Vous aimerez peut-être aussi
- Relational Database Design and Implementation: Clearly ExplainedD'EverandRelational Database Design and Implementation: Clearly ExplainedPas encore d'évaluation
- Term Paper Topics in Operating SystemDocument8 pagesTerm Paper Topics in Operating Systembav1dik0jal3Pas encore d'évaluation
- Managing Data in Motion: Data Integration Best Practice Techniques and TechnologiesD'EverandManaging Data in Motion: Data Integration Best Practice Techniques and TechnologiesPas encore d'évaluation
- Oracle DBADocument569 pagesOracle DBASraVanKuMarThadakamalla100% (2)
- Transaction Processing: Concepts and TechniquesD'EverandTransaction Processing: Concepts and TechniquesÉvaluation : 3.5 sur 5 étoiles3.5/5 (11)
- Introduction To Database Systems: Information Superhighway Have Become Ubiquitous, and Information Processing Is ADocument21 pagesIntroduction To Database Systems: Information Superhighway Have Become Ubiquitous, and Information Processing Is AJan Christopher Dumale DecoroPas encore d'évaluation
- Evolution of DatabaseDocument15 pagesEvolution of DatabaseKristel Jen E. RosalesPas encore d'évaluation
- Solution Manual For Database Systems Design Implementation and Management 10th EditionDocument13 pagesSolution Manual For Database Systems Design Implementation and Management 10th EditionChris Harris0% (1)
- FDT Lecture NotesDocument65 pagesFDT Lecture NotesFintan NaglePas encore d'évaluation
- DATAMADocument10 pagesDATAMAInah EspinolaPas encore d'évaluation
- Introduction To DatabasesDocument26 pagesIntroduction To DatabasesTasaddaq AliPas encore d'évaluation
- Subject: Port Information Systems and Platforms: Proposed By: Prof TaliDocument9 pagesSubject: Port Information Systems and Platforms: Proposed By: Prof TaliLanjriPas encore d'évaluation
- What Is The Purpose of A Research Paper SSD 3Document7 pagesWhat Is The Purpose of A Research Paper SSD 3orlfgcvkg100% (1)
- Title: Powerful Basic Concepts of Database System Target Population: Second Year BSCS/ICT and First Year ACT Students III - OverviewDocument6 pagesTitle: Powerful Basic Concepts of Database System Target Population: Second Year BSCS/ICT and First Year ACT Students III - OverviewArnel CuetoPas encore d'évaluation
- Dbms MBA NotesDocument125 pagesDbms MBA NotesAnoop Skaria Paul50% (2)
- Reflection (Olarve, Nicole S.)Document3 pagesReflection (Olarve, Nicole S.)NICOLE OLARVEPas encore d'évaluation
- Discovering Database Tampering Through BlockchainsDocument4 pagesDiscovering Database Tampering Through BlockchainsInternational Journal of Innovative Science and Research TechnologyPas encore d'évaluation
- To Databases: Data BasesDocument22 pagesTo Databases: Data BasesPrashant RawasPas encore d'évaluation
- Artigo - The Lowell Database Research Self AssessmentDocument9 pagesArtigo - The Lowell Database Research Self AssessmentJanniele SoaresPas encore d'évaluation
- Mis - 2Document12 pagesMis - 2SK LashariPas encore d'évaluation
- (SM) Chapter 4Document19 pages(SM) Chapter 4randomlungs121223Pas encore d'évaluation
- Concept Paper.03Document13 pagesConcept Paper.03MUNDIA ANTHONYPas encore d'évaluation
- Financial Software QuestionsDocument4 pagesFinancial Software QuestionsJ-Claude DougPas encore d'évaluation
- 2 DBFDocument40 pages2 DBFMustafa HassanPas encore d'évaluation
- Big Data NotesDocument68 pagesBig Data NotesDrKrishna Priya ChakireddyPas encore d'évaluation
- History of Database Management SystemsDocument7 pagesHistory of Database Management SystemsvinodtiwarivtPas encore d'évaluation
- Research Papers On Distributed Database SecurityDocument5 pagesResearch Papers On Distributed Database Securitywftvsutlg100% (1)
- Information Technology Thesis Introduction SampleDocument6 pagesInformation Technology Thesis Introduction SampleSomeoneToWriteMyPaperForMeNewark100% (2)
- Distributed Systems CourseworkDocument6 pagesDistributed Systems Courseworkf1vijokeheg3100% (2)
- Research Paper On Database SecurityDocument6 pagesResearch Paper On Database Securitycan8t8g5100% (1)
- Term Paper On Distributed DatabaseDocument5 pagesTerm Paper On Distributed Databaseea8m12sm100% (1)
- Database Assignment 1Document16 pagesDatabase Assignment 1Asif SyedPas encore d'évaluation
- Chapter One 1.1Document14 pagesChapter One 1.1factorialPas encore d'évaluation
- Question No.1: Assignment No. 2 GEE 303 Prelim PeriodDocument6 pagesQuestion No.1: Assignment No. 2 GEE 303 Prelim PeriodEdgar GarciaPas encore d'évaluation
- DB Managment Ch1Document4 pagesDB Managment Ch1Juan Manuel Garcia NoguesPas encore d'évaluation
- Type of Data BaseDocument7 pagesType of Data BaseMuhammad KamilPas encore d'évaluation
- Research Paper On Big Data StorageDocument7 pagesResearch Paper On Big Data Storagegwjbmbvkg100% (1)
- Fundamentals of Database System: Name: - SectionDocument21 pagesFundamentals of Database System: Name: - SectionLou-Gene Valencia100% (1)
- Research Paper On ServersDocument5 pagesResearch Paper On Serverswopugemep0h3100% (1)
- Big Data AnalyticsDocument21 pagesBig Data AnalyticsAasim SaifiPas encore d'évaluation
- Research Paper Cloud StorageDocument4 pagesResearch Paper Cloud Storagej0lemetalim2100% (1)
- Thesis Topics in Operating SystemDocument6 pagesThesis Topics in Operating Systemjessicacotterreno100% (1)
- Research Papers On Information Retrieval SystemsDocument4 pagesResearch Papers On Information Retrieval Systemsgahebak1mez2100% (1)
- Ebook Database Systems The Complete Book 2Nd Ed PDF Full Chapter PDFDocument67 pagesEbook Database Systems The Complete Book 2Nd Ed PDF Full Chapter PDFcatherine.wendt366100% (28)
- INTE 20093 - IM - Assignment1Document4 pagesINTE 20093 - IM - Assignment1Mar Kian De CastroPas encore d'évaluation
- INTE 20093 - IM - Assignment1Document4 pagesINTE 20093 - IM - Assignment1Mar Kian De CastroPas encore d'évaluation
- Data Structures and DBMS For CAD Systems - A ReviewDocument9 pagesData Structures and DBMS For CAD Systems - A ReviewseventhsensegroupPas encore d'évaluation
- What Is A File?Document10 pagesWhat Is A File?Kun XiPas encore d'évaluation
- Process Management in Operating System Research PaperDocument7 pagesProcess Management in Operating System Research Paperfvey0xan100% (1)
- DBMS Complete NotesDocument122 pagesDBMS Complete NotesRavi KiranPas encore d'évaluation
- Ministry of Education Lavin Private Institute For Computer Science Department of ComputerDocument23 pagesMinistry of Education Lavin Private Institute For Computer Science Department of ComputerHimdad MuhammadPas encore d'évaluation
- Cape Notes Unit 2 Module 1 Content 12Document42 pagesCape Notes Unit 2 Module 1 Content 12Shavane DavisPas encore d'évaluation
- William Wizner - Python For Data Science - Data Analysis and Deep Learning With Python Coding and ProgrammingDocument73 pagesWilliam Wizner - Python For Data Science - Data Analysis and Deep Learning With Python Coding and ProgrammingSergey RosenfeldPas encore d'évaluation
- List The Main Categories of DataDocument10 pagesList The Main Categories of Datasramalingam288953Pas encore d'évaluation
- 02 Introduction To DBMS (Notes) InglesDocument20 pages02 Introduction To DBMS (Notes) InglesJavier BenitoPas encore d'évaluation
- Chapter 1 - IntroductionDocument5 pagesChapter 1 - IntroductionFoveros FoveridisPas encore d'évaluation
- Dbms New NotesDocument126 pagesDbms New NotesAnkit Kumar JhaPas encore d'évaluation
- Cs6302 Dbms Notes RejinpaulDocument180 pagesCs6302 Dbms Notes Rejinpaulrewop sriPas encore d'évaluation
- Chapter 1Document57 pagesChapter 1Levale XrPas encore d'évaluation
- Sumary Cloud ComputingDocument5 pagesSumary Cloud ComputingsneiderPas encore d'évaluation
- Dbms 2 MarksDocument17 pagesDbms 2 MarksPraveen KumarPas encore d'évaluation
- Answer Any FIVE Questions All Questions Carry Equal MarksDocument8 pagesAnswer Any FIVE Questions All Questions Carry Equal MarksMahendra Nadh KoduruPas encore d'évaluation
- Physical Design & Implementation of Relational DatabaseDocument243 pagesPhysical Design & Implementation of Relational Databasesharklasers com100% (4)
- DBMS 3Document35 pagesDBMS 3haaabusharmaPas encore d'évaluation
- Concurrency Control TechniquesDocument12 pagesConcurrency Control TechniquesAman KumarPas encore d'évaluation
- Ch.1 - Introduction: Study Guide To Accompany Operating Systems Concepts 9Document7 pagesCh.1 - Introduction: Study Guide To Accompany Operating Systems Concepts 9John Fredy Redondo MoreloPas encore d'évaluation
- DBMS PPT Unit-5Document85 pagesDBMS PPT Unit-5mohisinashaik2005100% (1)
- MSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmDocument6 pagesMSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmLens NewPas encore d'évaluation
- Database Management SystemDocument120 pagesDatabase Management SystemGururaj Nadager100% (1)
- NewsDocument106 pagesNewsBojan TodorovićPas encore d'évaluation
- XML Web Services and Interview QuestionsDocument88 pagesXML Web Services and Interview QuestionsNavi BharatPas encore d'évaluation
- Linux Device Driver DevelopmentDocument647 pagesLinux Device Driver Developmentobsey jackson100% (1)
- Function Distributed Database Management SystemsDocument7 pagesFunction Distributed Database Management SystemsAqab ButtPas encore d'évaluation
- SantaDocument7 pagesSantanickbentonPas encore d'évaluation
- Chapter 7: Process SynchronizationDocument62 pagesChapter 7: Process SynchronizationShanmugapriyaVinodkumarPas encore d'évaluation
- Posix Api PDFDocument43 pagesPosix Api PDFthebboymp3Pas encore d'évaluation
- Oracle Table Lock ModesDocument10 pagesOracle Table Lock ModesFranck PachotPas encore d'évaluation
- Chapter 1 Introduction PDFDocument77 pagesChapter 1 Introduction PDFDeepBhaleraoPas encore d'évaluation
- Programmers GuideDocument173 pagesProgrammers GuideMaico LubawskiPas encore d'évaluation
- Race ConditionsDocument13 pagesRace ConditionsZxcpoiPas encore d'évaluation
- Esd 1Document40 pagesEsd 1154Soyal LonarePas encore d'évaluation
- Btrieve Record Manager Error CodesDocument22 pagesBtrieve Record Manager Error CodesAlejandro Azálgara NeiraPas encore d'évaluation
- OS Chap 5 SlidesDocument82 pagesOS Chap 5 SlidesQasimPas encore d'évaluation
- Dbms (Unit 3,4,5)Document38 pagesDbms (Unit 3,4,5)adaPas encore d'évaluation
- Threads NotesDocument34 pagesThreads NotesPoornimaRachirajuPas encore d'évaluation
- Database Management System, (CS-2004), Spring Semester Examination 2021Document14 pagesDatabase Management System, (CS-2004), Spring Semester Examination 2021shivamjana40Pas encore d'évaluation
- (Oracle SQL) Database-Development-GuideDocument780 pages(Oracle SQL) Database-Development-GuideIsrael LucasPas encore d'évaluation
- Oracle Performance Diagnostic Guide (Version 3.20) Hang/LockingDocument51 pagesOracle Performance Diagnostic Guide (Version 3.20) Hang/LockingdmdunlapPas encore d'évaluation
- How To Guide Business Object Layer Programming PDFDocument48 pagesHow To Guide Business Object Layer Programming PDFrodandosinhumosPas encore d'évaluation
- DBMS - GTU - Asked - Ques - Unit WiseDocument16 pagesDBMS - GTU - Asked - Ques - Unit WiseShiv PatelPas encore d'évaluation
- A Joosr Guide to... What Color is Your Parachute? 2016 by Richard Bolles: A Practical Manual for Job-Hunters and Career-ChangersD'EverandA Joosr Guide to... What Color is Your Parachute? 2016 by Richard Bolles: A Practical Manual for Job-Hunters and Career-ChangersÉvaluation : 4 sur 5 étoiles4/5 (1)
- Get That Job! The Quick and Complete Guide to a Winning InterviewD'EverandGet That Job! The Quick and Complete Guide to a Winning InterviewÉvaluation : 4.5 sur 5 étoiles4.5/5 (15)
- Job Interview: How to Talk about Weaknesses, Yourself, and Other Questions and AnswersD'EverandJob Interview: How to Talk about Weaknesses, Yourself, and Other Questions and AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (15)
- Consulting Interview: How to Respond to TOP 28 Personal Experience Interview QuestionsD'EverandConsulting Interview: How to Respond to TOP 28 Personal Experience Interview QuestionsÉvaluation : 5 sur 5 étoiles5/5 (3)
- Job Interview: The Complete Job Interview Preparation and 70 Tough Job Interview Questions with Winning AnswersD'EverandJob Interview: The Complete Job Interview Preparation and 70 Tough Job Interview Questions with Winning AnswersÉvaluation : 4 sur 5 étoiles4/5 (7)
- How to Be Everything: A Guide for Those Who (Still) Don't Know What They Want to Be When They Grow UpD'EverandHow to Be Everything: A Guide for Those Who (Still) Don't Know What They Want to Be When They Grow UpÉvaluation : 4 sur 5 étoiles4/5 (74)
- The Science of Rapid Skill Acquisition: Advanced Methods to Learn, Remember, and Master New Skills and Information [Second Edition]D'EverandThe Science of Rapid Skill Acquisition: Advanced Methods to Learn, Remember, and Master New Skills and Information [Second Edition]Évaluation : 4.5 sur 5 étoiles4.5/5 (23)
- 101 Great Answers to the Toughest Interview QuestionsD'Everand101 Great Answers to the Toughest Interview QuestionsÉvaluation : 3.5 sur 5 étoiles3.5/5 (29)
- Job Interview: Outfits, Questions and Answers You Should Know aboutD'EverandJob Interview: Outfits, Questions and Answers You Should Know aboutÉvaluation : 5 sur 5 étoiles5/5 (4)
- SQL CODING FOR BEGINNERS: Step-by-Step Beginner's Guide to Mastering SQL Programming and Coding (2022 Crash Course for Newbies)D'EverandSQL CODING FOR BEGINNERS: Step-by-Step Beginner's Guide to Mastering SQL Programming and Coding (2022 Crash Course for Newbies)Pas encore d'évaluation
- Unbeatable Resumes: America's Top Recruiter Reveals What REALLY Gets You HiredD'EverandUnbeatable Resumes: America's Top Recruiter Reveals What REALLY Gets You HiredÉvaluation : 5 sur 5 étoiles5/5 (2)
- Switchers: How Smart Professionals Change Careers - and Seize SuccessD'EverandSwitchers: How Smart Professionals Change Careers - and Seize SuccessÉvaluation : 5 sur 5 étoiles5/5 (2)
- Getting Back in the Game: How to Build Your Resume After Taking a BreakD'EverandGetting Back in the Game: How to Build Your Resume After Taking a BreakÉvaluation : 4.5 sur 5 étoiles4.5/5 (3)
- Cyber Security for Beginners: How to Become a Cybersecurity Professional Without a Technical Background (2022 Guide for Newbies)D'EverandCyber Security for Beginners: How to Become a Cybersecurity Professional Without a Technical Background (2022 Guide for Newbies)Pas encore d'évaluation
- Finding Your Passion: 33 Strategies for Finding, Growing and Keeping Your Dream Job While Avoiding Stress BurnoutD'EverandFinding Your Passion: 33 Strategies for Finding, Growing and Keeping Your Dream Job While Avoiding Stress BurnoutÉvaluation : 3.5 sur 5 étoiles3.5/5 (2)
- The Resume and Cover Letter Phrase Book: What to Write to Get the Job That's RightD'EverandThe Resume and Cover Letter Phrase Book: What to Write to Get the Job That's RightÉvaluation : 4 sur 5 étoiles4/5 (9)
- Amazon Interview Secrets: How to Respond to 101 Popular Amazon Leadership Principles Interview QuestionsD'EverandAmazon Interview Secrets: How to Respond to 101 Popular Amazon Leadership Principles Interview QuestionsÉvaluation : 5 sur 5 étoiles5/5 (4)
- Online Personal Brand: Skill Set, Aura, and IdentityD'EverandOnline Personal Brand: Skill Set, Aura, and IdentityÉvaluation : 3 sur 5 étoiles3/5 (1)
- Building a Great LinkedIn Profile: A Step-by-Step Guide to Make a Standout Profile PageD'EverandBuilding a Great LinkedIn Profile: A Step-by-Step Guide to Make a Standout Profile PagePas encore d'évaluation
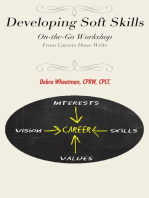
- Developing Soft Skills: An On-the-Go WorkshopD'EverandDeveloping Soft Skills: An On-the-Go WorkshopÉvaluation : 4 sur 5 étoiles4/5 (7)
- Developing a Program of Research: An Essential Process for a Successful Research CareerD'EverandDeveloping a Program of Research: An Essential Process for a Successful Research CareerPas encore d'évaluation
- The Power of STAR Method: How to Succeed at Behavioral Job InterviewD'EverandThe Power of STAR Method: How to Succeed at Behavioral Job InterviewPas encore d'évaluation
- Taking Charge of Your Career: The Essential Guide to Finding the Job That's Right for YouD'EverandTaking Charge of Your Career: The Essential Guide to Finding the Job That's Right for YouPas encore d'évaluation
- The Complete Remote Work Guide: 100+ Reliable Jobs, Gigs and Careers You Can Do Anywhere, AnytimeD'EverandThe Complete Remote Work Guide: 100+ Reliable Jobs, Gigs and Careers You Can Do Anywhere, AnytimePas encore d'évaluation
- The Medical Science Liaison Career Guide: How to Break Into Your First RoleD'EverandThe Medical Science Liaison Career Guide: How to Break Into Your First RolePas encore d'évaluation
- Job Interview: The Most Common Questions and Answers during a Job ApplicationD'EverandJob Interview: The Most Common Questions and Answers during a Job ApplicationÉvaluation : 5 sur 5 étoiles5/5 (7)






























































































![The Science of Rapid Skill Acquisition: Advanced Methods to Learn, Remember, and Master New Skills and Information [Second Edition]](https://imgv2-2-f.scribdassets.com/img/word_document/419715394/149x198/b9c2899614/1683669291?v=1)