Vous aimerez peut-être aussi
- Minimal Residual Disease Testing: Current Innovations and Future DirectionsD'EverandMinimal Residual Disease Testing: Current Innovations and Future DirectionsTodd E. DruleyPas encore d'évaluation
- Modern Analytical TechniquesDocument5 pagesModern Analytical TechniquesRia SinghPas encore d'évaluation
- FishDocument17 pagesFishnagendraPas encore d'évaluation
- QuarterlyRevBiophys PDFDocument33 pagesQuarterlyRevBiophys PDFHenryPas encore d'évaluation
- An Evaluation of Terminal Restriction Fragment Length Polymorphsim Analysis For The Study of Microbial Community Structure and DynamicsDocument12 pagesAn Evaluation of Terminal Restriction Fragment Length Polymorphsim Analysis For The Study of Microbial Community Structure and DynamicsWilmer HerreraPas encore d'évaluation
- A Review of DNA Sequencing Techniques: Lilian T. C. Franc: A, Emanuel Carrilho and Tarso B. L. KistDocument32 pagesA Review of DNA Sequencing Techniques: Lilian T. C. Franc: A, Emanuel Carrilho and Tarso B. L. KistAnkit NarulaPas encore d'évaluation
- B Rsting Morling 2015Document12 pagesB Rsting Morling 2015Sofia MoreiraPas encore d'évaluation
- A Rapid CTAB DNA IsolationDocument6 pagesA Rapid CTAB DNA Isolationwaheed639Pas encore d'évaluation
- New Haplotypes of Black-Bearded Tomb Bat (Taphozous Melanopogon) From Puncakwangi Cave (East Java, Indonesia)Document5 pagesNew Haplotypes of Black-Bearded Tomb Bat (Taphozous Melanopogon) From Puncakwangi Cave (East Java, Indonesia)bambang awanPas encore d'évaluation
- Jurnal RFLP PDFDocument8 pagesJurnal RFLP PDFSilvia ZahiraPas encore d'évaluation
- Please, Some Vocabulary No Need To Change Like (Purification, SynthesisDocument6 pagesPlease, Some Vocabulary No Need To Change Like (Purification, SynthesisasdefencePas encore d'évaluation
- Allele Frequencies of Six MiniSTR Loci in The Population of Northern PortugalDocument3 pagesAllele Frequencies of Six MiniSTR Loci in The Population of Northern PortugalspanishvcuPas encore d'évaluation
- DNA Barcoding, Amplification, and Sequencing Lab ReportDocument12 pagesDNA Barcoding, Amplification, and Sequencing Lab ReportRichie JustinPas encore d'évaluation
- tmpCF4 TMPDocument13 pagestmpCF4 TMPFrontiersPas encore d'évaluation
- A Review On SNP and Other Types of Molecular Markers and Their Use in Animal GeneticsDocument31 pagesA Review On SNP and Other Types of Molecular Markers and Their Use in Animal GeneticsboboyoyotPas encore d'évaluation
- Genomics and BioinformaticsDocument17 pagesGenomics and BioinformaticsgoswamiphotostatPas encore d'évaluation
- PNAS 2016 Stranges 1608271113Document44 pagesPNAS 2016 Stranges 1608271113rupindersayalPas encore d'évaluation
- Molecular Diagnostics: Past, Present, and Future: Table 1.1Document11 pagesMolecular Diagnostics: Past, Present, and Future: Table 1.1Guillərmo MorɐləsPas encore d'évaluation
- A Bumpy Ride On The Diagnostic Bench of Massive Parallel Sequencing, The Case of The Mitochondrial GenomeDocument9 pagesA Bumpy Ride On The Diagnostic Bench of Massive Parallel Sequencing, The Case of The Mitochondrial GenomeMayra EduardoffPas encore d'évaluation
- Tools and Approaches in Eukaryotic Microbial EcologyDocument15 pagesTools and Approaches in Eukaryotic Microbial EcologyVikas DhimanPas encore d'évaluation
- Universiti Malaysia Sabah Faculty of Science and Human Resources Hgo7 BiotechnologyDocument9 pagesUniversiti Malaysia Sabah Faculty of Science and Human Resources Hgo7 BiotechnologyShalini MuthuPas encore d'évaluation
- Molecular Genetic Techniques and Markers For Ecological ResearchDocument8 pagesMolecular Genetic Techniques and Markers For Ecological ResearchSlayerPas encore d'évaluation
- 1 Part2Document13 pages1 Part2Ali AFadelPas encore d'évaluation
- Review On Molecular Diagnostic ToolsDocument10 pagesReview On Molecular Diagnostic ToolsAdelyna AndreiPas encore d'évaluation
- A Comparison of RpoB and 16S RRNA As Markers in Pyrosequencing Studies of Bacterial DiversityDocument8 pagesA Comparison of RpoB and 16S RRNA As Markers in Pyrosequencing Studies of Bacterial DiversityutpalmtbiPas encore d'évaluation
- MicrotoxDocument7 pagesMicrotoxtexto.sarlPas encore d'évaluation
- gmr692 HDocument10 pagesgmr692 HnormanwillowPas encore d'évaluation
- Odriozola - Development and Validationof I-DNA1 - A 15-Loci Multiplex System For Identity TestingDocument10 pagesOdriozola - Development and Validationof I-DNA1 - A 15-Loci Multiplex System For Identity TestingspanishvcuPas encore d'évaluation
- Aplicaciones de DPCRDocument9 pagesAplicaciones de DPCRAmba RioshopPas encore d'évaluation
- A Simple Method For Isolation of Dna From Plants Suitable For Long Term Storage and Dna Marker AnalysisDocument7 pagesA Simple Method For Isolation of Dna From Plants Suitable For Long Term Storage and Dna Marker AnalysisNavanith Agriculture DeptPas encore d'évaluation
- SBB 0608Document6 pagesSBB 0608JessicaPas encore d'évaluation
- Thesis PCRDocument8 pagesThesis PCRgjfs5mtv100% (2)
- Genetic FingerprintingDocument10 pagesGenetic FingerprintingRichar Manuel Simanca FontalvoPas encore d'évaluation
- Indonesian Journal of BiotechnologyDocument6 pagesIndonesian Journal of Biotechnologyandi reskiPas encore d'évaluation
- DNA FingerprintingDocument20 pagesDNA FingerprintingprayaasplbPas encore d'évaluation
- 1 s2.0 S0014480003000248 MainDocument5 pages1 s2.0 S0014480003000248 MainEhsan HumayunPas encore d'évaluation
- Methods To Study Soil Microbial DiversityDocument25 pagesMethods To Study Soil Microbial Diversityrd2165scribdPas encore d'évaluation
- 2032Document10 pages2032punishPas encore d'évaluation
- PHD Thesis On Dna BarcodingDocument5 pagesPHD Thesis On Dna BarcodingStephen Faucher100% (2)
- Koo Ken 2014Document7 pagesKoo Ken 2014Perla Andrea Urriola AraosPas encore d'évaluation
- Molecular Markers in Forest Management and Tree Breeding: A ReviewDocument7 pagesMolecular Markers in Forest Management and Tree Breeding: A ReviewFernando Castro EchavezPas encore d'évaluation
- Synthesis and Characterization ofDocument17 pagesSynthesis and Characterization ofDiaa OsmanPas encore d'évaluation
- Research Paper On Dna MicroarrayDocument7 pagesResearch Paper On Dna Microarrayafnhbijlzdufjj100% (1)
- DNA & Forensic ScienceDocument5 pagesDNA & Forensic Sciencecarygrant_2003Pas encore d'évaluation
- B.tech. Biotechnology NotesDocument14 pagesB.tech. Biotechnology NotesMudit MisraPas encore d'évaluation
- Molecular Markers in Plant Genome AnalysisDocument13 pagesMolecular Markers in Plant Genome Analysisarunnene2Pas encore d'évaluation
- A Quick and Simple FISH Protocol With Hybridization-Sensitive Fluorescent Linear Oligodeoxynucleotide ProbesDocument10 pagesA Quick and Simple FISH Protocol With Hybridization-Sensitive Fluorescent Linear Oligodeoxynucleotide ProbesNidhi JaisPas encore d'évaluation
- Bot491 05Document5 pagesBot491 05asdfagPas encore d'évaluation
- Research: Loop-Mediated Isothermal Amplification For The Detection of Tylenchulus Semipenetrans in SoilDocument7 pagesResearch: Loop-Mediated Isothermal Amplification For The Detection of Tylenchulus Semipenetrans in SoilHalisa IndrianiPas encore d'évaluation
- Desviat 2006 CcaDocument4 pagesDesviat 2006 Ccarahmawati aliwarmanPas encore d'évaluation
- Dna Chip Technologies: Seung Yong Hwang and Geunbae LimDocument5 pagesDna Chip Technologies: Seung Yong Hwang and Geunbae LimPulkit ShrivastavaPas encore d'évaluation
- Next-Generation DNA Barcoding: Using Next-Generation Sequencing To Enhance and Accelerate DNA Barcode Capture From Single SpecimensDocument10 pagesNext-Generation DNA Barcoding: Using Next-Generation Sequencing To Enhance and Accelerate DNA Barcode Capture From Single SpecimensarisPas encore d'évaluation
- Ensayo GenéticoDocument6 pagesEnsayo Genéticoewbqyj94100% (1)
- Genomic Report MRIN 2015Document15 pagesGenomic Report MRIN 2015Jessica AdhykaPas encore d'évaluation
- Exploring Bacterial Diversity of Endodontic Microbiota by Cloning and Sequencing 16S rRNADocument5 pagesExploring Bacterial Diversity of Endodontic Microbiota by Cloning and Sequencing 16S rRNAfaustorvPas encore d'évaluation
- Lab Assignment 371Document9 pagesLab Assignment 371khanyiso kalyataPas encore d'évaluation
- Visualization of FISH Probes by Dual-Color Chromogenic in Situ HybridizationDocument7 pagesVisualization of FISH Probes by Dual-Color Chromogenic in Situ HybridizationNidhi JaisPas encore d'évaluation
- 1516260242FSC P13 M13 E-Text PDFDocument10 pages1516260242FSC P13 M13 E-Text PDFKanchanPas encore d'évaluation
- Schena EJPP2004Document16 pagesSchena EJPP2004Mini Bekti NingsihPas encore d'évaluation
- Nanotechnology in Forensic Toxicology: How The Little Guys Are Giving Us The Big PictureDocument14 pagesNanotechnology in Forensic Toxicology: How The Little Guys Are Giving Us The Big PictureVickie KapPas encore d'évaluation
- Grounds of Divorce Under Hindu Religion or Hindu Law Unit-A: Chapter-IiDocument42 pagesGrounds of Divorce Under Hindu Religion or Hindu Law Unit-A: Chapter-IiSatyam PathakPas encore d'évaluation
- DSM-5 Personality Disorders PDFDocument2 pagesDSM-5 Personality Disorders PDFIqbal Baryar0% (1)
- Soil Chapter 3Document67 pagesSoil Chapter 3Jethrone MichealaPas encore d'évaluation
- Sports MedicineDocument2 pagesSports MedicineShelby HooklynPas encore d'évaluation
- Seven-Year Financial Pro Jection: ProblemDocument10 pagesSeven-Year Financial Pro Jection: Problemnyashadzashe munyatiPas encore d'évaluation
- VOC & CO - EnglishDocument50 pagesVOC & CO - EnglishAnandKumarPPas encore d'évaluation
- Birla Institute of Management and Technology (Bimtech) : M.A.C CosmeticsDocument9 pagesBirla Institute of Management and Technology (Bimtech) : M.A.C CosmeticsShubhda SharmaPas encore d'évaluation
- The Superhero LifestyleDocument9 pagesThe Superhero LifestyleDerp Blood0% (3)
- DIAC Experienced Associate HealthcareDocument3 pagesDIAC Experienced Associate HealthcarecompangelPas encore d'évaluation
- Wago PCB Terminal Blocks and Connectors Catalog 7Document105 pagesWago PCB Terminal Blocks and Connectors Catalog 7alinupPas encore d'évaluation
- Select Event Venue and SiteDocument11 pagesSelect Event Venue and SiteLloyd Arnold Catabona100% (1)
- Kern County Sues Governor Gavin NewsomDocument3 pagesKern County Sues Governor Gavin NewsomAnthony Wright100% (1)
- TDS Shell Spirax s6 Gxme 75w-80Document2 pagesTDS Shell Spirax s6 Gxme 75w-80rstec pyPas encore d'évaluation
- Post Traumatic Stress DisorderDocument2 pagesPost Traumatic Stress Disorderapi-188978784100% (1)
- Practice Problems Mat Bal With RXNDocument4 pagesPractice Problems Mat Bal With RXNRugi Vicente RubiPas encore d'évaluation
- TFALL CaseStudy-Chandni+Chopra 072020+Document5 pagesTFALL CaseStudy-Chandni+Chopra 072020+Luis Gustavo Heredia VasquezPas encore d'évaluation
- CPhI Japan InformationDocument22 pagesCPhI Japan InformationctyvtePas encore d'évaluation
- Ransport and Installation Instructions CTX 510 EcoDocument32 pagesRansport and Installation Instructions CTX 510 EcoMiliano FilhoPas encore d'évaluation
- CH 13 RNA and Protein SynthesisDocument12 pagesCH 13 RNA and Protein SynthesisHannah50% (2)
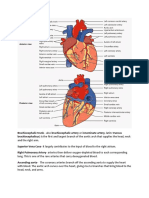
- Brachiocephalic TrunkDocument3 pagesBrachiocephalic TrunkstephPas encore d'évaluation
- Traditional vs. Enterprise Risk Management - How Do They DifferDocument4 pagesTraditional vs. Enterprise Risk Management - How Do They DifferJaveed A. KhanPas encore d'évaluation
- Toaz - Info Fermentation of Carrot Juice Wheat Flour Gram Flour Etc PRDocument17 pagesToaz - Info Fermentation of Carrot Juice Wheat Flour Gram Flour Etc PRBhumika SahuPas encore d'évaluation
- TelfastDocument3 pagesTelfastjbahalkehPas encore d'évaluation
- Module 2: Environmental Science: EcosystemDocument8 pagesModule 2: Environmental Science: EcosystemHanna Dia MalatePas encore d'évaluation
- ME-317 Internal Combustion Engines - TurbochargingDocument21 pagesME-317 Internal Combustion Engines - TurbochargingHamzaJavedPas encore d'évaluation
- Week 1 Seismic WavesDocument30 pagesWeek 1 Seismic WavesvriannaPas encore d'évaluation
- Ecg Quick Guide PDFDocument7 pagesEcg Quick Guide PDFansarijavedPas encore d'évaluation
- Cooling SistemadeRefrigeracion RefroidissementDocument124 pagesCooling SistemadeRefrigeracion RefroidissementPacoPas encore d'évaluation
- Grain Silo Storage SizesDocument8 pagesGrain Silo Storage SizesTyler HallPas encore d'évaluation
- A I R P O R T S Construction Program Management 56Document56 pagesA I R P O R T S Construction Program Management 56Carl WilliamsPas encore d'évaluation