
- Mobile Networks and ApplicationsDocument232 pagesMobile Networks and ApplicationsrabrajPas encore d'évaluation