Vous aimerez peut-être aussi
- Human Genome Structure, Function and Clinical ConsiderationsD'EverandHuman Genome Structure, Function and Clinical ConsiderationsLuciana Amaral HaddadPas encore d'évaluation
- Wang2008-Diploid Genome Sequence of An Asian IndividualDocument7 pagesWang2008-Diploid Genome Sequence of An Asian Individualiulia andreeaPas encore d'évaluation
- Summary of The Gene: by Siddhartha Mukherjee | Includes AnalysisD'EverandSummary of The Gene: by Siddhartha Mukherjee | Includes AnalysisPas encore d'évaluation
- David G. Wang, Et Al. - Large-Scale Identification, Mapping, and Genotyping of Single-Nucleotide Polymorphisms in The Human GenomeDocument7 pagesDavid G. Wang, Et Al. - Large-Scale Identification, Mapping, and Genotyping of Single-Nucleotide Polymorphisms in The Human GenomeYopghm698Pas encore d'évaluation
- Human Genome ProjectDocument17 pagesHuman Genome Projectanon_306048523Pas encore d'évaluation
- GenomicsDocument8 pagesGenomicsPRATAPPas encore d'évaluation
- Human Genemoe ProjectDocument14 pagesHuman Genemoe Projectamaya mohantyPas encore d'évaluation
- Human Genome ProjectDocument7 pagesHuman Genome ProjectAfrozPas encore d'évaluation
- Identification and Characterization of Essential Genes in The Human GenomeDocument7 pagesIdentification and Characterization of Essential Genes in The Human Genome戴义宾Pas encore d'évaluation
- Science 2013 Mali 823 6Document5 pagesScience 2013 Mali 823 6Ronilo Jose Danila FloresPas encore d'évaluation
- Genome Res.-2013-Alföldi-1063-8Document7 pagesGenome Res.-2013-Alföldi-1063-8Yamile A Rodríguez RiascosPas encore d'évaluation
- Gene CloningDocument17 pagesGene CloningOmaraye JoshuaPas encore d'évaluation
- 2012-9..4-Whole-Exome Sequencing Combined With Functional Genomics Reveals Novel Candidate Driver Cancer Genes in Endometrial CancerDocument10 pages2012-9..4-Whole-Exome Sequencing Combined With Functional Genomics Reveals Novel Candidate Driver Cancer Genes in Endometrial Cancershidis1028Pas encore d'évaluation
- 12 BioDocument2 pages12 BioJdjdjxjdjPas encore d'évaluation
- HGPDocument3 pagesHGPSnegapriya SivaramanPas encore d'évaluation
- 1723 UploadDocument5 pages1723 UploadbodhidharPas encore d'évaluation
- 2021 12 08 471837 FullDocument39 pages2021 12 08 471837 FulljojojazzprogPas encore d'évaluation
- Copy NoDocument9 pagesCopy NoNaresh KoneruPas encore d'évaluation
- Human GenomeDocument35 pagesHuman GenomeSafia DurraniPas encore d'évaluation
- In DelDocument11 pagesIn DelVictor OsvaldoPas encore d'évaluation
- David A. Wheeler Et Al - The Complete Genome of An Individual by Massively Parallel DNA SequencingDocument6 pagesDavid A. Wheeler Et Al - The Complete Genome of An Individual by Massively Parallel DNA SequencingYopghm698Pas encore d'évaluation
- HHS Public Access: The UCSC Cancer Genomics BrowserDocument4 pagesHHS Public Access: The UCSC Cancer Genomics BrowserMohiuddin JishanPas encore d'évaluation
- The Mouse As A Model For Understanding Chronic Diseases of Aging: The Histopathologic Basis of Aging in Inbred MiceDocument9 pagesThe Mouse As A Model For Understanding Chronic Diseases of Aging: The Histopathologic Basis of Aging in Inbred MiceashorammarPas encore d'évaluation
- Note Jan 30 2014Document8 pagesNote Jan 30 2014api-243334077Pas encore d'évaluation
- Farm Animal Genomics and Informatics: An Update: Ahmed Fadiel, Ifeanyi Anidi and Kenneth D. EichenbaumDocument11 pagesFarm Animal Genomics and Informatics: An Update: Ahmed Fadiel, Ifeanyi Anidi and Kenneth D. EichenbaumFabian HdezPas encore d'évaluation
- Human Genome Project Class 12Document7 pagesHuman Genome Project Class 12davidkumar54dkPas encore d'évaluation
- HHS Public Access: Single-Cell Multiomic Analysis Identifies Regulatory Programs in Mixed-Phenotype Acute LeukemiaDocument26 pagesHHS Public Access: Single-Cell Multiomic Analysis Identifies Regulatory Programs in Mixed-Phenotype Acute LeukemiaAlexis PaivaPas encore d'évaluation
- Fredrik Sterky and Joakim Lundeberg - Sequence Analysis of Genes and GenomesDocument31 pagesFredrik Sterky and Joakim Lundeberg - Sequence Analysis of Genes and GenomesYopghm698Pas encore d'évaluation
- Human Genome Project-1Document3 pagesHuman Genome Project-1Hadiya FatimaPas encore d'évaluation
- Initial Impact of The Sequencing of The Human GenomeDocument11 pagesInitial Impact of The Sequencing of The Human GenomeMariano PerezPas encore d'évaluation
- Genomics and Its Impact On Science and Society: A PrimerDocument12 pagesGenomics and Its Impact On Science and Society: A PrimerAdan VegaPas encore d'évaluation
- Gen 1801619Document10 pagesGen 1801619Luis HernanPas encore d'évaluation
- Tempo and Mode of Genome PDFDocument30 pagesTempo and Mode of Genome PDFGinna SolartePas encore d'évaluation
- Black & White Deliver Card (1) - WPS OfficeDocument28 pagesBlack & White Deliver Card (1) - WPS Officelinkgogo69Pas encore d'évaluation
- T H G P: HE Uman Enome RojectDocument28 pagesT H G P: HE Uman Enome RojectUpendra Sharma Sulibele100% (1)
- The Human Genome ProjectDocument22 pagesThe Human Genome ProjectAashianaThiyam100% (1)
- tmp564B TMPDocument3 pagestmp564B TMPFrontiersPas encore d'évaluation
- 2012 122tr PHDDocument122 pages2012 122tr PHDNguyễn Tiến HồngPas encore d'évaluation
- Comparison of Four Species-Delimitation Methods Applied To A DNA Barcode Data Set of Insect Larvae For Use in Routine BioassessmentDocument11 pagesComparison of Four Species-Delimitation Methods Applied To A DNA Barcode Data Set of Insect Larvae For Use in Routine BioassessmentLu ChiberryPas encore d'évaluation
- 10.1007@s11427 020 1709 6Document4 pages10.1007@s11427 020 1709 6Nouri RaidPas encore d'évaluation
- Research in Veterinary ScienceDocument6 pagesResearch in Veterinary ScienceSyabillaPas encore d'évaluation
- Human Genome ProjectDocument11 pagesHuman Genome ProjectAmaraaZoyaPas encore d'évaluation
- Human Genome Project and DNA FingerprintingDocument2 pagesHuman Genome Project and DNA Fingerprintingnicholasmith80% (10)
- Age Piche PrintDocument3 pagesAge Piche PrintSYED ADNANPas encore d'évaluation
- Aneuploidy ConcordanceDocument12 pagesAneuploidy ConcordancejuanPas encore d'évaluation
- RNA-Guided Human GenomeDocument5 pagesRNA-Guided Human GenomeVictor RoticivPas encore d'évaluation
- Adams Science 1999Document11 pagesAdams Science 1999vnq6gd6qbxPas encore d'évaluation
- Progeria Gene TherapyDocument6 pagesProgeria Gene TherapyClarissa OueiPas encore d'évaluation
- Liquid Biopsy Using Ascitic Fluid and Pleural Effusion Supernatants For Genomic Profiling in Gastrointestinal and Lung CancersDocument10 pagesLiquid Biopsy Using Ascitic Fluid and Pleural Effusion Supernatants For Genomic Profiling in Gastrointestinal and Lung CancersCámara de Comercio de CádizPas encore d'évaluation
- Solution Manual For Human Heredity Principles and Issues 11th EditionDocument7 pagesSolution Manual For Human Heredity Principles and Issues 11th Editionlardavileou0Pas encore d'évaluation
- 1000 Genomes ProjectDocument10 pages1000 Genomes Projectwilliam919Pas encore d'évaluation
- What Is DNADocument4 pagesWhat Is DNApranav shuklaPas encore d'évaluation
- Human Genome Project: Project Submitted For All India Senior Secondary School Practical Examination 2021-22Document15 pagesHuman Genome Project: Project Submitted For All India Senior Secondary School Practical Examination 2021-22Mariappan NatarajanPas encore d'évaluation
- Nucleotides Haploid Reference GenomeDocument2 pagesNucleotides Haploid Reference GenomeDaniH46Pas encore d'évaluation
- Metaanasis Opcion 3Document13 pagesMetaanasis Opcion 3Jennifer EstefaniaPas encore d'évaluation
- Eriksson 2010Document21 pagesEriksson 2010ANDRE LEONARD FARFAN SUAREZPas encore d'évaluation
- Nih Public Access: The Genotype-Tissue Expression (Gtex) ProjectDocument13 pagesNih Public Access: The Genotype-Tissue Expression (Gtex) ProjectSandra Milena Sanabria BarreraPas encore d'évaluation
- Chapter 4 - Genome Informatics Present Status and F - 2022 - Bioinformatics inDocument13 pagesChapter 4 - Genome Informatics Present Status and F - 2022 - Bioinformatics inMuhammad KamranPas encore d'évaluation
- Science 2012 Marin Burgin 1238 42Document6 pagesScience 2012 Marin Burgin 1238 42Gojan JebuzPas encore d'évaluation
- Chromosome-Scale Genome Assembly of Lepus OiostoluDocument7 pagesChromosome-Scale Genome Assembly of Lepus OiostoluMuhammad UsamaPas encore d'évaluation
- J. Arsuaga - DNA SupercoilingDocument24 pagesJ. Arsuaga - DNA SupercoilingYopghm698Pas encore d'évaluation
- Energetic and Structural Inter-Relationship Between and The Right-To Left-Handed Z Helix Transitions in Plasmids Supercoiling RecombinantDocument7 pagesEnergetic and Structural Inter-Relationship Between and The Right-To Left-Handed Z Helix Transitions in Plasmids Supercoiling RecombinantYopghm698Pas encore d'évaluation
- Nathaniel G. Hunt and John E. Hearst - Elastic Model of DNA Supercoiling in The Infinite-Length LimitDocument8 pagesNathaniel G. Hunt and John E. Hearst - Elastic Model of DNA Supercoiling in The Infinite-Length LimitYopghm698Pas encore d'évaluation
- Cheri Shakiban - Signature Curves in Classifying DNA SupercoilsDocument49 pagesCheri Shakiban - Signature Curves in Classifying DNA SupercoilsYopghm698Pas encore d'évaluation
- V.L. Golo and E.I. Kats - Model of The Splitting of DNA MoleculesDocument6 pagesV.L. Golo and E.I. Kats - Model of The Splitting of DNA MoleculesYopghm698Pas encore d'évaluation
- Myeong-Sok Lee and William T. Garrard - Positive DNA Supercoiling Generates A Chromatin Conformation Characteristic of Highly Active GenesDocument5 pagesMyeong-Sok Lee and William T. Garrard - Positive DNA Supercoiling Generates A Chromatin Conformation Characteristic of Highly Active GenesYopghm698Pas encore d'évaluation
- Large-Scale Effects of Transcriptional DNA Supercoiling in VivoDocument12 pagesLarge-Scale Effects of Transcriptional DNA Supercoiling in VivoYopghm698Pas encore d'évaluation
- Alexander V. Vologodskii - Distributions of Knots and Links in Circular DNADocument18 pagesAlexander V. Vologodskii - Distributions of Knots and Links in Circular DNAYopghm698Pas encore d'évaluation
- Jeanette Nangreave, Hao Yan and Yan Liu - Studies of Thermal Stability of Multivalent DNA Hybridization in A Nanostructured SystemDocument9 pagesJeanette Nangreave, Hao Yan and Yan Liu - Studies of Thermal Stability of Multivalent DNA Hybridization in A Nanostructured SystemYopghm698Pas encore d'évaluation
- Erika Ercolini, Francesco Valle, Jozef Adamcik, Guillaume Witz, Ralf Metzler, Paolo de Los Rios, Joaquim Roca and Giovanni Dietler - Fractal Dimension and Localization of DNA KnotsDocument4 pagesErika Ercolini, Francesco Valle, Jozef Adamcik, Guillaume Witz, Ralf Metzler, Paolo de Los Rios, Joaquim Roca and Giovanni Dietler - Fractal Dimension and Localization of DNA KnotsYopghm698Pas encore d'évaluation
- Xiaoyan R. Bao, Heun Jin Lee, and Stephen R. Quake - Behavior of Complex Knots in Single DNA MoleculesDocument4 pagesXiaoyan R. Bao, Heun Jin Lee, and Stephen R. Quake - Behavior of Complex Knots in Single DNA MoleculesYopghm698Pas encore d'évaluation
- Julia Collins - DNA, or Knot DNA? That Is The QuestionDocument58 pagesJulia Collins - DNA, or Knot DNA? That Is The QuestionYopghm698Pas encore d'évaluation
- Supercoiling of DNA: 1. TopologyDocument29 pagesSupercoiling of DNA: 1. TopologybiolimPas encore d'évaluation
- Jenny Tompkins - Modeling DNA With Knot Theory: An IntroductionDocument23 pagesJenny Tompkins - Modeling DNA With Knot Theory: An IntroductionYopghm698Pas encore d'évaluation
- Dna Topology: Introduction ToDocument31 pagesDna Topology: Introduction ToYopghm698Pas encore d'évaluation
- Martin Karplus - Molecular Dynamics of Biological Macromolecules: A Brief History and PerspectiveDocument9 pagesMartin Karplus - Molecular Dynamics of Biological Macromolecules: A Brief History and PerspectiveYopghm698Pas encore d'évaluation
- Nadrian C. Seeman - DNA Nanotechnology: Novel DNA ConstructionsDocument25 pagesNadrian C. Seeman - DNA Nanotechnology: Novel DNA ConstructionsYopghm698Pas encore d'évaluation
- Alexey Y. Koyfman, Sergei N. Magonov and Norbert O. Reich - Self-Assembly of DNA Arrays Into Multilayer StacksDocument7 pagesAlexey Y. Koyfman, Sergei N. Magonov and Norbert O. Reich - Self-Assembly of DNA Arrays Into Multilayer StacksYopghm698Pas encore d'évaluation
- E Starikov - Molecular Modelling of Nucleic Acids: How Quantum Chemistry Might HelpDocument49 pagesE Starikov - Molecular Modelling of Nucleic Acids: How Quantum Chemistry Might HelpYopghm698Pas encore d'évaluation
- Peter Schuster - Evolutionary DynamicsDocument75 pagesPeter Schuster - Evolutionary DynamicsYopghm698Pas encore d'évaluation
- Chenxiang Lin, Yonggang Ke, Zhe Li, James H. Wang, Yan Liu and Hao Yan - Mirror Image DNA Nanostructures For Chiral Supramolecular AssembliesDocument8 pagesChenxiang Lin, Yonggang Ke, Zhe Li, James H. Wang, Yan Liu and Hao Yan - Mirror Image DNA Nanostructures For Chiral Supramolecular AssembliesYopghm698Pas encore d'évaluation
- Isabel K. Darcy - Modeling protein-DNA Complexes With TanglesDocument19 pagesIsabel K. Darcy - Modeling protein-DNA Complexes With TanglesYopghm698Pas encore d'évaluation
- Kurt V. Gothelf and Thomas H. LaBean - DNA-programmed Assembly of NanostructuresDocument15 pagesKurt V. Gothelf and Thomas H. LaBean - DNA-programmed Assembly of NanostructuresYopghm698Pas encore d'évaluation
- Johnjoe McFadden and Jim Al-Khalili - A Quantum Mechanical Model of Adaptive MutationDocument9 pagesJohnjoe McFadden and Jim Al-Khalili - A Quantum Mechanical Model of Adaptive MutationYopghm698Pas encore d'évaluation
- Hiroaki Yamada and Kazumoto Iguchi - Some Effective Tight-Binding Models For Electrons in DNA Conduction:A ReviewDocument25 pagesHiroaki Yamada and Kazumoto Iguchi - Some Effective Tight-Binding Models For Electrons in DNA Conduction:A ReviewYopghm698Pas encore d'évaluation
- Yaakov Benenson - Biocomputers: From Test Tubes To Live CellsDocument19 pagesYaakov Benenson - Biocomputers: From Test Tubes To Live CellsYopghm698Pas encore d'évaluation
- Jeffrey J. Tabor, Matthew Levy and Andrew D. Ellington - Deoxyribozymes That Recode Sequence InformationDocument7 pagesJeffrey J. Tabor, Matthew Levy and Andrew D. Ellington - Deoxyribozymes That Recode Sequence InformationYopghm698Pas encore d'évaluation
- Scott K. Silverman - Control of Macromolecular Structure and Function Using Covalently Attached Doublestranded DNA ConstraintsDocument6 pagesScott K. Silverman - Control of Macromolecular Structure and Function Using Covalently Attached Doublestranded DNA ConstraintsYopghm698Pas encore d'évaluation
- Margit Haahr Hansen Et Al - A Yoctoliter-Scale DNA Reactor For Small-Molecule EvolutionDocument7 pagesMargit Haahr Hansen Et Al - A Yoctoliter-Scale DNA Reactor For Small-Molecule EvolutionYopghm698Pas encore d'évaluation
- Structural Fluctuations and Quantum Transport Through DNA Molecular Wires: A Combined Molecular Dynamics and Model Hamiltonian ApproachDocument20 pagesStructural Fluctuations and Quantum Transport Through DNA Molecular Wires: A Combined Molecular Dynamics and Model Hamiltonian ApproachYopghm698Pas encore d'évaluation
- BIO50 Lab Report: Cellular RespirationDocument8 pagesBIO50 Lab Report: Cellular RespirationSarah Carat17Pas encore d'évaluation
- Biyani's Think Tank: Cell Biology & GeneticsDocument81 pagesBiyani's Think Tank: Cell Biology & GeneticsAkshay chandrakarPas encore d'évaluation
- Environment The Science Behind The Stories Canadian 3rd Edition Whitgott Test BankDocument26 pagesEnvironment The Science Behind The Stories Canadian 3rd Edition Whitgott Test Bankfreyahypatias7j100% (28)
- Science 10 - 2ND Summative TestDocument2 pagesScience 10 - 2ND Summative Testalmira villarealPas encore d'évaluation
- Lesson 2 Transport MechanismDocument3 pagesLesson 2 Transport MechanismMervin GapasinPas encore d'évaluation
- Cancer Letters: M.C.F. Simões, J.J.S. Sousa, A.A.C.C. PaisDocument35 pagesCancer Letters: M.C.F. Simões, J.J.S. Sousa, A.A.C.C. PaisAbdul HaseebPas encore d'évaluation
- Biotechnology 2Document8 pagesBiotechnology 2MB LotertePas encore d'évaluation
- K-2816 Life Sciences (Paper-III)Document16 pagesK-2816 Life Sciences (Paper-III)Surya DMPas encore d'évaluation
- Life Science Previous Paper 2017 DecDocument38 pagesLife Science Previous Paper 2017 DecShilpi PriyaPas encore d'évaluation
- Apoptotic and Non-Apoptotic Cell DeathDocument186 pagesApoptotic and Non-Apoptotic Cell DeathKoaLa AyuNdhaPas encore d'évaluation
- Michael Lynch - The Origins of Genome Architecture-Sinauer (2007)Document403 pagesMichael Lynch - The Origins of Genome Architecture-Sinauer (2007)SashaPas encore d'évaluation
- Sample 5412Document21 pagesSample 5412Raman MeetPas encore d'évaluation
- Instructions: Reflect On The Topics That Were Previously Discussed. Write at Least Three (3) Things Per TopicDocument2 pagesInstructions: Reflect On The Topics That Were Previously Discussed. Write at Least Three (3) Things Per TopicGuevarra KeithPas encore d'évaluation
- AP Biology Unit 1 Biochemistry Cheat SheetDocument2 pagesAP Biology Unit 1 Biochemistry Cheat Sheetf2vn65zbh9Pas encore d'évaluation
- Cell Physiology Week 2 Revised Tabrez Specialized Organels-Cytoplasm 1445 HDocument40 pagesCell Physiology Week 2 Revised Tabrez Specialized Organels-Cytoplasm 1445 H6258c7pxkjPas encore d'évaluation
- Biotech LM1-Quarter4Document16 pagesBiotech LM1-Quarter4Krystel Mae Pagela OredinaPas encore d'évaluation
- Reproduction and Growth in Bacteria: By: Hafiza Asfa Shafique Microbiology BS Biotechnology VDocument26 pagesReproduction and Growth in Bacteria: By: Hafiza Asfa Shafique Microbiology BS Biotechnology VJawadPas encore d'évaluation
- Biotechnology Principles - ProcessesDocument11 pagesBiotechnology Principles - ProcessesTulika BholaPas encore d'évaluation
- RNAi NotesDocument6 pagesRNAi Notesaman jaiswalPas encore d'évaluation
- Fadwa BadranaDocument28 pagesFadwa BadranaDadoPas encore d'évaluation
- Bacterial Pili (I)Document4 pagesBacterial Pili (I)somchaisPas encore d'évaluation
- General Characteristics of VirusesDocument3 pagesGeneral Characteristics of VirusesLyraski BalawisPas encore d'évaluation
- 0 s2.0 S0926669021011146 MainDocument10 pages0 s2.0 S0926669021011146 MainOmar KHELILPas encore d'évaluation
- Chapter 20: Gene Isolation and ManipulationDocument40 pagesChapter 20: Gene Isolation and ManipulationDeepakshee DubeyPas encore d'évaluation
- Revised 2019 - EPI Monitoring Checklist For Outreach SessionDocument2 pagesRevised 2019 - EPI Monitoring Checklist For Outreach SessionAyaz Ahmed100% (1)
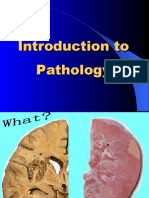
- Introduction To PathologyDocument21 pagesIntroduction To PathologylavanyagunduPas encore d'évaluation
- MARCH 23bills TALLY OUTSTANDING RECEIVABLE LIST 06.03.2023Document12 pagesMARCH 23bills TALLY OUTSTANDING RECEIVABLE LIST 06.03.2023radha gPas encore d'évaluation
- Quiz 1 - MacromoleculesDocument2 pagesQuiz 1 - MacromoleculesJohn Kevin NochePas encore d'évaluation
- CDNA Lab Report - Docx2Document4 pagesCDNA Lab Report - Docx2cxs5278100% (1)
- Pikachurin: EGFLAM GeneDocument6 pagesPikachurin: EGFLAM Genefelipe smithPas encore d'évaluation
- A Brief History of Intelligence: Evolution, AI, and the Five Breakthroughs That Made Our BrainsD'EverandA Brief History of Intelligence: Evolution, AI, and the Five Breakthroughs That Made Our BrainsÉvaluation : 4.5 sur 5 étoiles4.5/5 (6)
- When the Body Says No by Gabor Maté: Key Takeaways, Summary & AnalysisD'EverandWhen the Body Says No by Gabor Maté: Key Takeaways, Summary & AnalysisÉvaluation : 3.5 sur 5 étoiles3.5/5 (2)
- Why We Die: The New Science of Aging and the Quest for ImmortalityD'EverandWhy We Die: The New Science of Aging and the Quest for ImmortalityÉvaluation : 4 sur 5 étoiles4/5 (3)
- The Molecule of More: How a Single Chemical in Your Brain Drives Love, Sex, and Creativity--and Will Determine the Fate of the Human RaceD'EverandThe Molecule of More: How a Single Chemical in Your Brain Drives Love, Sex, and Creativity--and Will Determine the Fate of the Human RaceÉvaluation : 4.5 sur 5 étoiles4.5/5 (517)
- Masterminds: Genius, DNA, and the Quest to Rewrite LifeD'EverandMasterminds: Genius, DNA, and the Quest to Rewrite LifePas encore d'évaluation
- Gut: the new and revised Sunday Times bestsellerD'EverandGut: the new and revised Sunday Times bestsellerÉvaluation : 4 sur 5 étoiles4/5 (393)
- Tales from Both Sides of the Brain: A Life in NeuroscienceD'EverandTales from Both Sides of the Brain: A Life in NeuroscienceÉvaluation : 3 sur 5 étoiles3/5 (18)
- Who's in Charge?: Free Will and the Science of the BrainD'EverandWho's in Charge?: Free Will and the Science of the BrainÉvaluation : 4 sur 5 étoiles4/5 (65)
- Gut: The Inside Story of Our Body's Most Underrated Organ (Revised Edition)D'EverandGut: The Inside Story of Our Body's Most Underrated Organ (Revised Edition)Évaluation : 4 sur 5 étoiles4/5 (411)
- 10% Human: How Your Body's Microbes Hold the Key to Health and HappinessD'Everand10% Human: How Your Body's Microbes Hold the Key to Health and HappinessÉvaluation : 4 sur 5 étoiles4/5 (33)
- Fast Asleep: Improve Brain Function, Lose Weight, Boost Your Mood, Reduce Stress, and Become a Better SleeperD'EverandFast Asleep: Improve Brain Function, Lose Weight, Boost Your Mood, Reduce Stress, and Become a Better SleeperÉvaluation : 4.5 sur 5 étoiles4.5/5 (15)
- All That Remains: A Renowned Forensic Scientist on Death, Mortality, and Solving CrimesD'EverandAll That Remains: A Renowned Forensic Scientist on Death, Mortality, and Solving CrimesÉvaluation : 4.5 sur 5 étoiles4.5/5 (397)
- Undeniable: How Biology Confirms Our Intuition That Life Is DesignedD'EverandUndeniable: How Biology Confirms Our Intuition That Life Is DesignedÉvaluation : 4 sur 5 étoiles4/5 (11)
- The Ancestor's Tale: A Pilgrimage to the Dawn of EvolutionD'EverandThe Ancestor's Tale: A Pilgrimage to the Dawn of EvolutionÉvaluation : 4 sur 5 étoiles4/5 (812)
- Good Without God: What a Billion Nonreligious People Do BelieveD'EverandGood Without God: What a Billion Nonreligious People Do BelieveÉvaluation : 4 sur 5 étoiles4/5 (66)
- The Other Side of Normal: How Biology Is Providing the Clues to Unlock the Secrets of Normal and Abnormal BehaviorD'EverandThe Other Side of Normal: How Biology Is Providing the Clues to Unlock the Secrets of Normal and Abnormal BehaviorPas encore d'évaluation
- Seven and a Half Lessons About the BrainD'EverandSeven and a Half Lessons About the BrainÉvaluation : 4 sur 5 étoiles4/5 (109)
- Human: The Science Behind What Makes Your Brain UniqueD'EverandHuman: The Science Behind What Makes Your Brain UniqueÉvaluation : 3.5 sur 5 étoiles3.5/5 (38)
- Lymph & Longevity: The Untapped Secret to HealthD'EverandLymph & Longevity: The Untapped Secret to HealthÉvaluation : 4.5 sur 5 étoiles4.5/5 (13)
- The Rise and Fall of the Dinosaurs: A New History of a Lost WorldD'EverandThe Rise and Fall of the Dinosaurs: A New History of a Lost WorldÉvaluation : 4 sur 5 étoiles4/5 (595)
- A Series of Fortunate Events: Chance and the Making of the Planet, Life, and YouD'EverandA Series of Fortunate Events: Chance and the Making of the Planet, Life, and YouÉvaluation : 4.5 sur 5 étoiles4.5/5 (62)
- The Consciousness Instinct: Unraveling the Mystery of How the Brain Makes the MindD'EverandThe Consciousness Instinct: Unraveling the Mystery of How the Brain Makes the MindÉvaluation : 4.5 sur 5 étoiles4.5/5 (93)
- Buddha's Brain: The Practical Neuroscience of Happiness, Love & WisdomD'EverandBuddha's Brain: The Practical Neuroscience of Happiness, Love & WisdomÉvaluation : 4 sur 5 étoiles4/5 (216)
- Wayfinding: The Science and Mystery of How Humans Navigate the WorldD'EverandWayfinding: The Science and Mystery of How Humans Navigate the WorldÉvaluation : 4.5 sur 5 étoiles4.5/5 (18)
- Moral Tribes: Emotion, Reason, and the Gap Between Us and ThemD'EverandMoral Tribes: Emotion, Reason, and the Gap Between Us and ThemÉvaluation : 4.5 sur 5 étoiles4.5/5 (115)
- Crypt: Life, Death and Disease in the Middle Ages and BeyondD'EverandCrypt: Life, Death and Disease in the Middle Ages and BeyondÉvaluation : 4 sur 5 étoiles4/5 (4)