Vous aimerez peut-être aussi
- Mejorar Consultas SQLDocument8 pagesMejorar Consultas SQLmoratalaz001Pas encore d'évaluation
- Mejorar El Rendimiento de QUERIES en SQL ServerDocument11 pagesMejorar El Rendimiento de QUERIES en SQL ServerVictor VidalPas encore d'évaluation
- Mejorar El Rendimiento de QUERIES en SQL ServerDocument13 pagesMejorar El Rendimiento de QUERIES en SQL ServerChristian AcostaPas encore d'évaluation
- Mejorar El Rendimiento de QUERIES en SQL ServerDocument11 pagesMejorar El Rendimiento de QUERIES en SQL ServermaxiPas encore d'évaluation
- Optimizacion de Consultas SQL ServerDocument30 pagesOptimizacion de Consultas SQL ServerliorcsPas encore d'évaluation
- Optimización de consultas SQLDocument17 pagesOptimización de consultas SQLJulio Cesar ChavarroPas encore d'évaluation
- Optimización Consultas OracleDocument6 pagesOptimización Consultas OracleR Martin Martin100% (4)
- Investigacion Base de DatosDocument25 pagesInvestigacion Base de DatosKarin Nathalí Argueta100% (1)
- Mejores PRÁCTICAS de DesarrolloDocument7 pagesMejores PRÁCTICAS de DesarrolloVerónica Leos PlataPas encore d'évaluation
- Funcion Escalar y TabularDocument8 pagesFuncion Escalar y TabularGabriel SatornicioPas encore d'évaluation
- Consejos para Crear y Optimizar Consultas en SQLDocument3 pagesConsejos para Crear y Optimizar Consultas en SQLErika GyvPas encore d'évaluation
- Guia SQLDocument13 pagesGuia SQLAnthony CamposPas encore d'évaluation
- Trabajo Escrito 1Document15 pagesTrabajo Escrito 1Hernandez Lara Carlos ManuelPas encore d'évaluation
- Chavez Zarabia GuiasDocument9 pagesChavez Zarabia GuiasEliazar Vigoria OyolaPas encore d'évaluation
- Consultas Avanzadas en SQLDocument4 pagesConsultas Avanzadas en SQLWendy Valeria Hernandez RiosPas encore d'évaluation
- Subconsultas en El Lenguaje SQLDocument9 pagesSubconsultas en El Lenguaje SQLDianitaPrincesPas encore d'évaluation
- Buenas Prácticas en SQL QueryDocument30 pagesBuenas Prácticas en SQL QueryLuis Samuel Ramirez ApontePas encore d'évaluation
- Guiassql PDFDocument7 pagesGuiassql PDFAmanda GarciaPas encore d'évaluation
- Fundamentos de SQL EJEMPLOSDocument33 pagesFundamentos de SQL EJEMPLOScintya100% (1)
- Buenas Prácticas en La Construcción de Consultas SQLDocument2 pagesBuenas Prácticas en La Construcción de Consultas SQLGonzalo MoncadaPas encore d'évaluation
- SQL Access: conceptos básicos, vocabulario y sintaxisDocument37 pagesSQL Access: conceptos básicos, vocabulario y sintaxisAlejandro Gonzalez GarciaPas encore d'évaluation
- Optimización Básica de SQLDocument6 pagesOptimización Básica de SQLJeffrey MolinaPas encore d'évaluation
- Cap-8 Uso de SubconsultasDocument25 pagesCap-8 Uso de SubconsultasViktor CarranzaPas encore d'évaluation
- Optimizacion de Consultas SQLDocument9 pagesOptimizacion de Consultas SQLwilliamPas encore d'évaluation
- Tecnicas de Diseno y Programacion de Aplicaciones Contra Bases de Datos OracleDocument19 pagesTecnicas de Diseno y Programacion de Aplicaciones Contra Bases de Datos Oraclejrengifo27Pas encore d'évaluation
- Manual Buenas Prácticas Codificación SQL ServerDocument8 pagesManual Buenas Prácticas Codificación SQL ServerErick MaxPas encore d'évaluation
- Manejo de SubconsultasDocument13 pagesManejo de SubconsultaslissetPas encore d'évaluation
- Guia 5Document14 pagesGuia 5Omar MecaPas encore d'évaluation
- SQL PlusDocument34 pagesSQL PlusLuis Alejandro Curay ValdiviezoPas encore d'évaluation
- 014 - Técnicas de Optimización de Consultas en SQL ServerDocument2 pages014 - Técnicas de Optimización de Consultas en SQL ServerKeith Arciniegas BarcoPas encore d'évaluation
- Optimizacion SQL AvanzadoDocument28 pagesOptimizacion SQL AvanzadomplagarrPas encore d'évaluation
- 6E 2.2 DiapositivasDocument15 pages6E 2.2 DiapositivasJuan IgnacioPas encore d'évaluation
- PostgreSQL - Conceptos BásicosDocument30 pagesPostgreSQL - Conceptos BásicosYessenia LarcoPas encore d'évaluation
- Informe COMANDOS SQLDocument10 pagesInforme COMANDOS SQLDanny CarrascoPas encore d'évaluation
- Indices en Base de DatosDocument15 pagesIndices en Base de DatosPaloPas encore d'évaluation
- SQL en Access 1 Consultas SeleccionDocument53 pagesSQL en Access 1 Consultas SeleccionRonald MojicaPas encore d'évaluation
- Entender El Plan de Ejecución en SQL ServerDocument7 pagesEntender El Plan de Ejecución en SQL Serveradriana_e_sosaPas encore d'évaluation
- BD05. - Realización de ConsultasDocument50 pagesBD05. - Realización de ConsultasKuki DogPas encore d'évaluation
- Consultas de SeleccionDocument53 pagesConsultas de SeleccionestefanyPas encore d'évaluation
- Ernesto Cuenca PRACTICA Nº5Document12 pagesErnesto Cuenca PRACTICA Nº5Jose Alejandro AliagaPas encore d'évaluation
- Manual SQL ServerDocument32 pagesManual SQL ServerJOSESTONEVPas encore d'évaluation
- 15 Consejos para Optimizar Nuestras Consultas SQLDocument5 pages15 Consejos para Optimizar Nuestras Consultas SQLgaryiiPas encore d'évaluation
- Introduccion A MysqlDocument5 pagesIntroduccion A MysqlyeismirPas encore d'évaluation
- Ensayo SQL For Data ScienceDocument3 pagesEnsayo SQL For Data ScienceCarlozSanchezOPas encore d'évaluation
- Optimización de La Base Datos PDFDocument7 pagesOptimización de La Base Datos PDFJOSE LUIS BANDERAS HERRERAPas encore d'évaluation
- Optimización de La Base Datos PDFDocument7 pagesOptimización de La Base Datos PDFJOSE LUIS BANDERAS HERRERAPas encore d'évaluation
- Tablas dinámicas para todos. Desde simples tablas hasta Power-Pivot: Guía útil para crear tablas dinámicas en ExcelD'EverandTablas dinámicas para todos. Desde simples tablas hasta Power-Pivot: Guía útil para crear tablas dinámicas en ExcelPas encore d'évaluation
- Tablas dinámicas y Gráficas para Excel: Una guía visual paso a pasoD'EverandTablas dinámicas y Gráficas para Excel: Una guía visual paso a pasoPas encore d'évaluation
- Introducción Excel: FUNCIONES ESENCIALES PARA PRINCIPIANTES: Microsoft Excel Principiantes, #1D'EverandIntroducción Excel: FUNCIONES ESENCIALES PARA PRINCIPIANTES: Microsoft Excel Principiantes, #1Pas encore d'évaluation
- Examen Profesional Certificado de Nube AWS Guía de éxito 1: Examen Profesional Certificado de Nube AWS Guía de Éxito, #1D'EverandExamen Profesional Certificado de Nube AWS Guía de éxito 1: Examen Profesional Certificado de Nube AWS Guía de Éxito, #1Pas encore d'évaluation
- Modelado y simulación de redes. Aplicación de QoS con opnet modelerD'EverandModelado y simulación de redes. Aplicación de QoS con opnet modelerPas encore d'évaluation
- UF1884 - Almacenamiento de datos en sistemas ERP-CRMD'EverandUF1884 - Almacenamiento de datos en sistemas ERP-CRMPas encore d'évaluation
- Examen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2D'EverandExamen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2Pas encore d'évaluation
- Conexión SQL SERVER & C# (Manual para principiantes)D'EverandConexión SQL SERVER & C# (Manual para principiantes)Évaluation : 1 sur 5 étoiles1/5 (1)
- AngularJS: Conviértete en el profesional que las compañías de software necesitan.D'EverandAngularJS: Conviértete en el profesional que las compañías de software necesitan.Évaluation : 3.5 sur 5 étoiles3.5/5 (3)
- Ridge RacerDocument7 pagesRidge Racerkarla GarciaPas encore d'évaluation
- El Origen Del HombreDocument25 pagesEl Origen Del HombreDani MedianochePas encore d'évaluation
- Ciberseguridad Eje 3Document6 pagesCiberseguridad Eje 3Juan Rendon AguirrePas encore d'évaluation
- Taller 1 Mecanica de FluidosDocument3 pagesTaller 1 Mecanica de Fluidosjasmin romoPas encore d'évaluation
- "Panorama Laboral para Los Jóvenes PDFDocument54 pages"Panorama Laboral para Los Jóvenes PDFRosaEQuintanaPas encore d'évaluation
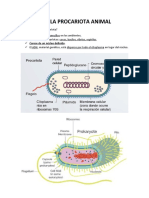
- CÉLULA PROCARIOTA y Eucariota ANIMALDocument4 pagesCÉLULA PROCARIOTA y Eucariota ANIMALMelisa Mtz. Quijano.Pas encore d'évaluation
- Análisis Del Campo Laboral Del Psicólogo EducativoDocument6 pagesAnálisis Del Campo Laboral Del Psicólogo EducativoLiliana Bolaños CarrilloPas encore d'évaluation
- #2 CalibraciónDocument34 pages#2 Calibraciónjose ivan carvajal cortizosPas encore d'évaluation
- Yesenia Segura Semana 7Document4 pagesYesenia Segura Semana 7Yesenia SeguraPas encore d'évaluation
- Estructura y Desarrollo Del CuentoDocument14 pagesEstructura y Desarrollo Del CuentoManzanas TraigoPas encore d'évaluation
- Guia El CuentoDocument4 pagesGuia El Cuentolilia puentes vergel100% (1)
- Mapa Conceptual Seguridad-1Document3 pagesMapa Conceptual Seguridad-1Eduardo Sanchez AquinoPas encore d'évaluation
- Marketing digital para prevenir enfermedades por rayos UVDocument1 pageMarketing digital para prevenir enfermedades por rayos UVFabian RamirezPas encore d'évaluation
- 1.1 Conceptos Básicos de Estadística DescriptivaDocument33 pages1.1 Conceptos Básicos de Estadística DescriptivaCalixto Huaman SotomayorPas encore d'évaluation
- Pistas para esquiarDocument14 pagesPistas para esquiarKarinaPas encore d'évaluation
- Solu Eva 01 - Gestión AmbientalDocument5 pagesSolu Eva 01 - Gestión AmbientalPedro Jorge Miguel Montoya MoralesPas encore d'évaluation
- Criminalidad en Zonas MetropolitanasDocument5 pagesCriminalidad en Zonas MetropolitanasJacobo Herrera RodríguezPas encore d'évaluation
- Procter & Gamble - Las Cinco Preguntas Esenciales de Toda Estrategia Ganadora PDFDocument9 pagesProcter & Gamble - Las Cinco Preguntas Esenciales de Toda Estrategia Ganadora PDFLaura Torrws100% (1)
- Estudiantes destacados en ingeniería y agronomíaDocument7 pagesEstudiantes destacados en ingeniería y agronomíaB123Pas encore d'évaluation
- Glosario Ambiental BásicoDocument9 pagesGlosario Ambiental BásicoAlex BravoPas encore d'évaluation
- Clasificación de InventariosDocument7 pagesClasificación de InventariosAlexander MedinaPas encore d'évaluation
- Actividad 2Document5 pagesActividad 2paola toledoPas encore d'évaluation
- Ejercicios 1 2 y 3 Letra BDocument3 pagesEjercicios 1 2 y 3 Letra Bchristian muñozPas encore d'évaluation
- Bitácora 1Document2 pagesBitácora 1Luis E. MoraPas encore d'évaluation
- Examen Final - Semana 8 - INV - PRIMER BLOQUE-PEDAGOGIA DEL MOVIMIENTO - (GRUPO1)Document11 pagesExamen Final - Semana 8 - INV - PRIMER BLOQUE-PEDAGOGIA DEL MOVIMIENTO - (GRUPO1)Fernanda0% (1)
- Examen Diagnóstico MatematicasDocument2 pagesExamen Diagnóstico MatematicasJose FregosoPas encore d'évaluation
- Redes ElectricasDocument25 pagesRedes Electricasccmolina77100% (7)
- Qüestionari D'estils de RespostaDocument1 pageQüestionari D'estils de RespostaMireiaPas encore d'évaluation
- Taller de Literatura 4° Medio 2020 - 1Document6 pagesTaller de Literatura 4° Medio 2020 - 1Shirley Flores OlivarezPas encore d'évaluation
- Evolucion Del Hombre (Larga)Document12 pagesEvolucion Del Hombre (Larga)Naya ParedesPas encore d'évaluation